
Tại sao Chunking là quyết định quan trọng nhất trong hệ thống RAG của bạn?
Bài viết phân tích cách chiến lược chia nhỏ văn bản (chunking) không phù hợp có thể dẫn đến những thất bại thầm lặng và câu trả lời sai lệch trong hệ thống RAG. Tác giả khám phá các chiến lược khác nhau như chia theo kích thước cố định, cửa sổ câu, phân cấp và ngữ nghĩa, cùng cách xử lý các định dạng phức tạp như PDF và bảng biểu.
Ba tuần sau khi chúng tôi triển khai phiên bản đầu tiên của cơ sở kiến thức nội bộ, tôi nhận được một tin nhắn Slack từ đồng nghiệp trong đội tuân thủ (compliance team). Cô ấy đã hỏi hệ thống về quy trình tiếp nhận nhà thầu của chúng tôi. Câu trả lời rất tự tin, được cấu trúc tốt, nhưng lại sai một cách cơ bản nhất đối với công việc tuân thủ: nó mô tả quy trình chung nhưng lại bỏ qua điều khoản ngoại lệ áp dụng cho các nhà thầu trong các dự án được kiểm soát.
Điều khoản ngoại lệ đó nằm trong tài liệu. Nó đã được đưa vào hệ thống. Mô hình nhúng (embedding model) đã mã hóa nó. LLM, nếu được cung cấp đúng ngữ cảnh, sẽ xử lý nó mà không do dự. Nhưng hệ thống truy xuất không bao giờ tìm thấy nó vì đoạn văn (chunk) chứa ngoại lệ đó đã bị chia ngay tại ranh giới đoạn văn nơi quy tắc chung kết thúc và điều kiện bắt đầu.
 Hình ảnh minh họa vấn đề chunking
Hình ảnh minh họa vấn đề chunking
Tôi nhớ là đã mở nhật ký chunk và nhìn chằm chằm vào hai bản ghi liên tiếp. Bản ghi đầu tiên kết thúc giữa chừng một lập luận: "Nhà thầu tuân theo quy trình tiếp nhận tiêu chuẩn như được mô tả trong Mục 4..." Bản ghi thứ hai bắt đầu theo một cách không có nghĩa nếu không có tiền nhiệm của nó: "...trừ khi được tham gia vào một dự án được phân loại theo Phụ lục B, trong trường hợp đó...". Mỗi chunk, khi đứng riêng lẻ, là một mảnh vỡ. Nhưng khi cùng nhau, chúng chứa một thông tin quan trọng hoàn chỉnh. Khi tách biệt, không chunk nào có thể được truy xuất một cách có ý nghĩa.
Đó là lúc tôi ngừng coi việc chia nhỏ văn bản (chunking) là một chi tiết cấu hình và bắt đầu coi đó là quyết định thiết kế quan trọng nhất trong toàn bộ stack công nghệ.
Chunking là gì và tại sao các kỹ sư thường đánh giá thấp nó
Trong bài viết trước, tôi đã mô tả chunking là "bước mà hầu hết các đội nhóm đều làm sai". Một pipeline RAG không truy xuất tài liệu; nó truy xuất các chunk. Mọi câu trả lời mà hệ thống của bạn tạo ra đều được tạo ra từ một hoặc nhiều đơn vị này, không phải từ toàn bộ tài liệu nguồn, không phải từ bản tóm tắt, mà từ mảnh cụ thể mà hệ thống truy xuất thấy đủ liên quan để chuyển cho mô hình.
Hình dạng của mảnh fragment đó quyết định mọi thứ ở hạ nguồn.
Một chunk quá lớn chứa nhiều ý tưởng: vector nhúng đại diện cho nó là trung bình của tất cả chúng, và không có ý tưởng nào đủ sắc bén để thắng trong cuộc cạnh tranh truy xuất. Một chunk quá nhỏ thì chính xác nhưng bị cô lập: một câu không có đoạn văn xung quanh thường không thể giải thích được, và mô hình không thể tạo ra câu trả lời mạch lạc từ một mảnh vỡ. Một chunk cắt qua một ranh giới logic sẽ tạo ra "ngoại lệ nhà thầu": thông tin hoàn chỉnh bị chia thành hai mảnh không hoàn chỉnh, mỗi mảnh trông có vẻ không liên quan khi đứng riêng lẻ.
Chunking nằm ở thượng nguồn của mọi mô hình trong stack của bạn. Mô hình nhúng không thể sửa chữa một chunk tồi. Bộ re-ranker không thể tìm lại một chunk chưa bao giờ được truy xuất. LLM không thể trả lời từ ngữ cảnh mà nó chưa bao giờ nhận được.
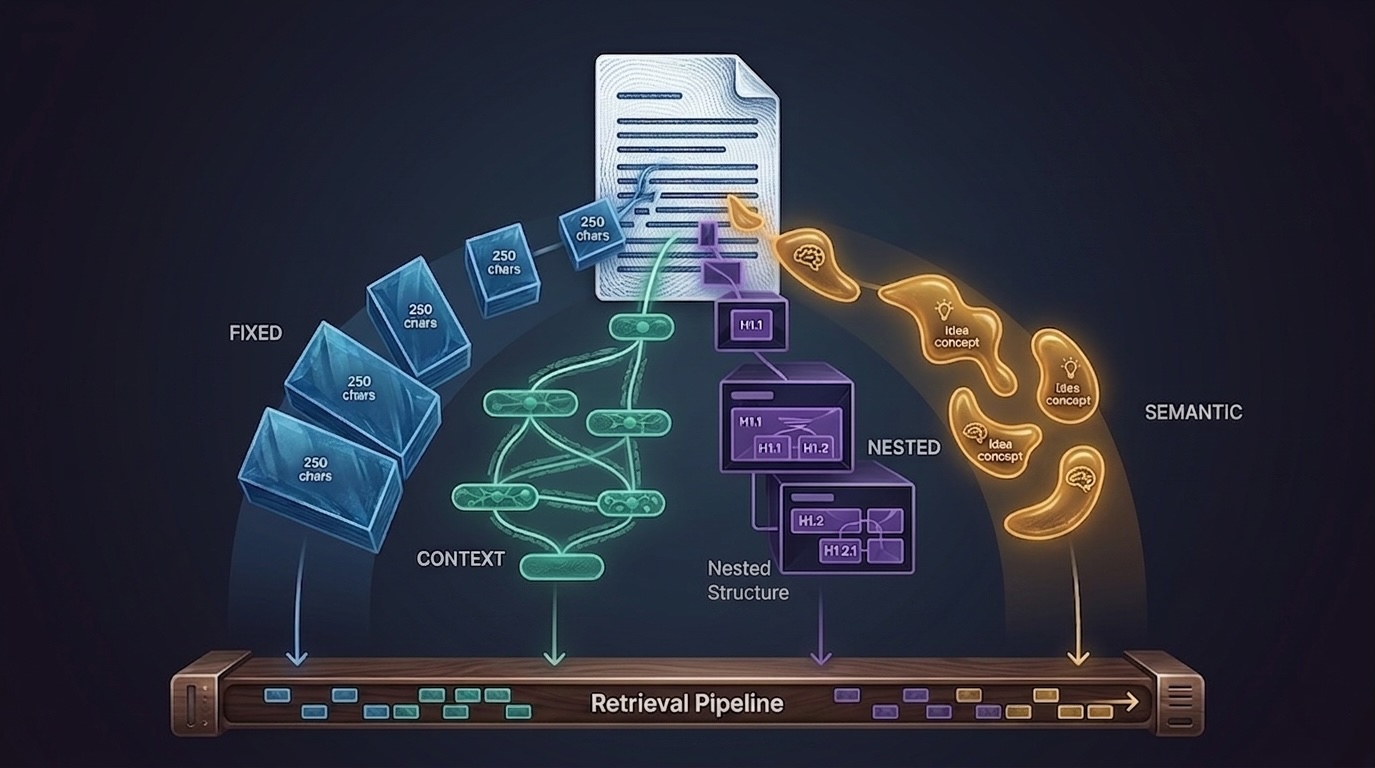
 Các chiến lược Chunking khác nhau
Các chiến lược Chunking khác nhau
Lý do nó bị đánh giá thấp là vì nó thất bại một cách thầm lặng. Một lần truy xuất thất bại không ném ra ngoại lệ (exception). Nó tạo ra một câu trả lời gần đúng, hợp lý, trôi chảy, và sai lệch một cách tinh tế theo cách quan trọng nhất. Trong một bản demo, với các truy vấn được chọn bằng tay, gần đúng là ổn. Trong môi trường sản xuất (production), với đầy đủ các câu hỏi thực tế của người dùng, đó là sự xói mòn niềm tin chậm chạp.
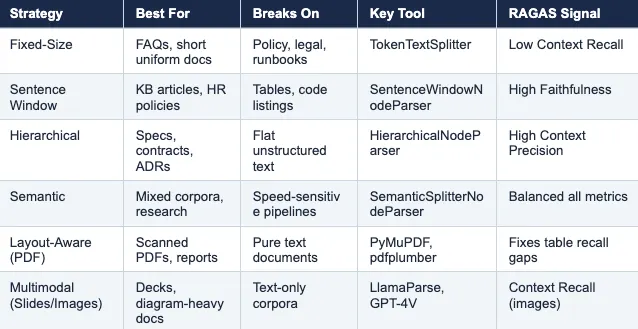
Vết nứt đầu tiên: Fixed-Size Chunking (Chunking kích thước cố định)
Chúng tôi bắt đầu như hầu hết các đội nhóm khác: chunking kích thước cố định. Chia mọi tài liệu thành các cửa sổ 512-token, chồng chéo 50-token. Nó mất một buổi chiều để thiết lập. Các bản demo ban đầu trông ổn. Không ai đặt câu hỏi.
Logic thì trực quan. Các mô hình nhúng có giới hạn token. Tài liệu thì dài. Chia chúng thành các cửa sổ cố định và bạn có một chỉ mục nhất quán, đồng nhất. Sự chồng chéo đảm bảo rằng thông tin vượt biên giới có cơ hội thứ hai. Đơn giản, nhanh chóng và hoàn toàn thờ ơ với việc văn bản thực đang nói cái gì.
Phần "hoàn toàn thờ ơ với việc văn bản thực đang nói cái gì" chính là vấn đề. Kích thước cố định không biết đâu là kết thúc của một câu, hoặc rằng một ngoại lệ chính sách ba đoạn văn nên được giữ lại với nhau, hoặc rằng việc chia một danh sách đánh số ở bước bốn sẽ tạo ra hai mảnh vỡ vô dụng.
Khi chunking kích thước cố định hoạt động tốt: Các tài liệu ngắn, đồng nhất nơi mọi phần tự chứa đựng thông tin như FAQ sản phẩm, tóm tắt tin tức, mô tả vé hỗ trợ.
Thông minh hơn: Sentence Windows (Cửa sổ câu)
Vấn đề ngoại lệ nhà thầu, khi tôi hiểu rõ nó, đã chỉ thẳng vào những gì cần thiết: một cách để truy xuất ở độ chính xác của một câu duy nhất, nhưng tạo sinh với ngữ cảnh của một đoạn văn đầy đủ. Không phải cái này hay cái kia, mà là cả hai, ở các giai đoạn khác nhau của pipeline.
LlamaIndex SentenceWindowNodeParser được xây dựng chính xác cho việc này. Tại thời điểm lập chỉ mục, nó tạo ra một node cho mỗi câu. Mỗi node mang câu đó làm văn bản có thể truy xuất, nhưng lưu trữ cửa sổ câu xung quanh (mặc định là ba câu mỗi bên) trong siêu dữ liệu (metadata) của nó. Tại thời điểm truy vấn, bộ truy xuất tìm thấy câu phù hợp nhất. Tại thời điểm tạo sinh, một bộ xử lý hậu kỳ (post-processor) mở rộng nó trở lại cửa sổ trước khi ngữ cảnh đến được LLM.
Ngoại lệ tuân thủ vốn vô hình với pipeline kích thước cố định đã có thể truy xuất được ngay lập tức. Câu "trừ khi được tham gia vào một dự án được phân loại theo Phụ lục B" được đánh giá cao về điểm số liên quan vì nó chứa chính xác thông tin đó, không bị pha loãng. Việc mở rộng cửa sổ sau đó cung cấp cho LLM ba câu trước và sau nó, cung cấp ngữ cảnh để tạo ra câu trả lời hoàn chỉnh và chính xác.
Khi tài liệu của bạn có cấu trúc: Hierarchical Chunking (Chunking phân cấp)
Kho tài liệu kỹ thuật của chúng tôi: bản ghi quyết định kiến trúc, tài liệu thiết kế hệ thống, thông số kỹ thuật API trông hoàn toàn khác với các tệp chính sách nhân sự. Trong khi tài liệu nhân sự là văn xuôi trôi chảy, tài liệu kỹ thuật có cấu trúc: các phần có tiêu đề, tiểu mục có các bước đánh số, bảng tham số, ví dụ mã. Cách tiếp cận cửa sổ câu hoạt động đẹp mắt với văn bản chính sách lại tạo ra kết quả kém cỏi với những cái này.
Giải pháp rõ ràng khi tôi đặt vấn đề đúng cách: truy xuất ở độ chi tiết đoạn văn, nhưng tạo sinh với ngữ cảnh cấp phần. Đoạn văn đủ cụ thể để thắng trong cuộc cạnh tranh truy xuất. Phần đủ hoàn chỉnh để LLM có thể suy luận từ đó.
AutoMergingRetriever là thứ làm cho điều này trở nên thực tế. Nếu nó truy xuất đủ các node lá cùng cha từ cùng một cha, nó tự động thăng cấp chúng lên node cha. Bạn không mã hóa cứng "truy xuất đoạn văn, trả về phần" — mẫu truy xuất sẽ thúc đẩy quyết định về độ chi tiết tại thời điểm chạy.
Tùy chọn hấp dẫn: Semantic Chunking (Chunking ngữ nghĩa)
Sau chunking phân cấp, tôi đã tìm thấy semantic chunking và trong một hoặc hai ngày, tôi tin rằng mình đã làm mọi thứ sai từ đầu. Ý tưởng rất sạch sẽ: thay vì áp đặt các ranh giới dựa trên số lượng token hoặc cấu trúc tài liệu, bạn để mô hình nhúng phát hiện ra nơi chủ đề thực sự thay đổi. Khi khoảng cách ngữ nghĩa giữa các câu liền kề vượt qua ngưỡng, đó là điểm cắt của bạn.
Về lý thuyết, đây là sự trừu tượng đúng đắn. Trên thực tế, nó giới thiệu hai vấn đề quan trọng trong môi trường sản xuất.
Thứ nhất là độ trễ lập chỉ mục. Semantic chunking yêu cầu nhúng mọi câu trước khi nó có thể xác định một ranh giới duy nhất. Với kho tài liệu 50.000 tài liệu, đây không phải là công việc một buổi chiều.
Thứ hai là độ nhạy cảm của ngưỡng. Giá trị breakpoint_percentile_threshold kiểm soát mức độ cắt mạnh của bộ phân tích. Ở mức 95, nó hiếm khi cắt và tạo ra các chunk lớn. Ở mức 80, nó cắt thường xuyên và tạo ra các mảnh vỡ.
Vấn đề ít người nói đến: PDF, Bảng biểu và Slides
Mọi thứ tôi mô tả cho đến nay đều giả định rằng tài liệu của bạn là văn bản sạch, được định dạng tốt. Trong thực tế, cơ sở kiến thức doanh nghiệp đầy rẫy những thứ không phải là văn bản sạch. Đó là PDF được quét với bố cục hai cột. Đó là các bảng tính nơi thông tin quan trọng nhất nằm trong một bảng. Đó là các bộ slide PowerPoint nơi thông tin then chốt là một sơ đồ với chú thích.
Không có chiến lược nào ở trên xử lý được các trường hợp này.
Bảng biểu: Hố đen của truy xuất
Bảng biểu là nguyên nhân phổ biến nhất gây ra các thất bại truy xuất thầm lặng trong hệ thống RAG doanh nghiệp. Lý do rất đơn giản: bảng là một cấu trúc hai chiều trong một biểu diễn một chiều. Khi bạn làm phẳng một bảng thành văn bản, các quan hệ hàng-cột biến mất, và những gì bạn nhận được là một chuỗi các giá trị về cơ bản không thể giải thích được nếu không có ngữ cảnh của các tiêu đề.
Cách tiếp cận hiệu quả đối với chúng tôi là coi bảng như một loại trích xuất riêng biệt và tái tạo chúng dưới dạng các mô tả ngôn ngữ tự nhiên trước khi lập chỉ mục. Đối với mỗi hàng bảng, tạo ra một câu mã hóa hàng đó dưới dạng có thể đọc được, bảo toàn mối quan hệ giữa các giá trị và tiêu đề.
Slide và tài liệu nhiều hình ảnh
Các bộ slide PowerPoint và bản trình bày PDF là một thách thức đặc biệt vì thông tin có ý nghĩa nhất thường không nằm trong văn bản. Một slide có tiêu đề "Quyết định kiến trúc Q3" và sơ đồ cho thấy các phụ thuộc dịch vụ mang phần lớn ý nghĩa trong sơ đồ đó, không phải trong sáu gạch đầu dòng bên dưới.
Đối với các sơ đồ, ảnh chụp màn hình và slide nhiều hình ảnh, việc trích xuất văn bản đơn thuần là không đủ. Các tùy chọn thực tế là: sử dụng mô hình đa phương thức (multimodal) để tạo mô tả hình ảnh tại thời điểm lập chỉ mục, hoặc sử dụng LlamaParse.
Khung quyết định, không phải bảng xếp hạng
Đến lúc tôi đã làm việc qua tất cả những điều này, tôi đã ngừng nghĩ về các chiến lược chunking như một danh sách xếp hạng nơi cái nào là "tốt nhất". Câu hỏi đúng không phải là "chiến lược nào tinh vi nhất?", mà là "chiến lược nào phù hợp với loại tài liệu này?". Và trong hầu hết các kho doanh nghiệp, câu trả lời là khác nhau cho các loại tài liệu khác nhau.
Logic định tuyến (routing) mà chúng tôi kết thúc rất đơn giản để thực hiện trong một buổi chiều và nó tạo ra sự khác biệt có thể đo lường được trên toàn bộ.
RAGAS nói gì về Chunks của bạn
Mọi thứ tôi mô tả ở trên — ngoại lệ nhà thầu, sự cải thiện ngữ cảnh truy xuất, các thất bại truy xuất bảng — tôi chỉ có thể định lượng được vì tôi đã chạy RAGAS từ sớm trong dự án. Nếu không có nó, tôi sẽ đang gỡ lỗi bằng trực giác, sửa các truy vấn tôi tình cờ nhận thấy và bỏ lỡ những cái tôi không thấy.
Trong bối cảnh chunking cụ thể, bốn chỉ số cốt lõi mỗi chỉ số chẩn đoán một chế độ thất bại khác nhau:
- Context Recall thấp: Vấn đề truy xuất (thiếu thông tin).
- Context Precision thấp: Vấn đề chunking (thu hồi quá nhiều nhiễu).
- Faithfulness thấp: Vấn đề tạo sinh (mô hình bị ảo giác).
Mẫu đầu tiên cho tôi thấy chunking kích thước cố định đang thất bại là điểm số Context Recall là 0.72 cùng với điểm số Faithfulness là 0.86. Mô hình đang dựa đúng vào những gì nó nhận được. Vấn đề là những gì nó nhận được không hoàn chỉnh.
Kết luận
Đồng nghiệp tuân thủ của tôi không bao giờ biết rằng tin nhắn Slack của cô ấy là sự khởi đầu của nhiều tuần làm việc về chunking. Về phía cô ấy, hệ thống chỉ bắt đầu đưa ra câu trả lời tốt hơn sau vài tuần. Về phía tôi, tin nhắn đó là phản hồi hữu ích nhất tôi nhận được trong toàn bộ dự án — không phải vì nó nói cho tôi biết phải xây dựng cái gì, mà vì nó nói cho tôi biết nơi tôi đã sai.
Khoảng cách giữa trải nghiệm người dùng và thực tế kỹ thuật là lý do chunking dễ bị đánh giá thấp đến vậy. Khi nó thất bại, người dùng không gửi vé phàn nàn về "ngữ cảnh truy xuất kém tại K=5". Họ lặng lẽ ngừng tin tưởng vào hệ thống. Và đến lúc bạn nhận thấy sự sụt giảm trong việc sử dụng, vấn đề đã ở đó từ nhiều tuần trước.
Chunking không phải là kỹ thuật hoa mỹ. Nó không tạo ra những bài thuyết trình hội nghị ấn tượng. Nhưng nó là lớp quyết định xem mọi thứ ở trên nó — mô hình nhúng, bộ truy xuất, re-ranker, LLM — có cơ hội hoạt động hay không. Làm đúng nó, đo lường nó nghiêm ngặt, và phần còn lại của pipeline sẽ có một nền tảng đáng để xây dựng trên đó.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026