
Tại sao Polars lại nhanh hơn Pandas: Nghiên cứu trên tập dữ liệu 10 triệu dòng
Nghiên cứu mới đây đã so sánh hiệu suất giữa hai thư viện xử lý dữ liệu phổ biến là Pandas và Polars trên tập dữ liệu 10 triệu dòng. Kết quả cho thấy Polars vượt trội rõ rệt nhờ kiến trúc đa luồng và cơ chế lazy evaluation, đạt tốc độ xử lý nhanh gấp 3 lần so với đối thủ.

Trong các pipeline dữ liệu hiện đại, các nút thắt cổ chai về hiệu suất thường không chỉ đến từ thuật toán, mà còn bắt nguồn từ chính những công cụ chúng ta sử dụng hàng ngày. Các thư viện Python như Pandas từ lâu đã là "xương sống" của xử lý dữ liệu, nhưng những đối thủ mới nổi như Polars đang thách thức vị thế này với những tuyên bố về hiệu suất vượt trội.
Pandas đã là lựa chọn mặc định của các kỹ sư dữ liệu trong suốt hơn một thập kỷ qua. Tuy nhiên, liệu đó có còn là lựa chọn tốt nhất trong kỷ nguyên dữ liệu lớn (Big Data) ngày nay? Để trả lời cho câu hỏi này, chúng tôi đã thực hiện một bài kiểm tra chi tiết trên tập dữ liệu 10 triệu dòng để so sánh trực diện hiệu năng của hai thư viện này.
Hiểu về công cụ: Pandas vs Polars
Pandas Pandas đã là tiêu chuẩn thực tế cho thao tác dữ liệu trong Python hơn một thập kỷ. Được xây dựng trên nền tảng NumPy, nó cung cấp API DataFrame linh hoạt và trực quan, hỗ trợ một phần lớn hệ sinh thái khoa học dữ liệu. Tuy nhiên, thiết kế của nó có một số hạn chế, đặc biệt là về việc thực thi đơn luồng (single-threaded) và hiệu suất bộ nhớ, những thứ có thể trở thành nút thắt lớn khi xử lý các tập dữ liệu quy mô lớn.
Polars Polars là thư viện DataFrame mới hơn, được thiết kế từ đầu nhằm tối ưu hóa hiệu suất. Viết bằng ngôn ngữ Rust, Polars tận dụng mô hình bộ nhớ dạng cột (columnar memory model), thực thi đa luồng và lazy evaluation để tối ưu hóa các quy trình làm việc dữ liệu phức tạp. Những lựa chọn kiến trúc này cho phép Polars vượt trội hơn các công cụ truyền thống trong nhiều kịch bản, đặc biệt khi xử lý dữ liệu lớn và các phép biến đổi chuỗi phức tạp.
Thiết lập thí nghiệm
Để đảm bảo sự so sánh công bằng và có thể tái tạo, tất cả các bài kiểm tra đều được thực hiện trong môi trường cục bộ được kiểm soát.
Môi trường:
- Vi xử lý: Intel® Core™ i5–1135G7 thế hệ 11 @ 2.40GHz
- RAM: 16 GB (3200 MT/s)
- Hệ điều hành: Windows 64-bit
Tập dữ liệu:
- Kích thước: 10.000.000 dòng (~600+ MB CSV)
- Cấu trúc: Tập dữ liệu tổng hợp mô phỏng nhật ký hệ thống thực tế, bao gồm các trường phân loại (office_location), chỉ số số học (latency_ms) và định danh duy nhất (user_id).
Thư viện:
- Pandas: Phiên bản 2.2.0 (sử dụng engine PyArrow)
- Polars: Phiên bản 1.1.0
Phương pháp kiểm tra
Quy trình đánh giá bao gồm các bước sau:
- Mỗi thao tác được thực hiện nhiều lần và thời gian thực thi trung bình được ghi lại.
- Một lần chạy khởi động (warm-up) được thực hiện trước khi đo lường để giảm thiểu độ lệch cold-start.
- Thời gian thực thi bao gồm cả bước tải dữ liệu và tổng hợp.
- Tất cả các thí nghiệm được tiến hành trong cùng một phiên runtime để đảm bảo tính nhất quán.
Kết quả và Quan sát
Kết quả benchmark làm nổi bật sự khác biệt về hiệu suất rõ rệt giữa Pandas và Polars khi xử lý tập dữ liệu 10 triệu dòng.
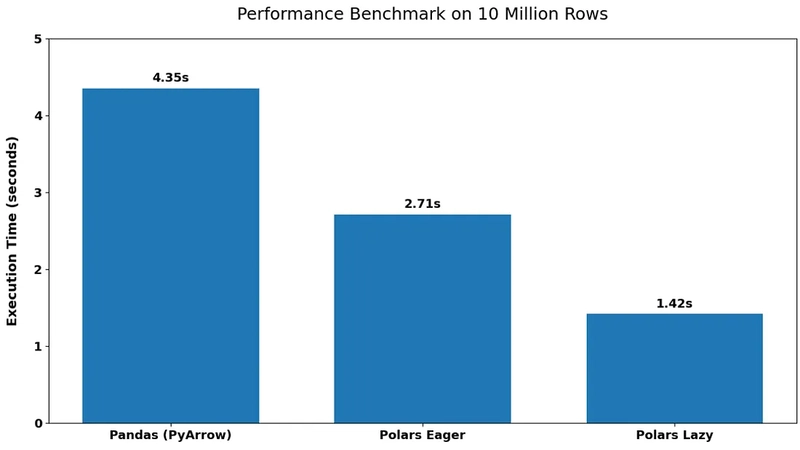 Biểu đồ so sánh hiệu năng giữa Pandas và Polars
Biểu đồ so sánh hiệu năng giữa Pandas và Polars
Dưới đây là các con số cụ thể:
- Pandas (PyArrow): 4.35 giây
- Polars Eager: 2.71 giây
- Polars Lazy: 1.42 giây
Khoảng cách về hiệu suất giữa hai thư viện là ngay lập tức. Polars vượt trội hơn Pandas ở cả hai chế độ thực thi, với mô hình thực thi lazy (lười) đạt được hiệu suất tốt nhất.
Cụ thể, Polars Eager nhanh hơn Pandas khoảng 1.6 lần, trong khi Polars Lazy đạt được cải thiện tốc độ gần 3 lần. Điều này cho thấy rằng ngay cả khi không tối ưu hóa, Polars vẫn mang lại lợi ích rõ rệt, và cơ chế lazy execution của nó còn nâng cao hiệu quả hơn nữa. Kết quả cũng cho thấy sự ổn định qua các lần chạy, khẳng định độ tin cậy của phương pháp đo lường.
Tại sao Polars nhanh hơn? Nhìn vào kiến trúc
Mặc dù kết quả benchmark cho thấy Polars vượt trội, nhưng sự khác biệt thực sự nằm ở cách các thư viện này được thiết kế bên dưới.
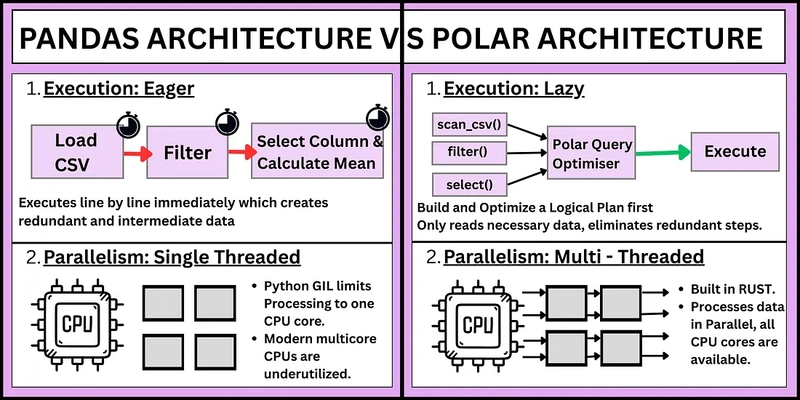 So sánh kiến trúc giữa Pandas và Polars
So sánh kiến trúc giữa Pandas và Polars
1. Mô hình thực thi: Eager vs Lazy
Pandas tuân theo mô hình thực thi eager (sẵn sàng), nghĩa là mỗi thao tác được thực thi ngay lập tức. Mặc dù điều này giúp dễ hiểu, nhưng nó có thể dẫn đến các tính toán trung gian không cần thiết.
Ngược lại, Polars hỗ trợ lazy evaluation (đánh giá lười), nơi các thao tác không được thực hiện ngay lập tức. Thay vào đó, chúng được tập hợp thành một kế hoạch truy vấn (query plan) và tối ưu hóa trước khi thực thi. Điều này cho phép Polars loại bỏ các bước thừa và thực hiện thao tác hiệu quả hơn.
2. Song song hóa và Đa luồng
Pandas phần lớn là đơn luồng do Global Interpreter Lock (GIL) của Python, điều này hạn chế khả năng tận dụng tối đa các bộ vi xử lý đa nhân hiện đại.
Polars, được viết bằng Rust, được thiết kế để tận dụng đa luồng theo mặc định. Điều này cho phép nó xử lý dữ liệu song song, giảm đáng kể thời gian thực thi cho các tập dữ liệu lớn.
3. Hiệu quả bộ nhớ và Xử lý dạng cột
Polars sử dụng định dạng bộ nhớ dạng cột, cho phép tận dụng bộ nhớ đệm (cache) tốt hơn và truy cập dữ liệu nhanh hơn, đặc biệt cho các khối lượng công việc phân tích.
Mặc dù Pandas cũng hoạt động trên cấu trúc dựa trên cột thông qua NumPy, nhưng nó không được tối ưu hóa nhiều cho quy mô lớn, dẫn đến chi phí bộ nhớ cao hơn và thực thi chậm hơn so với Polars.
4. Tối ưu hóa truy vấn
Một trong những lợi thế lớn nhất của Polars là khả năng tối ưu hóa truy vấn. Ở chế độ lazy, các thao tác như lọc, nhóm và tổng hợp được kết hợp và sắp xếp lại để giảm thiểu di chuyển dữ liệu và tính toán. Pandas không thực hiện các tối ưu hóa này tự động, nghĩa là mỗi bước được thực thi độc lập, thường dẫn đến công việc thừa thãi.
Kết luận
Nghiên cứu này làm nổi bật lợi thế hiệu suất rõ ràng của Polars so với Pandas khi làm việc với các tập dữ liệu quy mô lớn. Thông qua benchmark 10 triệu dòng dữ liệu, Polars — đặc biệt ở chế độ thực thi lazy — đã chứng minh khả năng xử lý nhanh hơn đáng kể, nhờ vào kiến trúc hiệu quả, thực thi song song và khả năng tối ưu hóa truy vấn.
Tuy nhiên, hiệu suất không phải là yếu tố duy nhất để ra quyết định. Pandas vẫn là lựa chọn mạnh mẽ cho các tập dữ liệu nhỏ, prototyping nhanh và các quy trình làm việc phụ thuộc vào hệ sinh thái phong phú của nó. Ngược lại, Polars ngày càng trở nên giá trị khi quy mô và độ phức tạp của dữ liệu tăng lên, khiến nó trở thành công cụ lý tưởng cho các nhiệm vụ kỹ thuật dữ liệu đòi hỏi hiệu suất cao.
Cuối cùng, lựa chọn giữa Pandas và Polars nên được hướng dẫn bởi quy mô dữ liệu, yêu cầu hiệu suất và nhu cầu cụ thể của quy trình làm việc.
Tài liệu tham khảo:
- Tài liệu chính thức Polars: https://pola.rs
- Tài liệu Pandas: https://pandas.pydata.org
- Tài liệu Apache Arrow: https://arrow.apache.org
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026