
Phần mềm mới phát hiện hàng loạt lỗi "copy-paste" trong các tập dữ liệu khoa học
Một công cụ phần mềm tự động đã phát hiện ra hàng loạt lỗi sao chép dữ liệu nghiêm trọng trong các nghiên cứu khoa học uy tín, bao gồm cả bài báo mang tính bước ngoặt về bệnh Parkinson. Kết quả sơ bộ cho thấy khoảng 3% các tập dữ liệu công khai chứa các lỗi này, đặt ra câu hỏi lớn về tính toàn vẹn của dữ liệu và quy trình kiểm duyệt hiện tại.
Trong kỷ nguyên dữ liệu lớn, tính chính xác của thông tin là nền tảng của khoa học. Tuy nhiên, một dự án phần mềm mới đây đã hé lộ một thực tế đáng báo động: các tập dữ liệu khoa học công khai đang "ngập tràn" những lỗi sai cơ bản do thao tác copy-paste.
Bài viết này sẽ đi sâu vào cách một công cụ phát hiện gian lận dữ liệu đã tìm ra các lỗi trong những nghiên cứu hàng đầu, từ bệnh Parkinson cho đến sinh học tiến hóa.
Bối cảnh: Sự ra đời của công cụ "thám tử dữ liệu"
Vấn đề được phát hiện nhờ một phần mềm được xây dựng vào năm ngoái, lấy cảm hứng từ các vụ bê bối dữ liệu gần đây của phòng thí nghiệm Nobel laureate Thomas Südhof và nhà sinh thái học nhện Jonathan Pruitt. Cả hai trường hợp này đều có các tập dữ liệu công khai chứa các khối dữ liệu bị sao chép hoàn toàn mà dường như rất dễ phát hiện.
Tò mò về việc liệu có bao nhiêu lỗi tương tự đang tồn tại, tác giả đã tạo ra một chương trình để gắn cờ các trường hợp này và chạy nó trên tất cả các tập dữ liệu có sẵn trong các kho lưu trữ mở. Cùng với một số cộng tác viên tình nguyện, dự án đã hoàn thành báo cáo cho 600 tập dữ liệu đầu tiên và tìm thấy 18 trường hợp đủ nghiêm trọng để gây lo ngại.
Dưới đây là 3 trong số các trường hợp đáng chú ý nhất.
Trường hợp 1: Lỗi trong nghiên cứu "bước ngoặt" về bệnh Parkinson
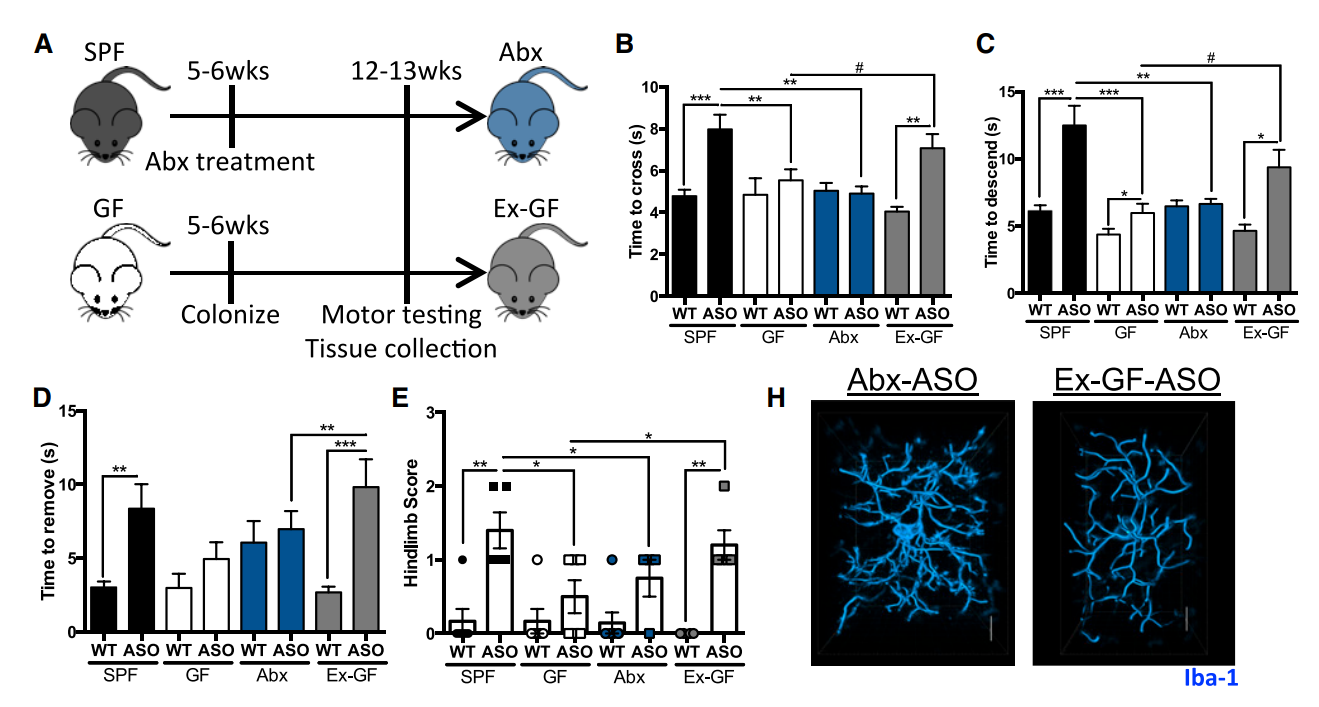
Một trong những bài báo bị phát hiện lỗi là nghiên cứu năm 2016 đăng trên tạp chí Cell, cung cấp bằng chứng đầu tiên cho thấy bệnh Parkinson bắt nguồn từ ruột chứ không phải não. Bài báo này đã nhận được sự quan tâm lớn của truyền thông và hơn 3000 trích dẫn.
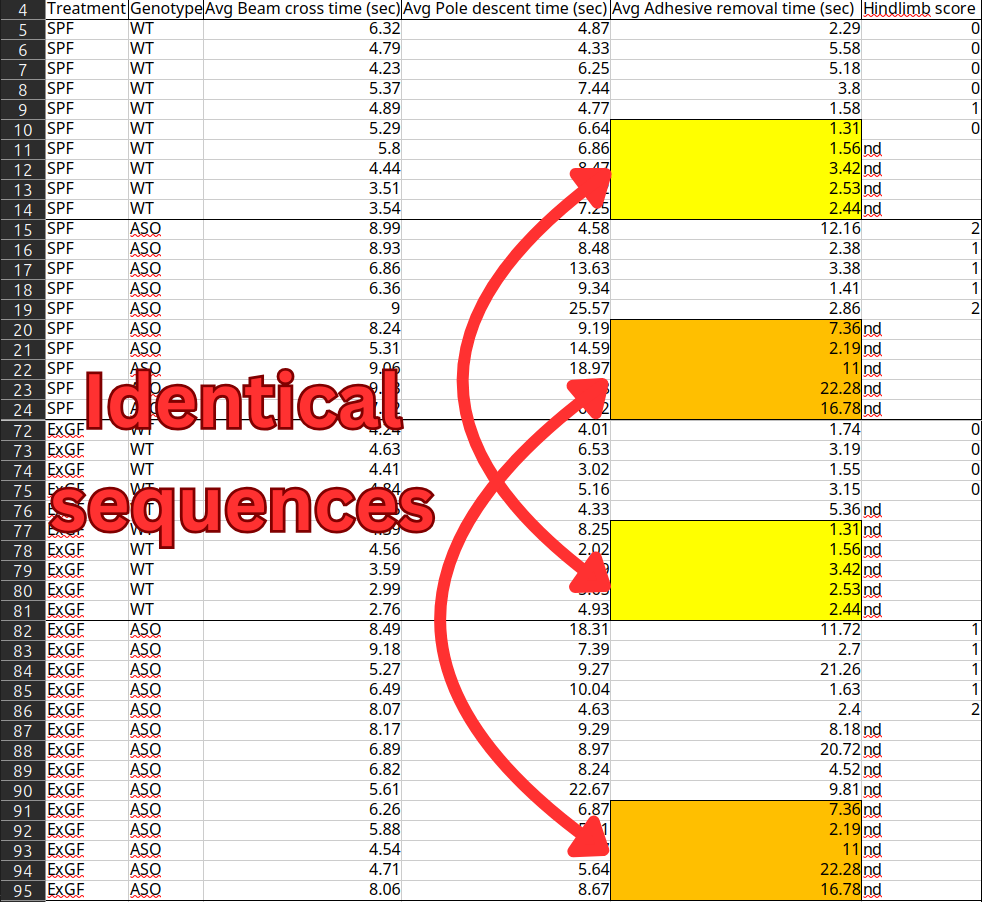
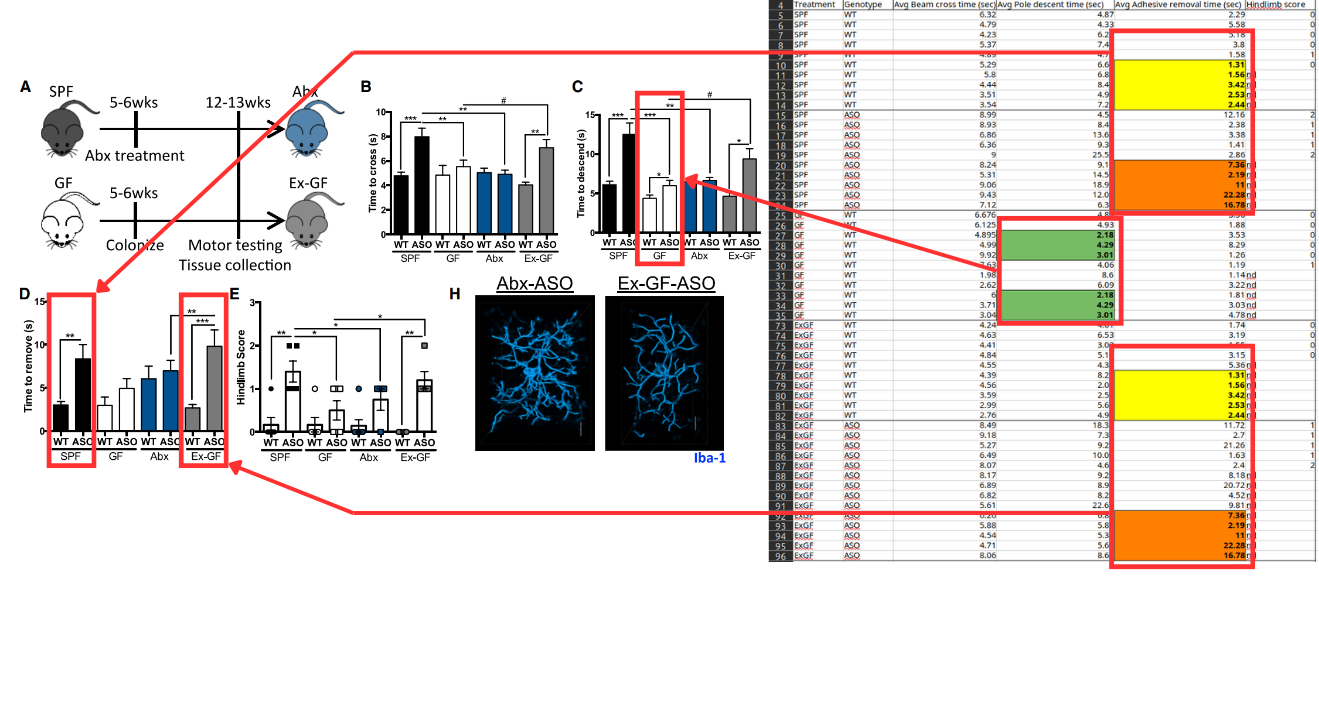
 Biểu đồ dữ liệu trong nghiên cứu Parkinson
Biểu đồ dữ liệu trong nghiên cứu Parkinson
Tuy nhiên, dữ liệu cơ bản chứa các chuỗi giá trị trùng lặp nên thuộc về các con chuột hoàn toàn khác nhau. Cụ thể, trong cột "Thời gian loại bỏ keo dán", có hai tập hợp 5 số giống hệt nhau được chia sẻ giữa nhóm chuột SPF (có hệ vi sinh vật bình thường) và nhóm chuột ExGF (được tái định cư vi sinh vật).
Ngoài ra, còn có các chuỗi số trùng lặp trong dữ liệu "Thời gian xuống cột". Với kích thước mẫu thấp, các hàng bị trùng lặp chiếm tới 50% mẫu SPF và 42% mẫu ExGF. Điều này làm nghiêm trọng ảnh hưởng đến kết luận rằng vi khuẩn ruột thực sự gây ra các triệu chứng giống Parkinson.
Vấn đề đã được báo cáo vào tháng 1, nhưng cho đến nay các tác giả vẫn chưa phản hồi.
Trường hợp 2: Sự nhầm lẫn giữa Đà điểu và Rắn
Trong một bài báo năm 2022 trên PLOS Genetics về sự tiến hóa của khả năng kháng độc ở động vật, các tác giả đã điều tra cách các loài động vật khác nhau phát triển khả năng kháng lại một họ độc tố gọi là steroid tim độc (CTS).
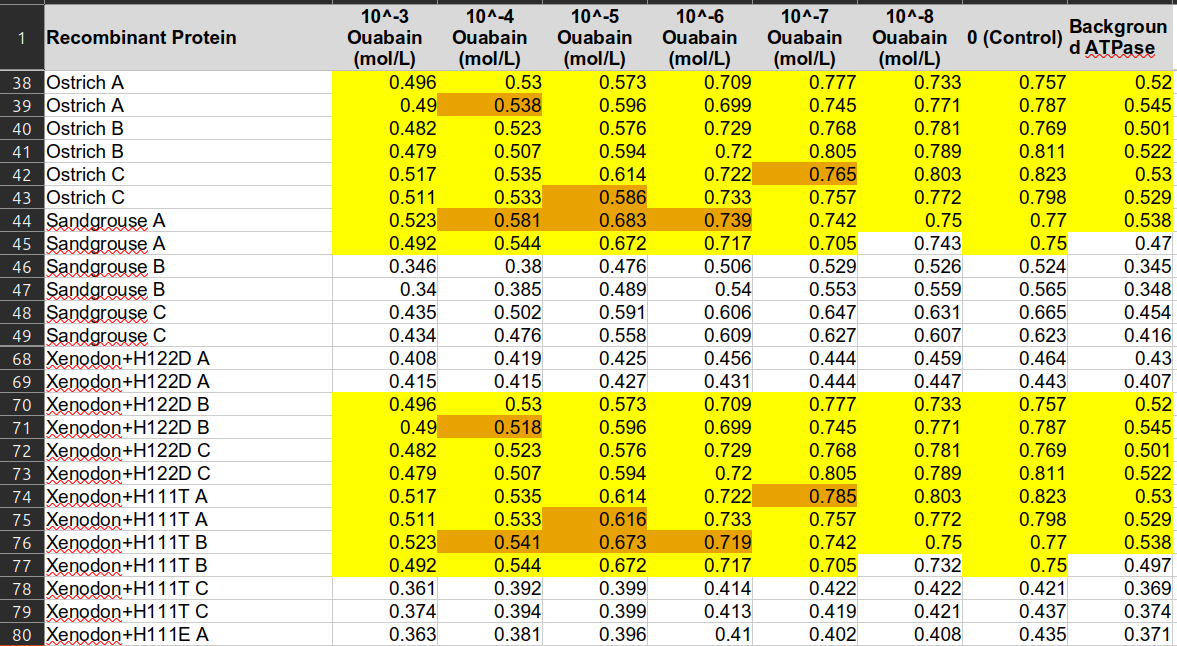
 Dữ liệu trùng lặp giữa Đà điểu và Rắn
Dữ liệu trùng lặp giữa Đà điểu và Rắn
Phần mềm đã phát hiện các ô màu vàng là bản sao chính xác giữa dữ liệu của Đà điểu/Chiền chiện và dữ liệu của Xenodon (một loài rắn). Ngay cả khi tác giả chính giải thích rằng sự khác biệt có thể do biến thiên trong các lần đọc cùng một đĩa thí nghiệm, việc có 6 cặp giá trị kết thúc bằng cùng một chữ số cuối cùng là một sự trùng hợp cực kỳ khó xảy ra theo xác suất thống kê.
Mặc dù tác giả thừa nhận có thể là lỗi copy-paste và cam kết thử nghiệm lại quy trình, trường hợp này vẫn để lại nhiều nghi ngờ về tính chính xác của dữ liệu thô.
Trường hợp 3: Kích thước cá bị xáo trộn
Nghiên cứu năm 2017 trên Nature Communications về tính cách của các cá thể cá nhân bản (clonal fish) đã gặp phải một lỗi dữ liệu kinh điển. Các nhà nghiên cứu đo lường hành vi bơi và kích thước của cá để xem sự khác biệt về hành vi có phải do kích thước cơ thể gây ra hay không.
 Dữ liệu kích thước cá bị sai lệch
Dữ liệu kích thước cá bị sai lệch
Vấn đề nằm ở cột SL (chiều dài tiêu chuẩn). Ba con cá khác nhau lại có cùng một chuỗi các phép đo kích thước. Nguyên nhân thực sự được tiết lộ khi sắp xếp bảng tính theo cột SL: mọi giá trị SL duy nhất đều xuất hiện chính xác bốn lần.
Tác giả đầu tiên đã thừa nhận lỗi và giải thích rằng họ lưu trữ kích thước cơ thể và hành vi trong hai tệp dữ liệu riêng biệt. Khi hợp nhất hai tệp này, họ đã căn sai các giá trị ID, dẫn đến việc tất cả các giá trị kích thước cơ thể bị dịch chuyển và gán cho các hàng sai.
May mắn thay, sau khi sửa lỗi, kết luận chính của bài báo vẫn không thay đổi đáng kể, mặc dù kích thước cơ thể bây giờ được chứng minh là có tác động nhỏ đến hành vi.
Kết quả và Tầm nhìn
Trong số 600 tập dữ liệu đầu tiên được quét, phần mềm đã phát hiện 18 trường hợp nghiêm trọng. Dựa trên mẫu hạn chế này, khoảng 3% các bài báo chứa các loại lỗi này. Tuy nhiên, tỷ lệ lỗi thực tế có thể còn cao hơn nhiều, vì có vô số cách khác để vô tình làm hỏng dữ liệu mà phần mềm này không thể phát hiện.
Điều đáng ngạc nhiên là không ai khác chịu trách nhiệm kiểm tra các lỗi này. Các tạp chí, trường đại học và tổ chức tài trợ thường không thuê nhân sự chuyên trách để làm việc này, mà tập trung nhiều hơn vào xếp hạng và các chỉ số đo lường.
Dự án này đã nhận được khoản tài trợ 50.000 USD từ Astral Codex Ten, cho phép tác giả nghỉ việc và làm việc toàn thời gian để quét qua khoảng 24.000 tập dữ liệu còn lại trên Dryad. Nếu tỷ lệ lỗi 3% giữ nguyên, chúng ta có thể mong đợi tìm thấy thêm khoảng 700 trường hợp khác.
Sự phát triển của các công cụ tự động hóa để kiểm tra tính toàn vẹn dữ liệu là một bước tiến cần thiết trong kỷ nguyên khoa học số, giúp đảm bảo rằng những nền tảng của tri thức nhân loại thực sự đáng tin cậy.
Bài viết liên quan

Công nghệ
NASA yêu cầu phi hành gia trú ẩn trong tàu SpaceX Dragon do rò rỉ tại ISS
05 tháng 6, 2026

Công nghệ
Ngay sau khi phát hành trái phiếu, Amazon vay thêm 17,5 tỷ USD từ ngân hàng để thúc đẩy chi tiêu AI
10 tháng 6, 2026

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026