
Tầng Service (Service Layer): Kết nối các thành phần riêng lẻ thành một hệ thống hoàn chỉnh
Đây là phần 4 của loạt bài xây dựng API tìm kiếm ngữ nghĩa với Java và Spring Boot. Bài viết tập trung vào tầng Service, nơi quản lý luồng dữ liệu, xử lý lỗi nhúng (embedding) và xây dựng truy vấn tìm kiếm an toàn để biến các thành phần rời rạc thành một hệ thống thống nhất.
Đây là phần 4 trong chuỗi bài viết hướng dẫn xây dựng một API tìm kiếm ngữ nghĩa (semantic search API) chuẩn sản xuất với Java, Spring Boot và pgvector.
Phần 1 đã đề cập đến kiến trúc tổng thể. Phần 2 đã định nghĩa schema cơ sở dữ liệu. Phần 3 đã xử lý việc nhúng dữ liệu — cách chuyển đổi văn bản thành các vector.
Từng thành phần hoạt động tốt riêng lẻ. Tuy nhiên, các hệ thống thường không thất bại khi ở trạng thái cô lập — chúng gặp sự cố tại các ranh giới kết nối.
Nếu bạn từng xây dựng một tính năng hoạt động hoàn hảo độc lập nhưng lại "gãy" ngay khi kết nối nó với phần còn lại của ứng dụng, thì bài viết này chính là để ngăn chặn điều đó xảy ra.
Tại thời điểm này, chúng ta đã có một schema có thể lưu trữ tài liệu và một lớp nhúng (embedding layer) có thể tạo ra vector. Nhưng chưa có gì kết nối chúng cả. Tài liệu không biết đi đâu, và một truy vấn không có quy trình xử lý (pipeline) để chạy.
Đây chính là lúc Tầng Service (Service Layer) xuất hiện.
Đây là một triển khai theo phong cách sản xuất thực tế — không phải là bản demo. Cấu trúc dự án đầy đủ, các bài kiểm tra (tests) và cấu hình đều có sẵn trên GitHub.
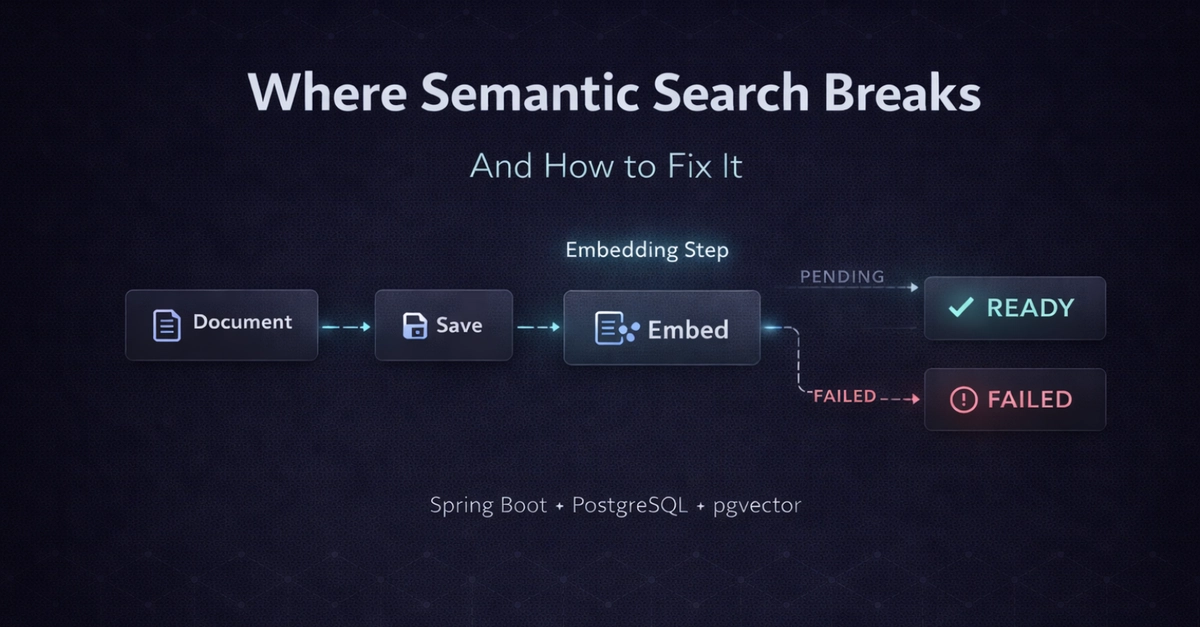
Tầng Service thực sự làm gì?
Database lưu trữ trạng thái, nhưng nó không hiểu trạng thái đó.
PENDING (Chờ xử lý), READY (Sẵn sàng) và FAILED (Thất bại) chỉ thực sự có ý nghĩa khi tầng Service định nghĩa khi nào các sự chuyển đổi này xảy ra và điều gì kích hoạt chúng.
Khi một tài liệu đến, Service sẽ quyết định thứ tự các thao tác — lưu trước, nhúng sau, cập nhật khi thành công, và ghi nhận lỗi một cách rõ ràng nếu có sự cố.
Tìm kiếm cũng tuân theo quy mô tương tự. Một truy vấn không đi thẳng vào database. Nó đầu tiên được chuyển đổi thành một embedding, sau đó được đưa qua một truy vấn áp dụng các ràng buộc vòng đời, bộ lọc metadata và ngưỡng điểm số (scoring thresholds).
Tầng Service kiểm soát toàn bộ pipeline đó.
Tầng Service nắm giữ một thứ duy nhất: các quy tắc khiến hệ thống trở nên dễ đoán định.
Không có nó, hệ thống chỉ là một tập hợp các thành phần đúng logic nhưng bị ngắt kết nối.
HTTP Request
│
▼
Controller Layer ← xác thực đầu vào, ủy quyền cho service
│
▼
Service Layer ← tất cả quyết định diễn ra ở đây
│ │
▼ ▼
Repository Layer Embedding Layer
(JPA + JdbcTemplate) (EmbeddingClient interface)
│ │
▼ ▼
PostgreSQL + pgvector OpenAI API
Interface giúp mọi thứ gọn gàng
Tầng Service expose một interface duy nhất cho phần còn lại của ứng dụng:
public interface DocumentService {
CreateDocumentResponse create(CreateDocumentRequest request);
DocumentResponse getById(Long id);
SearchResponse search(SearchRequest request);
}
Các Controller phụ thuộc vào interface, không phải vào implementation (lớp triển khai cụ thể).
Việc định nghĩa hợp đồng dưới dạng interface và ẩn implementation phía sau nó là điều khiến hệ thống có thể kiểm thử và thay đổi mà không gây ra các cập nhật lan truyền (cascading updates) trên toàn bộ codebase.
Chi tiết quan trọng hơn là những gì không được phép vượt qua ranh giới này.
Entity Document không bao giờ vượt qua ranh giới này — theo thiết kế. Các Controller nhận DTOs, không phải các đối tượng lưu trữ (persistence objects).
Sự tách biệt này có nghĩa là database schema và hợp đồng API có thể phát triển độc lập. Schema có thể thay đổi mà không làm vỡ client. API có thể thay đổi mà không cần viết lại logic lưu trữ.
Tại sao điều này quan trọng với bạn: Nếu bạn từng gặp phải việc thay đổi database làm vỡ API — hoặc thay đổi API buộc phải viết lại database — thì ranh giới này chính là thứ ngăn chặn điều đó. Hãy định nghĩa nó sớm và giữ vững nó.
Xảy ra gì khi quá trình nhúng (Embedding) thất bại?
Từ bên ngoài, việc tạo một tài liệu trông có vẻ đơn giản. Gửi tài liệu, nhận lại ID.
Bên trong Service, mọi thứ được xây dựng xung quanh một giả định: bước thứ hai có thể thất bại.
@Override
@Transactional
public CreateDocumentResponse create(CreateDocumentRequest request) {
Document saved = saveAsPending(request);
embedAndPersist(
saved.getId(),
saved.getTitle(),
saved.getContent()
);
return new CreateDocumentResponse(
saved.getId(),
DocumentStatus.READY
);
}
Hai dòng, hai thao tác riêng biệt.
Dòng đầu tiên lưu tài liệu ngay lập tức với trạng thái PENDING.
Tài liệu đã tồn tại trong database trước khi bất kỳ cuộc gọi nhúng nào được thực hiện. Nếu ứng dụng sập tại thời điểm này, tài liệu đã ở đó với một trạng thái có thể khôi phục.
Dòng thứ hai gọi OpenAI API, tạo embedding, và cập nhật tài liệu sang trạng thái READY.
Nếu bước này thất bại, tài liệu sẽ chuyển sang FAILED thay thế, và lỗi được lưu trực tiếp vào database.
POST /documents
│
▼
saveAsPending()
status = PENDING ← tài liệu an toàn trong database
│
▼
embedAndPersist()
│
┌──┴──────────────┐
│ │
▼ ▼
status = READY status = FAILED
có thể tìm kiếm lỗi được lưu trong DB
loại khỏi tìm kiếm
Có một giải pháp thay thế trông có vẻ đơn giản hơn — nhúng trước, lưu sau.
Nó loại bỏ một bước nhưng cũng loại bỏ khả năng quan sát. Nếu nhúng thất bại trong mô hình đó, tài liệu chưa bao giờ tồn tại. Không có bản ghi, không có trạng thái, không có gì để debug.
Bằng cách lưu trước, mọi nỗ lực đều để lại dấu vết.
Thất bại không biến mất.
Chúng trở thành dữ liệu.
Mẫu này — lưu trước, nhúng sau — là sự khác biệt giữa một lỗi bạn có thể debug và một lỗi biến mất vào hư không.
Dưới đây là cách xử lý lỗi thực sự hoạt động:
private void embedAndPersist(Long documentId, String title, String content) {
try {
float[] embedding = embeddingClient.embed(title + "\n\n" + content);
int updated = jdbcTemplate.update(SQL_UPDATE_EMBEDDING,
toPgVectorLiteral(embedding), documentId);
if (updated != 1) {
throw new IllegalStateException(
"Unexpected row count updating embedding for document id=" + documentId);
}
} catch (IllegalStateException e) {
throw e;
} catch (Exception e) {
markFailed(documentId, e.getMessage());
throw new RuntimeException("Embedding failed for document id=" + documentId, e);
}
}
Có ba quyết định đáng hiểu ở đây:
- Tiêu đề và nội dung được nối lại để nhúng.
title + "\n\n" + contentcung cấp ngữ cảnh đầy đủ cho mô hình. IllegalStateExceptionđược ném lại nguyên vẹn. Nếu việc cập nhật ảnh hưởng đến 0 hoặc nhiều hơn 1 hàng, có gì đó sai với trạng thái database — không phải cuộc gọi nhúng.- Mọi thứ khác kích hoạt
markFailed. Quá hạn mạng (timeouts), giới hạn tốc độ (rate limits), phản hồi sai định dạng — bất kỳ ngoại lệ nào không phảiIllegalStateExceptionđều sẽ ghi nhận thất bại và ném lại.
Hầu hết các lỗi tích hợp API đều âm thầm. Cách tiếp cận này làm cho chúng trở nên "ồn ào".
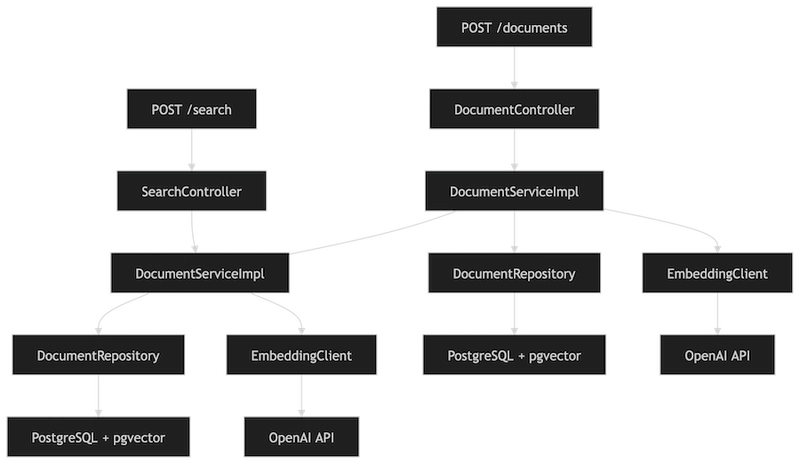
Tìm kiếm — Pipeline kết nối mọi thứ
Tìm kiếm là thao tác phức tạp nhất trong Service. Nó chạm tới lớp nhúng, repository và database — và nó phải phối hợp cả ba chính xác.
Điều làm cho nó có thể quản lý được không phải là giảm bớt sự phức tạp đó, mà là bao chứa nó một cách có chủ đích.
Phương pháp điều phối được giữ nhỏ gọn một cách có chủ đích:
@Override
public SearchResponse search(SearchRequest request) {
String qVector = embedQuery(request.getQuery());
List<SearchResultItem> items = fetchResults(
request,
qVector
);
int total = countResults(
qVector,
request.getFilters(),
request.getMinScore()
);
return new SearchResponse(
request.getPage(),
request.getSize(),
total,
items
);
}
Bốn dòng. Mỗi dòng ủy quyền cho một private method với tên rõ ràng. Phương thức đọc như một mô tả của quá trình tìm kiếm — nhúng truy vấn, lấy kết quả, đếm tổng số, trả về phản hồi.
 Semantic Search Architecture
Semantic Search Architecture
Truy vấn đi qua cùng một client nhúng được sử dụng cho tài liệu. Sự đối xứng này rất quan trọng — truy vấn và các tài liệu được lưu trữ tồn tại trong cùng một không gian vector.
SQL được xây dựng trong hai lớp: truy vấn nội bộ chọn các ứng cử viên và tính toán sự tương đồng, trong khi truy vấn bên ngoài áp dụng các ngưỡng điểm số và phân trang.
Tại sao JPA không đủ cho Tìm kiếm Vector
Truy vấn tìm kiếm không tĩnh. Các bộ lọc metadata, ngưỡng điểm số và phân trang đều thay đổi SQL tại thời điểm chạy (runtime).
Tại thời điểm đó, sự trừu tượng mà JPA cung cấp bắt đầu bị phá vỡ — bạn không còn ánh xạ đối tượng, bạn đang xây dựng một truy vấn.
Đó là lúc QueryBuilder xuất hiện:
private static class QueryBuilder {
private final StringBuilder sql;
private final List<Object> params = new ArrayList<>();
// Constructor...
}
Hai constructor phản chiếu cấu trúc của truy vấn – nội bộ và bên ngoài. Rủi ro tiêm (injection) thực sự nằm ở việc áp dụng bộ lọc:
void applyFilters(Map<String, String> filters) {
// ...
for (Map.Entry<String, String> entry : filters.entrySet()) {
String key = entry.getKey();
if (key == null || !key.matches("^[a-zA-Z0-9_-]{1,64}$")) {
throw new IllegalArgumentException("Invalid metadata filter key: " + key);
}
sql.append(" AND (metadata->>'").append(key).append("') = ?\n");
params.add(entry.getValue());
}
}
Khóa bộ lọc được nối trực tiếp vào chuỗi SQL. Regex ^[a-zA-Z0-9_-]{1,64}$ không phải để tiện lợi; đó là điểm kiểm soát duy nhất giữa đầu vào người dùng và database.
Đây là một trong những trường hợp mà regex "nhàm chán" đang thực hiện công việc bảo mật nghiêm trọng. Đừng bỏ qua nó.
Cập nhật tài liệu đồng nghĩa với cập nhật Embedding
Cập nhật một tài liệu không giống như cập nhật một hàng trong database.
Khi nội dung thay đổi, vector nhúng lưu trữ sẽ trở nên cũ kỹ (stale). Một tài liệu về "logic thử lại thanh toán" được cập nhật thành "xử lý hoàn tiền". Nhưng vector nhúng vẫn chỉ về phía các thử lại thanh toán.
Hoạt động cập nhật xử lý việc này một cách rõ ràng bằng cách reset tài liệu về PENDING, loại bỏ nó khỏi tìm kiếm cho đến khi một vector nhúng mới được tạo ra. Đây là sự đánh đổi tính sẵn có để lấy tính chính xác.
Một nơi cho mọi lỗi của bạn
Lỗi trong hệ thống này rơi vào hai danh mục — lỗi do người gọi gây ra và lỗi hệ thống gặp phải. Hai trường hợp này không nên trông giống nhau.
Sự nhất quán được thực thi trong một nơi — GlobalExceptionHandler.
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(ResourceNotFoundException.class)
public ResponseEntity<ErrorResponse> handleNotFound(ResourceNotFoundException ex) {
return ResponseEntity.status(404)
.body(new ErrorResponse("NOT_FOUND", ex.getMessage()));
}
// ... các handler khác
}
Service ném exceptions. Handler dịch chúng. Các Controller không bao giờ thấy code xử lý lỗi. Một client luôn nhận được code và message có thể xử lý tất cả các lỗi bằng một logic duy nhất.
Một handler, phản hồi nhất quán ở khắp mọi nơi — đội frontend của bạn sẽ cảm ơn bạn.
Hệ thống giờ đã hoạt động
Với tầng Service tại chỗ, hệ thống cuối cùng cũng hoạt động như một hệ thống thực thụ.
Một tài liệu đến tại POST /documents. Controller xác thực yêu cầu và ủy quyền cho Service. Service lưu tài liệu dưới dạng PENDING, gọi embedding client và cập nhật trạng thái thành READY. Tài liệu hiện đã được lưu với một vector hợp lệ và hiển thị để tìm kiếm.
Một truy vấn tìm kiếm đến tại POST /search. Service nhúng truy vấn, xây dựng SQL động, áp dụng bộ lọc và trả về kết quả được xếp hạng.
Mọi tầng có đúng một công việc. Mọi thất bại đều hiển thị. Mọi phản hồi đều có hình dạng nhất quán.
Trong bài viết tiếp theo, tôi sẽ bước lại khỏi việc triển khai và phân tích những gì hệ thống này làm đúng, sai, và những gì tôi sẽ thay đổi nếu xây dựng lại từ đầu.


