
Phát hiện ảo giác trong dịch máy thần kinh: Phương pháp hiệu quả dựa trên sự lệch pha chú ý
Các hệ thống dịch máy thần kinh (NMT) thường gặp lỗi "ảo giác", đặc biệt khi xử lý các ngôn ngữ ít dữ liệu. Bài viết này giới thiệu một phương pháp chi phí thấp sử dụng sự lệch pha của cơ chế chú ý (attention misalignment) giữa mô hình dịch xuôi và ngược để ước tính độ không chắc chắn ở cấp độ token, giúp phát hiện lỗi dịch chính xác mà không cần huấn luyện lại mô hình nặng.
Dịch máy thần kinh (Neural Machine Translation - NMT) đã phát triển vượt bậc kể từ những ngày đầu của Google Translate vào năm 2007. Tuy nhiên, các hệ thống NMT vẫn có thể gặp phải tình trạng "ảo giác" (hallucinations) — tạo ra các từ hoặc câu hoàn toàn vô nghĩa — giống như bất kỳ mô hình AI nào khác, đặc biệt là khi xử lý các lĩnh vực ít tài nguyên (low-resource domains) hoặc dịch giữa các cặp ngôn ngữ hiếm.
Khi Google Translate trả về kết quả, bạn chỉ nhìn thấy văn bản đầu ra chứ không thấy các phân phối xác suất hay chỉ số độ không chắc chắn cho từng từ hoặc câu. Ngay cả khi người dùng thông thường không cần thông tin này, việc biết mô hình tự tin ở đâu và không tự tin ở đâu lại cực kỳ có giá trị cho các mục đích nội bộ. Ví dụ, các phần đơn giản có thể được giao cho một mô hình nhanh và rẻ, trong khi các phần khó hơn sẽ được phân bổ nhiều tài nguyên tính toán hơn.
Vậy làm thế nào để đánh giá và quan trọng hơn là "hiệu chuẩn" độ không chắc chắn này?
Hạn chế của các phương pháp hiện tại
Cách tiếp cận đầu tiên thường nghĩ đến là đánh giá phân phối xác suất đầu ra cho mỗi token, ví dụ như tính toán entropy của nó. Phương pháp này tính toán đơn giản, phổ quát trên các kiến trúc mô hình và thực sự có tương quan với các trường hợp mô hình NMT không chắc chắn.
Tuy nhiên, những hạn chế của phương pháp này là rõ ràng:
- Mô hình có thể đang phân vân giữa nhiều từ đồng nghĩa, và từ góc độ lựa chọn token, nó bị coi là không chắc chắn.
- Quan trọng hơn, đây chỉ là một phương pháp "hộp đen" (black-box) không giải thích được bản chất của sự không chắc chắn. Có thể mô hình thực sự chưa từng thấy dữ liệu tương tự trong quá trình huấn luyện, hoặc đơn giản là nó đã "ảo giác" ra một từ không tồn tại hoặc một cấu trúc ngữ pháp sai.
Các phương pháp hiện tại khác cũng giải quyết vấn đề này nhưng đều có những điểm riêng:
- Semantic Entropy: Cụm các đầu ra của mô hình theo ý nghĩa ngữ nghĩa, nhưng yêu cầu tạo ra 5–10 đầu ra cho một đầu vào, gây tốn kém về tính toán.
- xCOMET: Đạt hiệu suất SOTA ở cấp độ token, nhưng yêu cầu tinh chỉnh (fine-tune) 3,5 tỷ tham số của mô hình XLM-R trên dữ liệu được gán nhãn chất lượng đắt đỏ.
- Model Introspection: Phân tích độ nổi bật (saliency) cũng thú vị nhưng gặp khó khăn trong việc diễn giải.
Giải pháp: Kiểm tra chéo hai chiều (Bidirectional Cross-Check)
Phương pháp được đề xuất dưới đây có thể giúp tính toán độ không chắc chắn một cách hiệu quả hơn. Vì hầu hết các thiết lập NMT đều đã có hai mô hình — một mô hình xuôi (ngôn ngữ 1 → ngôn ngữ 2) và một mô hình ngược (ngôn ngữ 2 → ngôn ngữ 1) — chúng ta có thể tận dụng chúng để tạo ra các tín hiệu độ không chắc chắn có thể diễn giải được.
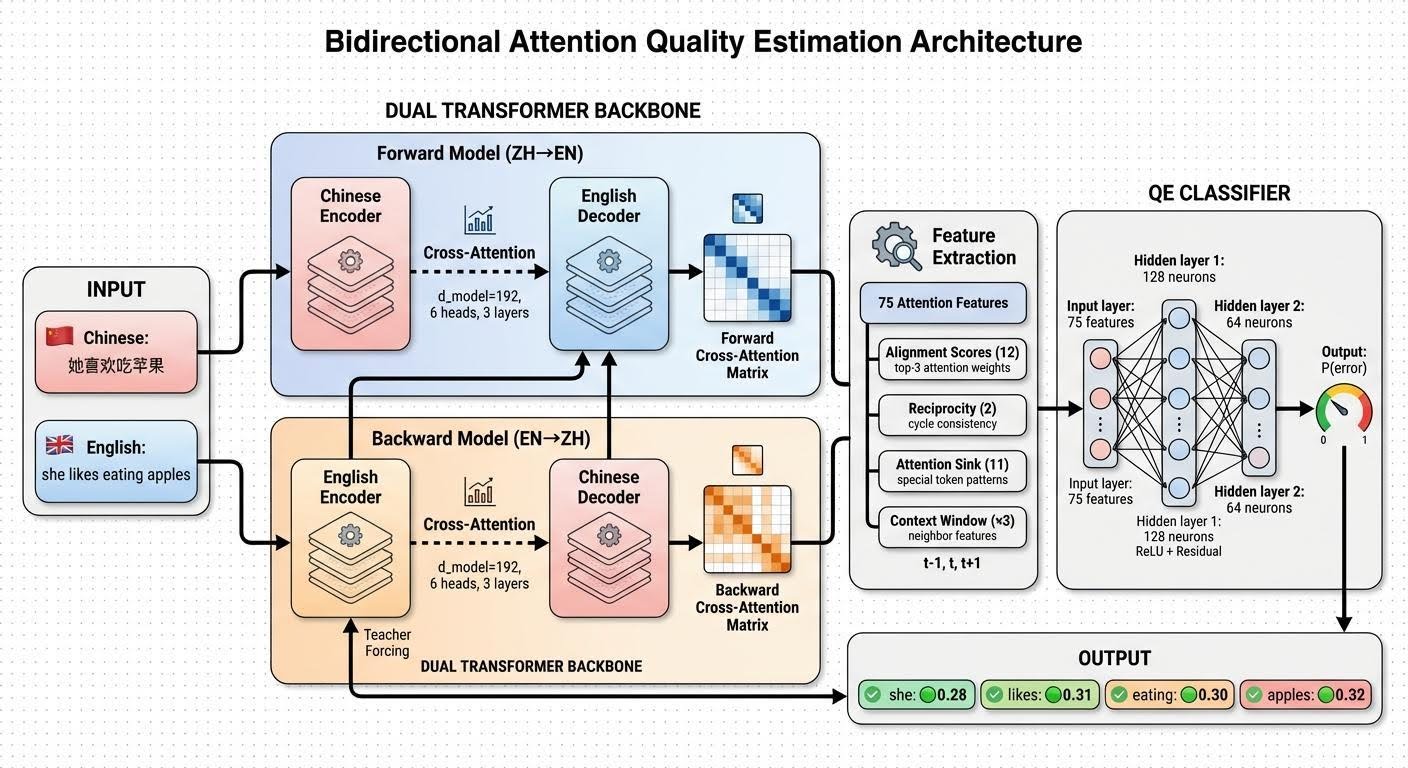
Sau khi tạo bản dịch bằng mô hình xuôi, chúng ta có thể "đặt" cặp bản dịch-nguồn đảo ngược vào mô hình ngược bằng kỹ thuật teacher forcing (như thể chính nó tạo ra bản dịch đó), sau đó trích xuất bản đồ chú ý chéo (cross-attention map) chuyển vị và so sánh nó với bản đồ tương ứng từ mô hình xuôi.
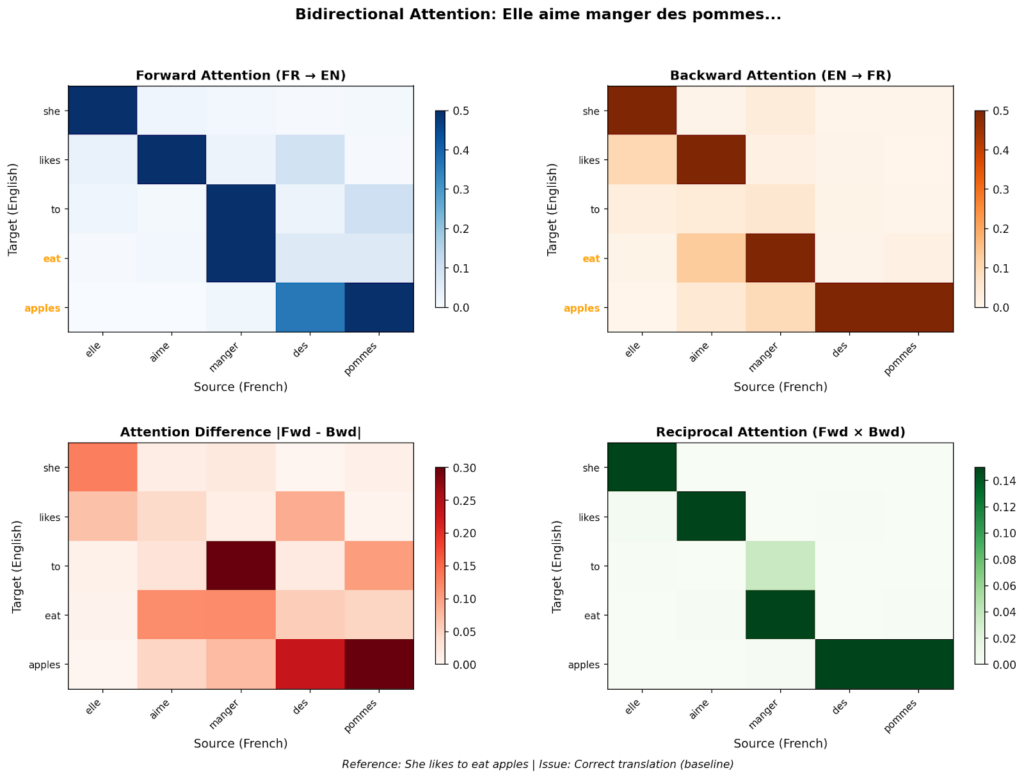 Ví dụ về bản dịch đúng và sai mô hình hóa sự chú ý
Ví dụ về bản dịch đúng và sai mô hình hóa sự chú ý
Hình trên minh họa sự khác biệt rõ rệt giữa một bản dịch đúng (trái) và một bản dịch có lỗi "ảo giác" (phải). Ở bản dịch đúng, mô hình chú ý tập trung vào các từ tương ứng trong câu nguồn. Ngược lại, khi xuất hiện từ "wife" (vợ) thừa thãi trong câu tiếng Anh, mô hình không tìm thấy đường dẫn ngược lại rõ ràng trong câu tiếng Pháp, dẫn đến điểm số chú ý bị mờ nhạt.
Điều thú vị là không cần phải huấn luyện lại mô hình NMT nặng nề. Chỉ cần huấn luyện một bộ phân loại (classifier) nhẹ trên các đặc trưng từ việc so sánh ma trận trong khi giữ nguyên các trọng số của mô hình chính.
Chiến lược trích xuất đặc trưng
Để huấn luyện bộ phân loại ước tính chất lượng (QE), chúng ta trích xuất 75 đặc trưng dựa trên sự liên kết chú ý cho mỗi token. Các đặc trưng này được chia thành 3 nhóm chính:
- Focus (Tập trung): Mô hình đang nhìn vào đâu? Các token ảo giác thường có sự chú ý phân tán (diffused attention) vì mô hình không thể neo giữ sự thật giữa nguồn và đích.
- Reciprocity (Tương quan hai chiều): Sự liên kết có tạo thành một vòng khép kín không? Ví dụ, nếu từ "wife" trong câu đích chú ý vào vị trí 3 trong câu nguồn, nhưng vị trí 3 đó không chú ý ngược lại "wife", thì liên kết này là giả tạo.
- Sink (Điểm chìm): Khi không chắc chắn, các mô hình Transformer thường đổ sự chú ý vào các token đặc biệt an toàn (SOS, EOS, PAD).
Kết quả thực nghiệm
Thiết lập thử nghiệm được thực hiện trên các cặp ngôn ngữ Trung-Anh (ZH→EN) và Pháp-Anh (FR→EN). Mô hình NMT được giữ nguyên trạng dưới chuẩn (undertrained) để đảm bảo có đủ các loại lỗi đa dạng cho bộ phân tích học hỏi.
Kết quả cho thấy khi kết hợp các đặc trưng chú ý (Attention) với entropy đầu ra, hiệu suất vượt trội hơn so với việc chỉ dùng riêng lẻ từng tín hiệu.
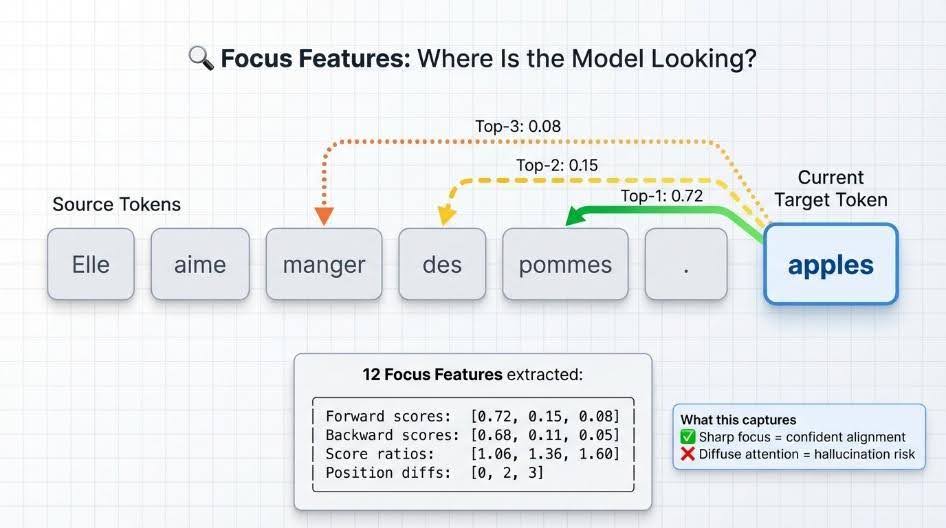 So sánh hiệu suất giữa các phương pháp
So sánh hiệu suất giữa các phương pháp
Bảng kết quả chỉ ra rằng phương pháp kết hợp (Combined) đạt điểm ROC-AUC và F1 cao nhất trên cả hai cặp ngôn ngữ, chứng minh rằng chúng nắm bắt các loại lỗi bổ sung cho nhau.
Kết luận và Hạn chế
Phương pháp này chứng minh rằng chúng ta có thể phát hiện ảo giác trong dịch thuật một cách hiệu quả mà không cần tốn quá nhiều chi phí tính toán hay tài nguyên gán nhãn. Tuy nhiên, nó cũng có một số hạn chế:
- Chi phí tính toán: Việc chạy mô hình ngược về cơ bản làm tăng thời gian suy luận (inference time).
- Mô hình hộp kính (Glassbox): Bạn cần quyền truy cập vào các trọng số chú ý (attention weights), do đó phương pháp này sẽ không hoạt động trên các mô hình dựa trên API khép kín.
- Không chắc chắn không đồng nghĩa với sai: Đôi khi mô hình đánh dấu sai các cụm từ đồng nghĩa chính xác vì mô hình chưa từng gặp mẫu câu đó trong quá trình huấn luyện.
Mã nguồn, mô hình và tập dữ liệu đã được gán nhãn đều được mã nguồn mở và có thể truy cập miễn phí trên GitHub để cộng đồng nghiên cứu và phát triển tiếp.
Tài nguyên tham khảo
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026