
SciPy quá chậm cho suy luận Bayes: Cách Diffrax giải cứu hiệu năng tính toán của tôi
Là một nhà vũ trụ học, tôi nhận thấy bộ giải ODE của SciPy đang làm chậm đáng kể quá trình suy luận Bayes của mình. Chuyển sang thư viện Diffrax dựa trên JAX đã giúp tăng tốc độ tính toán lên gấp 7 lần và cung cấp gradient miễn phí thông qua autodiff.

Trong công việc của một nhà vũ trụ học lý thuyết, tôi thường xuyên phải đối mặt với các mô hình Vũ trụ phức tạp — từ các trạng thái phương trình của năng lượng tối đến trường tachyon. Câu hỏi cốt lõi luôn là: Dữ liệu thực tế nói gì về các tham số này? Và công cụ để trả lời câu hỏi đó chính là suy luận Bayes (Bayesian inference).
Thông thường, tôi chạy thuật toán nested sampling (thư viện dynesty) với vài nghìn đến vài trăm nghìn lần đánh định hàm khả năng (likelihood evaluations). Trong suốt quá trình làm Tiến sĩ, tôi ít khi bận tâm đến bộ giải phương trình vi phân thường (ODE solver) bên trong hàm likelihood, miễn là solve_ivp của SciPy vẫn hoạt động tốt. Nó đáng tin cậy, nên tôi dùng nó và quên đi vấn đề.
Cho đến khi tôi bắt đầu làm việc với một mô hình năng lượng tối tachyon DBI, nơi trường năng lượng tối được điều khiển bởi một số học động không tiêu chuẩn. Đây là một hệ thống cứng (stiff) phức tạp. Mỗi lần gọi likelihood cần giải các ODE này, tính toán khoảng cách cộng đồng và đánh định khoảng cách mô đun tại độ đỏ của 30 siêu tân tinh.
Sau khi đo lường hiệu năng (profiling), tôi nhận thấy việc giải ODE một mình đã tốn 0,4 ms cho mỗi lần gọi. Trong một lượt chạy nested sampling với 10^5 lần đánh giá, đó là 40 giây — chỉ tính riêng việc giải ODE, chưa kể các chi phí quản lý khác.
Tệ hơn, với một mô hình có 10 tham số, việc lấy gradient thông qua sai phân hữu hạn trung tâm (central finite differences) tốn thêm 20 lần giải xuôi (forward solves). Điều này biến 0,4 ms thành 8 ms cho mỗi gradient. Tổng cộng là 300 giây, hay khoảng 5 phút, chỉ để tính gradient cho một lượt chạy duy nhất.
Đã đến lúc phải thay đổi.
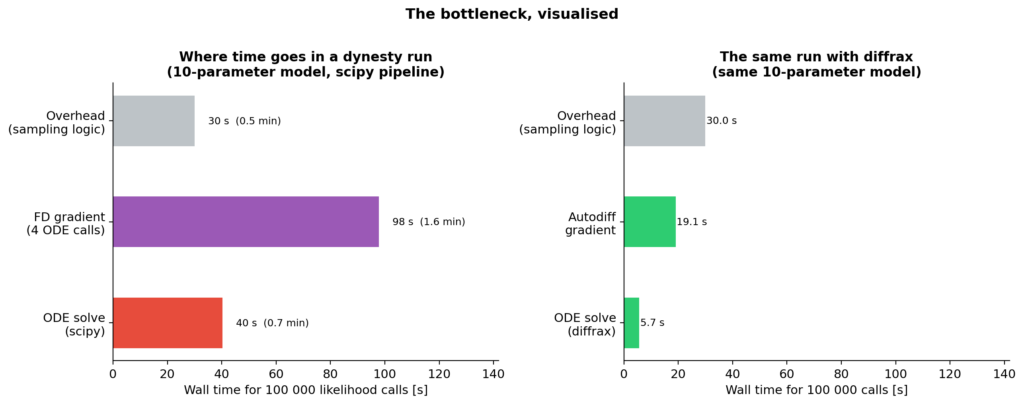 Phân tích thời gian chạy trong dynesty
Phân tích thời gian chạy trong dynesty
Giải pháp tôi tìm thấy: Diffrax
Sau một ngày tìm kiếm, tôi đã tìm thấy Diffrax — một thư viện bộ giải ODE số được viết hoàn toàn bằng JAX. Không phải là mạng nơ- thay thế, không phải là sự xấp xỉ. Đó là cùng các thuật toán Runge–Kutta nhúng mà tôi đã dùng trong SciPy (Tsit5 thay vì RK45), nhưng được biên dịch, có thể vi phân (differentiable) và vector hóa.
Ba thuộc tính chính xuất phát từ thiết kế "viết hoàn toàn bằng JAX" bao gồm:
- Biên dịch JIT (JIT compilation): Toàn bộ vòng lặp thích ứng bước (adaptive-stepping loop) được biên dịch thành một nhân XLA duy nhất. Gần như không có chi phí overhead của Python sau lần gọi đầu tiên.
- Tự động vi phân (Autodiff): Vì mọi thao tác bên trong bộ giải đều là nguyên thủy của JAX,
jax.gradsẽ lan truyền gradient thông qua quá trình giải. Đây là gradient chính xác với duy nhất một lượt chạy ngược, bất kể số lượng tham số. - Vector hóa (vmap): Một lô (batch) các vector tham số có thể được giải song song bằng
jax.vmap.
Cài đặt nó chỉ mất 10 giây: pip install jax diffrax.
Cách cũ: SciPy
Với bài toán tính toán khoảng cách cộng động trong mô hình Vũ trụ phẳng ΛCDM, mã code truyền thống của tôi trông như sau:
from scipy.integrate import solve_ivp
import numpy as np
C_KMS = 299792.458 # tốc độ ánh sáng [km/s]
def rhs(z, chi, Om, H0):
return C_KMS / (H0 * np.sqrt(Om*(1+z)**3 + (1-Om)))
def forward_scipy(Om, H0, z_obs):
sol = solve_ivp(rhs, t_span=(0, z_obs[-1]),
y0=[0.0], t_eval=z_obs,
args=(Om, H0), method="RK45",
rtol=1e-8, atol=1e-10)
chi = sol.y[0]
return 5 * np.log10((1 + z_obs) * chi * 1e5)
Cách mới: Diffrax
Bây giờ, hãy xem cách triển khai bằng Diffrax:
import jax, jax.numpy as jnp
import diffrax as dfx
# Bắt buộc: bật 64-bit (xem chi tiết bên dưới)
jax.config.update("jax_enable_x64", True)
def H_jax(z, Om, H0):
return H0 * jnp.sqrt(Om*(1+z)**3 + (1-Om))
@jax.jit # biên dịch một lần, gọi nhanh mãi mãi
def forward_diffrax(theta, z_obs):
Om, H0 = theta[0], theta[1]
sol = dfx.diffeqsolve(
dfx.ODETerm(lambda z, chi, a: C_KMS / H_jax(z, a[0], a[1])),
dfx.Tsit5(),
t0=0.0, t1=float(z_obs[-1]), # giá trị ban đầu và cuối cùng
dt0=1e-3, # kích thước bước ban đầu
y0=jnp.array(0.0), # điều kiện ban đầu
args=(Om, H0),
saveat=dfx.SaveAt(ts=z_obs),
stepsize_controller=dfx.PIDController(rtol=1e-8, atol=1e-10),
max_steps=10_000,
)
chi = sol.ys
return 5 * jnp.log10((1 + z_obs) * chi * 1e5)
Vật lý thì hoàn toàn giống nhau. Thuật toán bộ giải cũng gần như giống hệt nhau (Tsit5 rất tương đồng với RK45). Sự khác biệt duy nhất về cấu trúc là @jax.jit và API của diffrax.
Ngạc nhiên thứ nhất: Tốc độ
solve_ivp: 404 µs mỗi lần gọi.diffraxsau JIT: 59 µs mỗi lần gọi.- Tức là nhanh hơn ~7 lần.
Tôi đã nhìn chằm chằm vào con số này vài giây khi lần đầu thấy nó. Sự gia tốc này không phải phép thuật, nó đến từ cách xử lý của Python.
Trong solve_ivp, Python phải quay lại backend C/Cython trong mỗi lần gọi. Bộ nhớ được cấp phát mới mỗi lần. Vòng lặp while thích ứng đi qua thông dịch viên Python để kiểm tra sai số: "Sai số cục bộ có quá lớn không? từ chối; nếu không thì tăng bước; lặp lại". Với một bài toán giải 12 bước, đó là 12 vòng phân phối Python, 12 lần cấp phát bộ nhớ.
Trong diffrax, lần gọi @jax.jit đầu tiên sẽ truy vết toàn bộ tính toán — bao gồm cả vòng lặp while thích ứng, được hạ cấp xuống lax.while_loop và đưa cho XLA biên dịch thành nhân mã máy. Mọi lần gọi sau đó thực thi nhân đó trực tiếp. Không còn Python, không cần cấp phát bộ nhớ, không cần phân phối.
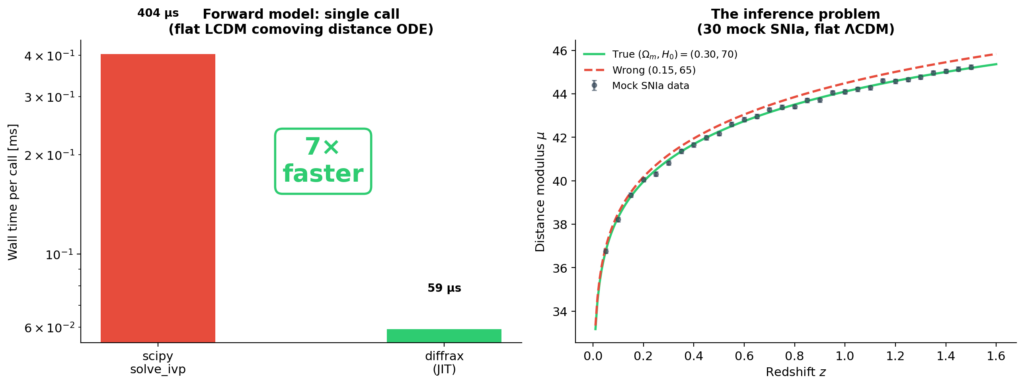 So sánh tốc độ giữa SciPy và Diffrax
So sánh tốc độ giữa SciPy và Diffrax
Với 100.000 lần đánh định likelihood, 404 µs so với 59 µs tương đương với 40,4 giây so với 5,9 giây.
Ngạc nhiên thứ hai: Gradient trở nên "miễn phí"
Đây là phần thay đổi không chỉ quy trình làm việc của tôi mà còn cả cách tôi suy nghĩ về suy luận. Với scipy, để lấy một gradient của log-likelihood đối với 2 tham số (Ωₘ, H₀) thông qua sai phân hữu hạn trung tâm, tôi tốn 4 lần giải xuôi. Khi số tham số tăng lên, chi phí tăng tuyến tính.
Với diffrax, tôi chỉ cần viết:
def loss(theta):
mu_pred = forward_diffrax(theta, z_obs)
return 0.5 * jnp.sum(((mu_pred - mu_obs) / sigma_mu)**2)
grad_fn = jax.jit(jax.grad(loss)) # đây là toàn bộ thay đổi cần thiết
g = grad_fn(jnp.array([0.3, 70.0])) # gradient chính xác
Dưới lớp vỏ bọc, JAX autodiff chế độ ngược (reverse-mode) sẽ tích hợp các phương trình adjoint ngược thông qua quá trình giải ODE — nhưng tôi không bao giờ phải viết các phương trình đó. Kết quả là một gradient chính xác với thời gian tương đương một lượt chạy xuôi, độc lập với số lượng tham số.
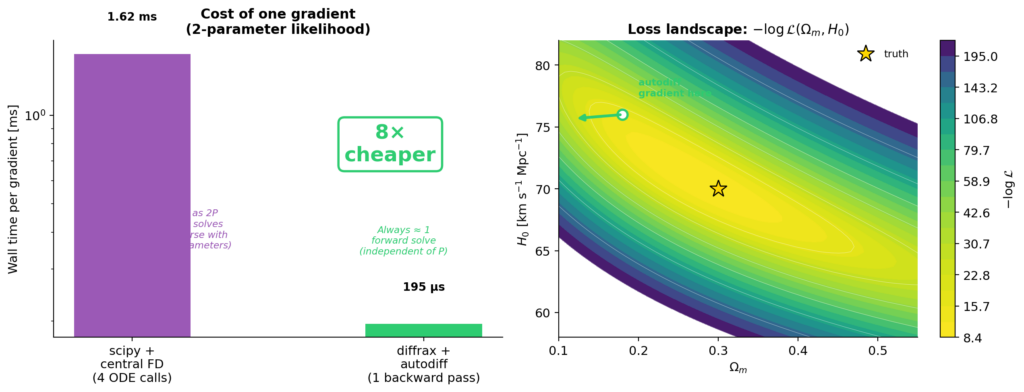 So sánh chi phí gradient giữa SciPy và Diffrax
So sánh chi phí gradient giữa SciPy và Diffrax
Cách chọn bộ giải và những sai lầm cần tránh
Khi chọn bộ giải, bạn cần cẩn thận một chút. Tôi mặc định dùng Tsit5 cho hầu hết mọi thứ và nó xử lý tốt khoảng 95% vấn đề.
- ODE không cứng (Non-stiff) ->
dfx.Tsit5()(bắt đầu từ đây). - ** dung sai rất chặt hoặc chính xác cao** ->
dfx.Dopri8(). - ODE cứng (Stiff) ->
dfx.Kvaerno5()hoặcdfx.Radau().
Tuy nhiên, khi chuyển đổi, tôi đã mắc phải 3 lỗi phổ biến:
- Sử dụng float 32-bit mặc định: JAX mặc định dùng float32, nhưng đây là thảm họa cho tích phân ODE cosmology. Hãy luôn bật
jax_enable_x64. - Bỏ qua JIT warm-up: Lần gọi JIT đầu tiên luôn chậm vì phải biên dịch. Hãy chạy một lượt "giả" trước khi đo thời gian.
- Quên Stepsize Controller: Đừng chỉ dùng dt0 cố định. Hãy dùng
PIDControllervới rtol/atol thích hợp để kiểm soát lỗi.
Kết luận
Việc chuyển đổi mô hình xuôi (forward model) sang diffrax không thay đổi vật lý hay phương pháp suy luận. Nó thay đổi tính khả thi về mặt thực tế của việc thực hiện suy luận đó. Một lượt chạy nested-sampling vốn tốn nhiều thời gian nay chỉ mất chưa đến một phút. Những gradient vốn tốn 20 lần giải thêm mỗi bước giờ trở nên miễn phí.
Đường cong học tập chỉ mất một buổi chiều. Việc debug chủ yếu là lưu ý về 64-bit và sự nhầm lẫn về warm-up của JIT. Lợi ích nhận được là thật và tức thì. Nếu bạn là một nhà vật lý dùng scipy cho các lần đánh định likelihood lặp đi lặp lại và chưa từng xem xét diffrax, tôi hy vọng bài viết này đã cho bạn một lý do để làm điều đó.
Bài viết liên quan

Phần mềm
Pyroscope 2.0 của Grafana: Đưa Continuous Profiling trở nên thực tế ở quy mô lớn
13 tháng 5, 2026

Phần mềm
Apple ra mắt Siri AI: Trợ lý ảo thế hệ mới thông minh hơn và thấu hiểu bạn hơn
08 tháng 6, 2026
Phần mềm
Mô hình Diffusion "Training-Free": Tạo ảnh chất lượng cao từ một mẫu duy nhất trong tích tắc
07 tháng 6, 2026