
RAG Chưa Đủ — Tôi Đã Xây Dựng Lớp Ngữ Cảnh Thiếu Sót Để Hệ Thống LLM Hoạt Động Hiệu Quả
Hầu hết các hướng dẫn về RAG chỉ tập trung vào việc truy xuất hoặc viết câu lệnh (prompt), nhưng vấn đề thực sự phát sinh khi ngữ cảnh mở rộng. Bài viết này giới thiệu một hệ thống kỹ thuật ngữ cảnh hoàn chỉnh bằng Python, kiểm soát bộ nhớ, nén, xếp hạng lại và ngân sách token để đảm bảo các mô hình ngôn ngữ lớn (LLM) hoạt động ổn định trong các điều kiện thực tế.

RAG Chưa Đủ — Tôi Đã Xây Dựng Lớp Ngữ Cảnh Thiếu Sót Để Hệ Thống LLM Hoạt Động Hiệu Quả
Tôi đã từng xây dựng một hệ thống RAG hoạt động hoàn hảo — cho đến khi nó không còn như vậy.
Khoảnh khắc tôi thêm lịch sử hội thoại vào, mọi thứ bắt đầu đổ vỡ. Các tài liệu liên quan bị loại bỏ, câu lệnh bị tràn, và mô hình bắt đầu quên những gì nó đã nói vài lượt trước. Không phải vì việc truy xuất thất bại, cũng không phải vì câu lệnh được viết tệ, mà vì tôi hoàn toàn không kiểm soát được những gì thực sự đi vào cửa sổ ngữ cảnh (context window).
Đó là vấn đề mà ít người bàn đến. Hầu hết các hướng dẫn về RAG dừng lại ở việc: truy xuất tài liệu, nhét chúng vào câu lệnh và gọi mô hình. Nhưng điều gì sẽ xảy ra khi ngữ cảnh truy xuất là 6.000 ký tự nhưng ngân sách còn lại chỉ là 1.800? Điều gì xảy ra khi ba trong số năm tài liệu truy xuất là trùng lặp, lấn át tài liệu duy nhất hữu ích?
Câu trả lời nằm ở một lớp mà hầu hết các hướng dẫn bỏ qua hoàn toàn: Context Engineering (Kỹ thuật ngữ cảnh). Đây là bước kiến trúc có chủ ý nằm giữa truy xuất thô và xây dựng câu lệnh — quyết định mô hình thực sự nhìn thấy gì, bao nhiêu và theo thứ tự nào.
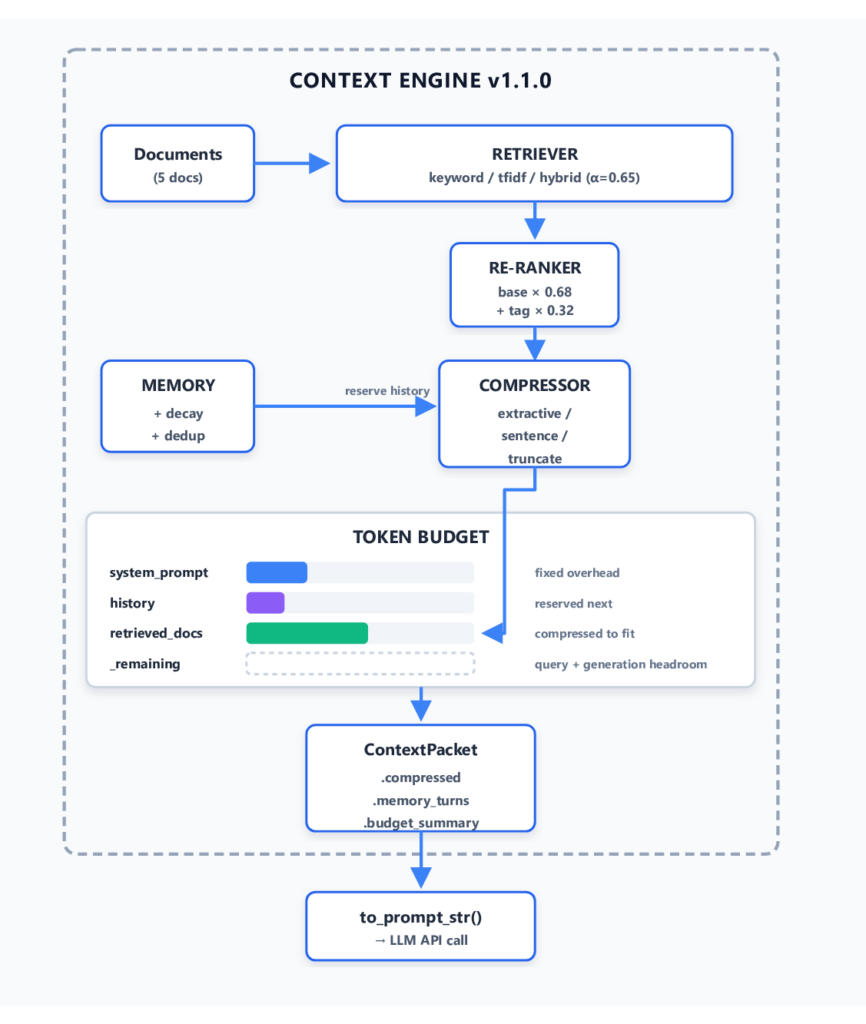 Kiến trúc Pipeline Kỹ thuật Ngữ cảnh
Kiến trúc Pipeline Kỹ thuật Ngữ cảnh
Kỹ thuật Ngữ cảnh thực sự là gì?
Cần chính xác về các thuật ngữ vì chúng thường bị nhầm lẫn:
- Prompt Engineering: Là nghệ thuật những gì bạn nói với mô hình — câu lệnh hệ thống, ví dụ few-shot, định dạng đầu ra. Nó định hình cách mô hình suy luận.
- RAG: Là kỹ thuật tìm nạp tài liệu bên ngoài và đưa chúng vào trước khi tạo. Nó giúp mô hình dựa trên thực tế.
- Context Engineering: Là lớp ở giữa — các quyết định kiến trúc về thông tin nào chảy vào cửa sổ ngữ cảnh, bao nhiêu và dưới dạng nào. Nó trả lời câu hỏi: Cho mọi thứ có thể đi vào câu lệnh này, thì cái gì thực sự nên đi vào?
Thành phần 1: Bộ truy xuất (The Retriever)
Hầu hết các triển khai RAG chỉ chọn một phương thức truy xuất. Tuy nhiên, không có phương thức nào thống trị mọi loại truy vấn. Khớp từ khóa nhanh và chính xác cho các thuật ngữ chính xác. TF-IDF xử lý trọng số thuật ngữ tốt hơn. Dense vector embeddings bắt được mối quan hệ ngữ nghĩa mà từ khóa bỏ sót.
Hệ thống này hỗ trợ ba chế độ: keyword, tfidf, và hybrid. Chế độ lai chạy cả hai phương pháp và trộn điểm số của chúng:
hybrid_score = alpha * emb_score + (1 - alpha) * tf_score
Mặc định alpha=0.65 ưu tiên embeddings hơi cao hơn TF-IDF. Điều này giúp khắc phục trường hợp truy vấn mang tính khái niệm với cách diễn đạt khác nhau mà từ khóa không thể bắt được.
Thành phần 2: Bộ xếp hạng lại (The Re-ranker)
Truy xuất đưa ra các ứng viên. Xếp hạng lại quyết định thứ tự cuối cùng.
Bộ xếp hạng lại áp dụng tổng có trọng số hai yếu tố: điểm truy xuất và giá trị quan trọng dựa trên thẻ (tag). Các tài liệu được gắn thẻ memory, context, rag hoặc embedding nhận được mức tăng điểm quan trọng. Công thức là:
final_score = base_score * 0.68 + tag_importance * 0.32
Việc sắp xếp lại này thay đổi những tài liệu nào sống sót qua quá trình nén — nó không chỉ là trang trí.
Thành phần 3: Bộ nhớ với Suy giảm theo Cấp số nhân
Đây là thành phần quan trọng nhất mà các hệ thống ngây thơ thường sụp đổ nhanh nhất. Bộ nhớ hội thoại có hai chế độ thất bại: quên quá nhanh (mất ngữ cảnh vẫn còn liên quan) hoặc quên quá chậm (tích tụ nhiễu).
Giải pháp là suy giảm theo cấp số nhân (exponential decay), nơi các lượt hội thoại mờ dần dựa trên ba yếu tố: độ quan trọng, tính mới mẻ và sự phù hợp. Điều này phản ánh cách bộ nhớ làm việc thực sự ưu tiên thông tin — các lượt quan trọng tồn tại lâu hơn, các lượt off-topic mờ đi nhanh chóng.
Hệ thống cũng tự động chấm điểm quan trọng dựa trên nội dung. Ví dụ, một câu hỏi về thời tiết sẽ có điểm thấp và bị loại bỏ nhanh, trong khi câu hỏi về kỹ thuật sẽ có điểm cao và được giữ lại lâu hơn.
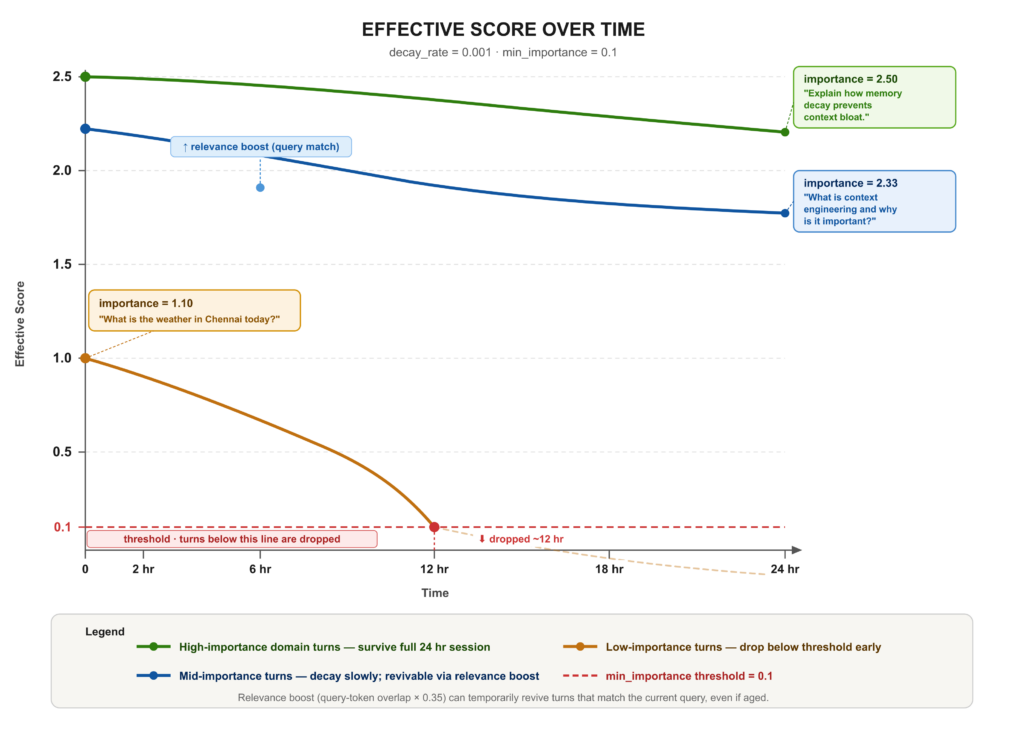 Điểm hiệu quả suy giảm theo thời gian
Điểm hiệu quả suy giảm theo thời gian
Thành phần 4: Nén Ngữ cảnh (Context Compression)
Khi bạn có 810 ký tự ngữ cảnh nhưng ngân sách chỉ còn 800, một cái gì đó phải bị cắt.
Bộ nén thực hiện ba chiến lược:
- Truncate: Cắt từng khối tỷ lệ — nhanh nhất.
- Sentence: Chọn ranh giới câu một cách tham lam.
- Extractive: Nhận biết truy vấn — chấm điểm từng câu bằng sự chồng lấn token với truy vấn, xếp hạng và chọn trong ngân sách. Chiến lược này bảo toàn ý nghĩa tốt hơn nhưng ít tiết kiệm ký tự thô hơn.
Thành phần 5: Thực thi Ngân sách Token
Mọi thứ đều đổ vào TokenBudget — một bộ phân bổ dựa trên khe (slot) theo dõi việc sử dụng trên các vùng ngữ cảnh được đặt tên. Thứ tự dự trữ là toàn bộ thiết kế:
- System Prompt: Chi phí cố định không thể thương lượng.
- Memory (Lịch sử): Điều làm cho đa lượt (multi-turn) mạch lạc.
- Documents (Tài liệu): Biến số — hữu ích nhưng là thứ đầu tiên bị nén khi hết chỗ.
Nếu dự trữ sai thứ tự, tài liệu sẽ âm thầm tràn ngân sách trước khi lịch sử được tính đến.
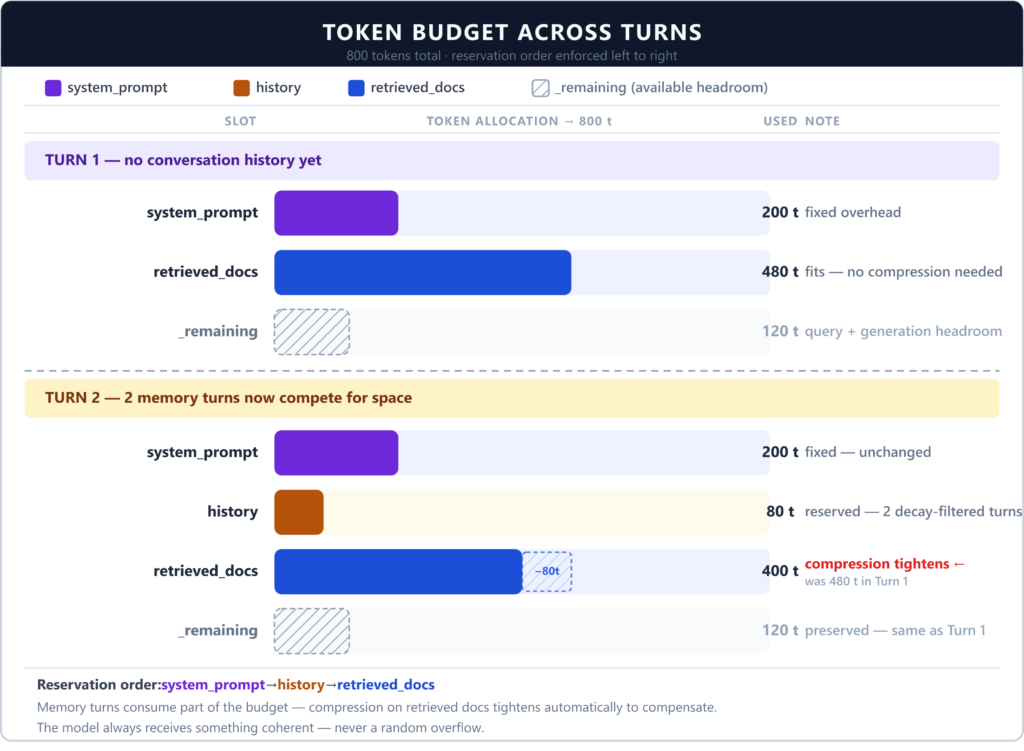 Phân bổ ngân sách Token qua các lượt
Phân bổ ngân sách Token qua các lượt
Đo lường Hiệu suất
Đo trên Python 3.12.6, chỉ CPU, không có GPU, cơ sở kiến thức 5 tài liệu:
- Truy xuất từ khóa: ~0.8ms
- Truy xuất TF-IDF: ~2.1ms
- Truy xuất lai (Hybrid): ~85ms (tạo embeddings chiếm chủ yếu)
- Xếp hạng lại (5 docs): ~0.3ms
- Bộ nhớ & Lọc: ~0.6ms
- Nén (extractive): ~4.2ms
- Toàn bộ engine.build(): ~92ms
Truy xuất lai là điểm nghẽn. Nếu bạn cần thời gian phản hồi dưới 50ms, hãy sử dụng chế độ TF-IDF hoặc từ khóa thay thế.
Kết luận
RAG giúp bạn có đúng tài liệu. Prompt engineering giúp bạn có đúng hướng dẫn. Context engineering giúp bạn có đúng ngữ cảnh.
Prompt engineering quyết định mô hình suy nghĩ như thế nào. Context engineering quyết định nó có được suy nghĩ về cái gì.
Hầu hết các hệ thống tối ưu hóa cái trước và bỏ qua cái sau. Đó là lý do chúng bị lỗi. Mã nguồn đầy đủ với tất cả bảy bản demo có thể được tìm thấy tại kho GitHub của dự án.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026