
Tại sao bạn không cần hàng ngàn nhãn dữ liệu để huấn luyện AI?
Bài viết khám phá cách sử dụng mô hình Gaussian Mixture Variational Autoencoder (GMVAE) để giảm thiểu lượng nhãn dữ liệu cần thiết trong học máy. Kết quả cho thấy một mô hình đã học cấu trúc dữ liệu không giám sát có thể trở thành bộ phân loại mạnh mẽ chỉ với 0,2% dữ liệu có nhãn.

Học có giám sát (Supervised learning) thường đi kèm với một giả định ngầm định: bạn cần rất nhiều dữ liệu được gán nhãn. Tuy nhiên, thực tế cho thấy nhiều mô hình có khả năng tự khám phá cấu trúc của dữ liệu mà hoàn toàn không cần bất kỳ nhãn nào.
Các mô hình sinh (generative models), đặc biệt là những mô hình làm việc với hình ảnh, thường có khả năng tự tổ chức dữ liệu thành các cụm có ý nghĩa trong quá trình huấn luyện không giám sát. Điều này đặt ra một câu hỏi quan trọng: Nếu mô hình đã nắm bắt được cấu trúc của dữ liệu, thì chúng ta thực sự cần bao nhiêu sự giám sát để biến nó thành một bộ phân loại (classifier)?
Trong bài viết này, chúng ta sẽ cùng đi sâu vào câu hỏi này thông qua mô hình Gaussian Mixture Variational Autoencoder (GMVAE).
 Mô hình GMVAE
Mô hình GMVAE
Bộ dữ liệu EMNIST Letters
Để kiểm chứng, chúng ta sử dụng bộ dữ liệu EMNIST Letters, một phiên bản mở rộng của bộ dữ liệu MNIST kinh điển. EMNIST bao gồm 145.600 hình ảnh chữ cái viết tay (26 lớp cân bằng). Lý do chúng ta chọn EMNIST thay vì MNIST là do nó mơ hồ hơn nhiều, giúp làm nổi bật tầm quan trọng của các biểu diễn xác suất trong mô hình.
GMVAE: Học cấu trúc theo cách không giám sát
Một Variational Autoencoder (VAE) tiêu chuẩn là mô hình sinh học cách biểu diễn tiềm ẩn (latent representation) liên tục của dữ liệu. Tuy nhiên, với một prior Gauss tiêu chuẩn, không gian tiềm ẩn có xu hướng liên tục và không tự tách biệt thành các nhóm riêng biệt.
Đây chính là lúc GMVAE phát huy tác dụng. GMVAE mở rộng VAE bằng cách thay thế prior bằng một hỗn hợp của K thành phần. Điều này cho phép mô hình học được một phân phối hậu nghiệm trên các cụm. Về cơ bản, GMVAE tự học cách phân cụm dữ liệu trong quá trình huấn luyện.
Trong thí nghiệm này, chúng ta chọn K = 100. Con số này đủ lớn để bắt lấy các biến thể về phong cách viết trong mỗi lớp chữ cái, nhưng cũng đủ nhỏ để đảm bảo mỗi cụm được đại diện đầy đủ trong tập dữ liệu có nhãn.
Các mẫu từ GMVAE
Hình trên cho thấy các mẫu được tạo ra từ một số thành phần của GMVAE. Các biến thể phong cách khác nhau của cùng một chữ cái được bắt giữ, ví dụ như chữ F hoa và chữ f thường. Tuy nhiên, các cụm không hoàn toàn tinh khiết; ví dụ, thành phần c=73 chủ yếu đại diện cho chữ "T" nhưng cũng bao gồm mẫu của chữ "J".
Biến các cụm thành bộ phân loại
Sau khi GMVAE được huấn luyện, mỗi hình ảnh sẽ được liên kết với một phân phối xác suất trên các cụm. Để kết nối các cụm này với các nhãn thực tế, chúng ta cần một tập con dữ liệu đã được gán nhãn.
Chúng ta so sánh hai cách tiếp cận để gán nhãn cho dữ liệu còn lại:
1. Giải mã cứng (Hard Decoding)
Cách tiếp cận này gán mỗi dữ liệu cho một cụm duy nhất. Cụ thể, chúng ta gán cho mỗi cụm một nhãn duy nhất dựa trên nhãn xuất hiện nhiều nhất trong các điểm dữ liệu có nhãn thuộc cụm đó.
Sau đó, với một hình ảnh chưa có nhãn, chúng ta gán nó cho cụm có khả năng cao nhất và gán nhãn của cụm đó cho nó.
Tuy nhiên, phương pháp này có hai hạn chế lớn:
- Nó bỏ qua sự không chắc chắn của mô hình (GMVAE có thể "do dự" giữa nhiều cụm).
- Nó giả định rằng các cụm là tinh khiết (mỗi cụm chỉ tương ứng với một nhãn), điều này thường không đúng.
2. Giải mã mềm (Soft Decoding)
Thay vì giả định mỗi cụm tương ứng với một nhãn duy nhất, giải mã mềm sử dụng tập con có nhãn để ước tính một vectơ xác suất cho mỗi nhãn. Sau đó, nó gán cho hình ảnh nhãn l mà tối đa hóa sự tương tự giữa vectơ xác suất của nhãn đó và vectơ posterior của hình ảnh.
Phương pháp này giải quyết được hai vấn đề của giải mã cứng:
- Nó sử dụng toàn bộ phân phối posterior thay vì chỉ lấy giá trị lớn nhất.
- Nó cho phép mỗi nhãn được liên kết với nhiều cụm, chấp nhận việc các cụm không tinh khiết.
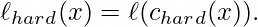 So sánh Hard và Soft Decoding
So sánh Hard và Soft Decoding
Hình trên minh họa một ví dụ cụ thể nơi giải mã mềm phát huy tác dụng. Nhãn đúng là "e". Mô hình phân phối xác suất cho các cụm. Giải mã cứng chỉ chọn cụm có xác suất cao nhất (cụm 76), vốn chủ yếu liên kết với nhãn "c", dẫn đến dự đoán sai. Ngược lại, giải mã mềm tổng hợp thông tin từ tất cả các cụm hợp lý và dự đoán đúng là "e".
Cần bao nhiêu nhãn trong thực tế?
Vậy hiệu quả thực tế của các phương pháp này như thế nào? Chúng ta dần tăng số lượng mẫu có nhãn và đánh giá độ chính xác.
Kết quả cho thấy ngay cả với các tập con có nhãn cực nhỏ, bộ phân loại đã hoạt động vượt trội. Đáng chú ý nhất, giải mã mềm cải thiện hiệu suất đáng kể khi dữ liệu giám sát khan hiếm.
Với chỉ 73 mẫu có nhãn (tương ứng 0,05% dữ liệu), giải mã mềm mang lại mức tăng độ chính xác tuyệt đối khoảng 18 điểm phần trăm so với giải mã cứng.
Hơn nữa, với chỉ 0,2% dữ liệu có nhãn (291 mẫu trên tổng số 145.600), bộ phân loại dựa trên GMVAE đã đạt độ chính xác 80%. Trong khi đó, XGBoost cần khoảng 7% dữ liệu có nhãn (gấp 35 lần nhiều hơn) để đạt hiệu suất tương đương.
Kết luận
Sử dụng GMVAE được huấn luyện hoàn toàn không có nhãn, chúng ta thấy rằng một bộ phân loại có thể được xây dựng chỉ với ít nhất 0,2% dữ liệu có nhãn. Quan sát chính là mô hình không giám sát đã học được phần lớn cấu trúc cần thiết cho việc phân loại.
Các nhãn không được sử dụng để xây dựng biểu diễn từ đầu, mà chỉ được dùng để "đặt tên" cho các cụm mà mô hình đã phát hiện ra. Thí nghiệm này làm nổi bật một mô hình hứa hẹn cho học máy tiết kiệm nhãn (label-efficient machine learning): học cấu trúc trước, thêm nhãn sau.
Điều này gợi ý rằng trong nhiều trường hợp, chúng ta không cần nhãn để học — chỉ cần nhãn để gọi tên những gì đã được học.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026