
Research-Driven Agents: Khi Tác nhân AI Đọc Tài Liệu Nghiên Cứu Trước Khi Viết Code
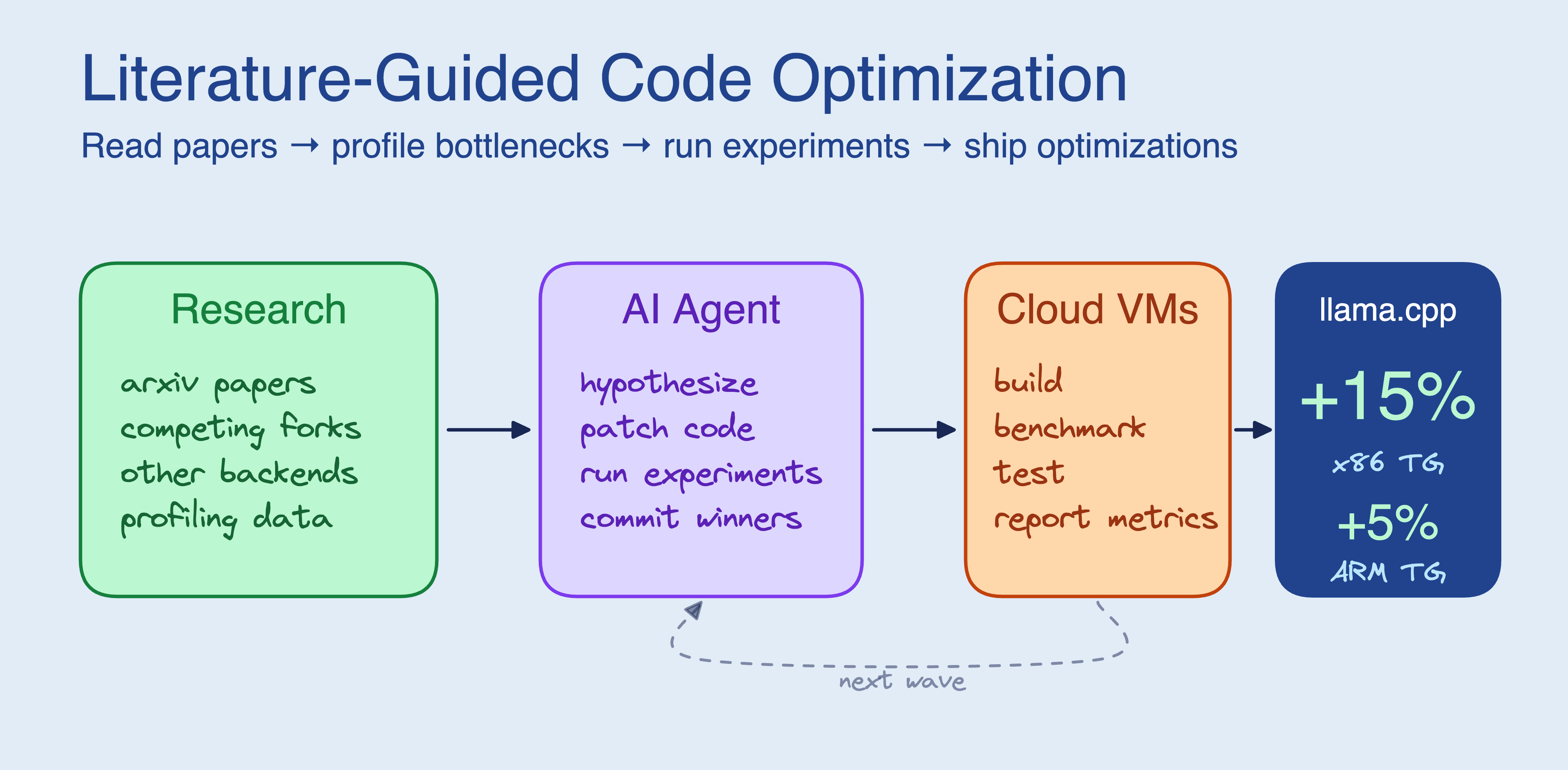
Các tác nhân AI có khả năng tạo ra các tối ưu hóa mã nguồn hiệu quả hơn đáng kể nếu được phép đọc các bài báo khoa học và phân tích dự án của đối thủ trước khi bắt đầu viết code. Thí nghiệm trên llama.cpp đã chứng minh phương pháp này giúp tăng tốc độ tạo văn bản lên 15% trên x86 và 5% trên ARM nhờ việc áp dụng các kỹ thuật hợp nhất kernel từ tài liệu nghiên cứu.
Trong bối cảnh phát triển phần mềm hiện đại, các tác nhân AI (AI agents) đang ngày càng chứng minh khả năng tự động hóa các tác vụ lập trình. Tuy nhiên, một câu hỏi lớn đặt ra là: Liệu chúng có thể thực sự thay thế được tư duy chiến lược của một kỹ sư cấp cao không? Bài viết này sẽ khám phá khái niệm "Research-Driven Agents" – những tác nhân biết cách nghiên cứu trước khi viết code – và những kết quả đáng kinh ngạc mà chúng đạt được.
Banner bài viết
Tại sao chỉ đọc code là chưa đủ?
Thông thường, các tác nhân AI hoạt động dựa trên ngữ cảnh của mã nguồn hiện có. Chúng phân tích code, đưa ra giả thuyết và chạy thử nghiệm. Phương pháp này hoạt động tốt trong các trường hợp tối ưu hóa bề mặt hiển thị, như ví dụ trước đây trên Liquid template engine, nơi agent đã giảm thời gian parse xuống 53%.
Tuy nhiên, không phải bài toán tối ưu hóa nào cũng nằm ngay trong mã nguồn. Một codebase có thể cho bạn biết code "làm gì", nhưng không giải thích được "tại sao nó chậm" hoặc "các giải pháp thay thế bên ngoài là gì". Khi câu trả lời nằm ngoài phạm vi nguồn – trong các bài báo trên Arxiv, trong các dự án cạnh tranh, hoặc trong kiến thức chuyên môn về phần cứng – một tác nhân chỉ dựa vào code sẽ tạo ra các giả thuyết hời hợt.
Chúng tôi đã nhận thấy điều này khi áp dụng tác nhân vào llama.cpp. Làn sóng thử nghiệm đầu tiên chỉ tập trung vào các vi tối ưu hóa SIMD (như AVX2 prefetching) nhưng không mang lại hiệu quả đáng kể. Nguyên nhân là do tác nhân không nhận ra rằng vấn đề không nằm ở khả năng tính toán (compute-bound) mà nằm ở băng thông bộ nhớ (memory-bound).
 Sơ đồ vòng lặp nghiên cứu
Sơ đồ vòng lặp nghiên cứu
Thêm giai đoạn nghiên cứu: Đọc trước khi làm
Để giải quyết hạn chế về chất lượng giả thuyết, chúng tôi đã thêm một bước "nghiên cứu" vào quy trình tự động hóa. Trước khi chạm vào bất kỳ dòng code nào, tác nhân sẽ được yêu cầu:
- Đọc các bài báo nghiên cứu học thuật (Arxiv).
- Nghiên cứu các nhánh (fork) dự án khác và các backend cạnh tranh.
- Tìm hiểu kiến thức miền mà một kỹ sư cấp cao thường có.
Quy trình mới này bao gồm: Nghiên cứu -> Chỉnh sửa code -> Chạy thử nghiệm -> Kiểm tra chỉ số -> Giữ lại hoặc loại bỏ. Chúng tôi sử dụng SkyPilot để phân phối các thí nghiệm song song trên các đám mây máy ảo (Cloud VMs), giúp tăng tốc độ khám phá.
Thí nghiệm trên llama.cpp
Chúng tôi đã hướng dẫn Claude Code tối ưu hóa đường dẫn suy luận (inference path) trên CPU của llama.cpp, sử dụng 4 máy ảo AWS. Mục tiêu là tăng thông lượng (tokens/giây) cho mô hình TinyLlama 1.1B trên hai kiến trúc: x86 (Intel Xeon) và ARM (Graviton3).
Giai đoạn nghiên cứu đã chỉ ra nhiều manh mối quan trọng từ các dự án như ik_llama.cpp, llamafile và các bài báo về FlashAttention. Đặc biệt, việc phân tích các backend CUDA và Metal đã giúp tác nhân nhận ra rằng các kỹ thuật "hợp nhất toán tử" (operator fusion) đã có sẵn ở đó nhưng lại vắng mặt trên CPU.
Chuyển dịch từ Tính toán sang Bộ nhớ
Sau khi các vi tối ưu hóa tính toán thất bại, tác nhân đã chuyển hướng chiến lược: "Tôi cần chuyển sang các tối ưu hóa giảm lưu lượng bộ nhớ hoặc cải thiện mẫu truy cập bộ nhớ."
Mặc dù phép nhân ma trận (matmul) chiếm 95% thời gian, các thao tác còn lại (softmax, RMS norm) lại đủ nhỏ để bị giới hạn bởi tính toán. Do đó, việc giảm số lần truy cập bộ nhớ trong các thao tác này là chìa khóa.
Các tối ưu hóa thành công
Trong hơn 30 thí nghiệm, 5 cái đã được đưa vào code cuối cùng, mỗi cái nhắm vào một phần khác nhau của chi phí không phải matmul:
- Softmax fusion: Hợp nhất 3 lần truyền dữ liệu (copy, scale, add mask) thành 1 vòng lặp duy nhất.
- RMS norm fusion: Hợp nhất chuẩn hóa RMS và phép nhân trọng số (weight multiplication) thành một bước.
- Adaptive from_float parallelization: Tối ưu hóa song song hóa chuyển đổi định dạng dữ liệu.
- Graph-level RMS_NORM + MUL fusion: Áp dụng fusion ở mức đồ tính toán (graph level).
- Flash attention KQ fusion: Đây là chiến thắng lớn nhất. Tác nhân hợp nhất 3 lần truyền qua tile KQ (scale, pad, add mask) thành một vòng lặp AVX2 FMA duy nhất.
 Phễu thí nghiệm và kết quả
Phễu thí nghiệm và kết quả
Kết quả đạt được
Kết quả là rất ấn tượng. Trên kiến trúc x86, tốc độ tạo văn bản (text generation) nhanh hơn 15%. Trên ARM, tốc độ tăng thêm 5%. Tổng chi phí cho quá trình này là khoảng 29 USD (trong đó 20 USD cho CPU VMs và 9 USD cho cuộc gọi API) trong vòng 3 giờ.
Điều này chứng minh rằng việc trang bị cho tác nhân AI khả năng tự nghiên cứu và học hỏi từ cộng đồng là bước tiến quan trọng. Nó giúp chúng tìm ra những giải pháp sâu sắc mà việc chỉ nhìn vào code hiện tại không thể thấy được.
Kết luận
Mô hình "Research-Driven Agents" mở ra hướng đi mới cho tự động hóa lập trình. Thay vì chỉ là những công cụ sửa lỗi cú pháp hay gợi ý code đơn giản, chúng có thể trở thành những trợ lý năng động, biết cách tự cập nhật kiến thức từ tài liệu chuyên ngành và áp dụng vào thực tế.
Bạn có thể thử nghiệm quy trình này trên dự án của riêng mình bằng cách sử dụng các template do SkyPilot cung cấp, đặc biệt là với các khung suy luận ML (ML inference frameworks) nơi các chỉ số hiệu năng rõ ràng và cơ hội tối ưu hóa luôn mới mẻ.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026