
Rerankers không phải là phép màu: Khi nào lớp Cross-Encoder thực sự đáng giá?
Nhiều đội ngũ phát triển tin rằng thêm một reranker (cross-encoder) sẽ khắc phục mọi hạn chế của hệ thống RAG, nhưng thực tế chứng minh điều này không luôn đúng. Bài viết phân tích thực nghiệm cho thấy việc nâng cấp mô hình nhúng hoặc tối ưu hóa kiến trúc truy xuất thường mang lại hiệu quả tốt hơn so với việc chồng thêm các lớp reranker phức tạp. Rerankers chỉ thực sự phát huy tác dụng trong các trường hợp cụ thể như xử lý tín hiệu bị loãng, chứ không giải quyết được các vấn đề logic như phủ định hay liệt kê danh sách.

Trong thế giới phát triển hệ thống RAG (Retrieval-Augmented Generation), có một niềm tin phổ biến rằng nếu truy xuất tài liệu (retrieval) không tốt, hãy thêm một reranker. Về lý thuyết, reranker (đặc biệt là cross-encoder) thông minh hơn so sánh cosine đơn thuần của các mô hình nhúng (embeddings), và việc xếp hạng lại các kết quả sẽ giúp LLM nhận được thông tin chính xác hơn.
Tuy nhiên, thực tế sản xuất thường phức tạp hơn những gì sách giáo khoa vẽ ra. Bài viết này sẽ đi sâu vào phân tích xem liệu cross-encoder có thực sự là "viên đạn bạc" cho mọi vấn đề truy xuất tài liệu doanh nghiệp hay không, và khi nào thì chi phí tính toán của nó thực sự đáng giá.
Ảo tưởng về việc sửa chữa hệ thống yếu
Hãy tưởng tượng một đội ngũ đang xây dựng hệ thống RAG cho vài trăm hợp đồng. Họ gặp vấn đề kinh điển: mô hình nhúng bị lỗi với các câu phủ định (negation), không nhận diện chính xác các định danh (identifiers), và bỏ sót câu trả lời dù có nó trong tài liệu.
Phản xạ đầu tiên thường là thêm một reranker. Họ cài đặt bge-reranker-base, lấy top-100 kết quả từ giai đoạn nhúng, rerank chúng và giữ lại top-10. Ban đầu, một số truy vấn hỏng dường như hoạt động trở lại. Nhưng chỉ hai tuần sau, các vấn đề cũ quay trở lại.
Người dùng hỏi "liệt kê mọi điều khoản đề cập đến việc chấm dứt hợp đồng", hệ thống chỉ trả về 3 điều khoản "liên quan nhất" trong khi hợp đồng có tới 11 điều khoản như vậy. Khi hỏi về quy định hủy bỏ cho "nhân viên không chính thức" (non-employee), reranker chưa từng thấy thuật ngữ này của công ty và xếp hạng một đoạn văn không liên quan lên đầu. Về cơ bản, cross-encoder cũng không hiểu logic phủ định giống như mô hình nhúng.
 Biểu đồ so sánh hiệu suất các mô hình
Biểu đồ so sánh hiệu suất các mô hình
Cơ chế: Bi-encoder vs Cross-encoder
Để hiểu tại sao reranker không phải là phép màu, ta cần hiểu sự khác biệt cơ học giữa hai loại mô hình này.
Bi-encoder (Mô hình nhúng): Mã hóa câu hỏi và đoạn văn bản độc lập thành hai vector, sau đó so sánh độ tương đồng cosine. Tương tác giữa câu hỏi và văn bản phải sống sót qua quá trình chiếu xuống không gian vector cố định. Nhanh và rẻ, có thể tính toán trước (precompute).
Cross-encoder (Reranker): Mã hóa câu hỏi và đoạn văn bản cùng lúc, đưa qua một transformer cho phép chúng "chú ý" (attend) lẫn nhau. Mỗi token trong văn bản có thể nhìn thấy mọi token trong câu hỏi. Về nguyên tắc, điều này cho phép cross-encoder nắm bắt các tương tác tinh tế mà bi-encoder không thể biểu diễn. Tuy nhiên, nó không thể tính toán trước và tốn nhiều chi phí tính toán hơn tại thời điểm truy vấn.
Kiểm chứng thực nghiệm: Chi phí vs Hiệu suất
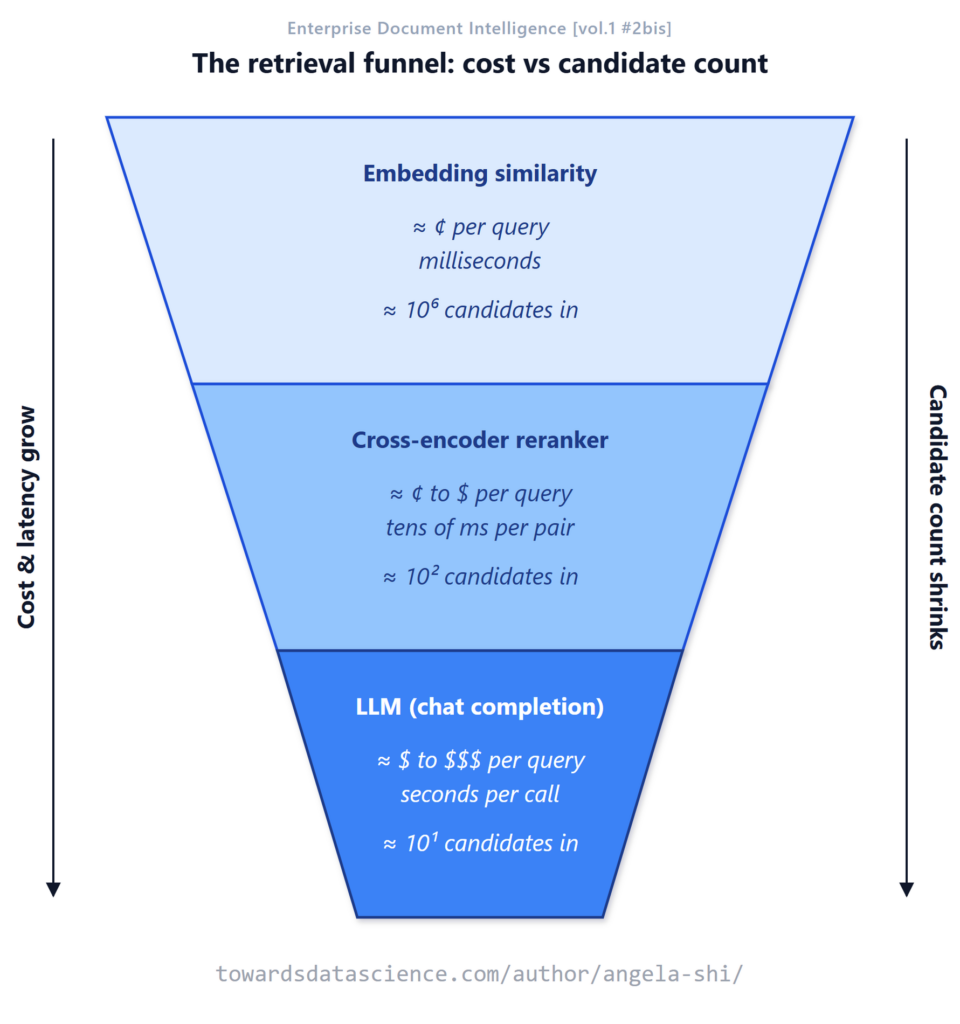
Bài viết đã thực hiện các bài kiểm tra trên 7 mô hình (từ GloVe 2014 đến text-embedding-3-large 2024, cùng 3 reranker phổ biến) trên các trường hợp cụ thể. Kết quả khá bất ngờ so với lý thuyết về "phễu" (funnel) cổ điển.
Bẫy từ字面 (Literal-token trap)
Trong truy vấn "hot dog", mô hình nhúng mới nhất text-embedding-3-large là mô hình duy nhất nhận diện đúng nghĩa (thức ăn) và xếp hạng nó cao hơn bẫy từ字面 (con chó nằm dưới nắng nóng). Không một trong ba reranker nào làm được điều này. Điều này cho thấy việc nâng cấp mô hình nhúng đôi khi hiệu quả hơn thêm reranker.
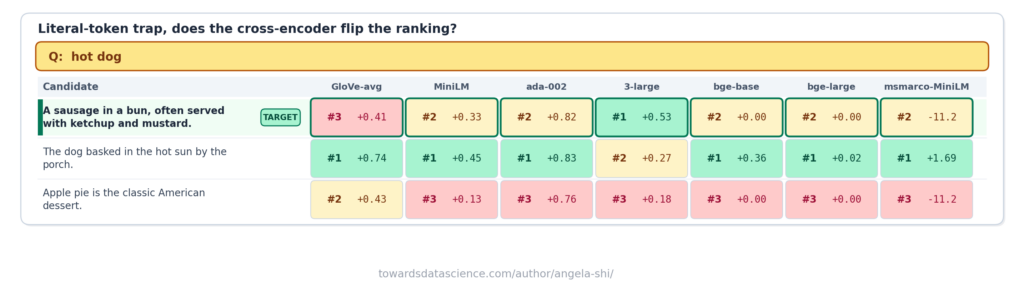
Đồng nghĩa và nhiễu từ vựng
Khi truy vấn về "thẻ xanh" (green card) cần thiết cho thường trú, các reranker lớn đôi khi lại bị bẫy bởi các đoạn văn chứa từ "green" và "card" nhưng sai nghĩa (ví dụ: thẻ màu xanh dùng trong văn phòng phẩm). Trong một số trường hợp, mô hình nhỏ hơn thậm chí xếp hạng chính xác hơn reranker lớn.
Tín hiệu bị loãng trong ngữ cảnh dài
Đây là nơi reranker thực sự tỏa sáng. Khi câu trả lời bị chôn vùi trong một đoạn văn dài 70 từ đầy nhiễu, các reranker như bge-large có khả năng "khai quật" được câu trả lời đó và đưa nó lên vị trí cao. Trong trường hợp này, hoặc bạn trả tiền cho mô hình nhúng mạnh (text-embedding-3-large), hoặc bạn dùng reranker miễn phí trên nền tảng nhúng rẻ hơn.
 Hiệu quả của Reranker trong việc xử lý tín hiệu loãng
Hiệu quả của Reranker trong việc xử lý tín hiệu loãng
Những điểm Cross-encoder vẫn thất bại
Dù mạnh mẽ hơn về mặt lý thuyết, cross-encoder vẫn chia sẻ những điểm mù với bi-encoder trong các trường hợp sau:
Phủ định (Negation)
Câu hỏi "Cái gì KHÔNG phải là thành phố?" với các ứng viên Paris, New York, City, Table. Cả hai loại mô hình đều xếp Table (đáp án đúng) cuối cùng vì chúng được huấn luyện để xếp hạng theo độ liên quan chủ đề, chứ không phải logic bù (logical complementation).
Câu hỏi liệt kê (Listing)
Reranker's nhiệm vụ là xếp hạng. Nhưng khi người dùng hỏi "liệt kê mọi điều khoản", họ cần tất cả, không chỉ top 10. Việc cắt bỏ top-k sẽ loại bỏ các đáp án đúng bị xếp hạng thấp.
Từ vựng ngoài lĩnh vực (Out-of-domain vocabulary)
Nếu công ty dùng thuật ngữ riêng như "non-employee labor" thay vì "contractor", reranker sẵn có không thể nào biết được sự liên hệ này trừ khi được fine-tune (huấn luyện lại) cụ thể.
Khi nào Reranker thực sự đáng giá?
Quan điểm biên tập của bài viết rất rõ ràng: Cross-encoder rerankers là giải pháp dự phòng cho các trường hợp hẹp, không phải là giai đoạn chính của pipeline doanh nghiệp.
Chúng chỉ đáng giá khi:
- Hồ sơ ứng viên rất lớn (hàng trăm nghìn tài liệu từ vector store).
- Tầng dưới là cosine similarity chung chung.
- Không có thời gian để xây dựng pipeline tùy chỉnh.
Trong môi trường doanh nghiệp thực tế, các bước kiến trúc sau sẽ làm giảm giá trị của reranker:
- Phân tích câu hỏi (Question parsing): Định tuyến câu hỏi liệt kê sang pipeline tổng hợp, câu hỏi phủ định được xử lý đảo ngược.
- Phân loại trước khi truy xuất (Classify-before-retrieve): Sử dụng metadata để lọc tài liệu, giảm số lượng ứng viên đầu vào xuống mức nhỏ (ví dụ từ 200.000 xuống 800).
- Từ khóa chuyên gia (Expert keywords): Sử dụng từ điển do chuyên gia biên soạn để ánh xạ thuật ngữ người dùng sang thuật ngữ tài liệu, thay vì dựa vào xếp hạng xác suất.
Kết luận
Rerankers là công cụ hữu ích và có vị trí quan trọng trong tài liệu học thuật. Tuy nhiên, việc kỳ vọng chúng sửa chữa mọi lỗi của hệ thống truy xuất yếu là một ảo tưởng nguy hiểm.
Dữ liệu thực nghiệm cho thấy trên nhiều hình thái truy vấn, việc nâng cấp mô hình nhúng hoặc cải thiện kiến trúc pipeline mang lại hiệu quả cao hơn so với việc chồng thêm một lớp reranker. Đô la bỏ ra cho việc cải thiện tầng nhúng hoặc xây dựng hệ thống lọc thông minh thường mang lại lợi nhuận cao hơn là chi tiền cho reranker tại thời điểm chạy (runtime).
Rerankers không phải là phép màu. Chúng chỉ là một công cụ trong hộp dụng cụ của kỹ sư, và chỉ nên dùng khi đúng hoàn cảnh.
 Kiến trúc hệ thống RAG tối ưu
Kiến trúc hệ thống RAG tối ưu
Bài viết liên quan

Phần mềm
Lập trình viên đang xây dựng công cụ để thuần hóa mối đe dọa từ AI
17 tháng 6, 2026

Phần mềm
Microsoft giới thiệu Project Solara: Hệ điều hành mới dành cho thiết bị chạy tác nhân AI
02 tháng 6, 2026
Công nghệ
Robinhood cho phép các tác nhân AI thực hiện giao dịch chứng khoán và thanh toán
27 tháng 5, 2026