
Thử thách hàng ngày cho lập trình viên: Vượt qua các bài toán mẫu để thực sự "ship" code
Hầu hết các ứng dụng rèn luyện code hiện nay chỉ tập trung vào việc vượt qua các bài kiểm tra thuật toán, điều này tốt cho phỏng vấn nhưng thiếu hụt kỹ năng kỹ sư thực tế. Codeground ra mắt thử thách hàng ngày với môi trường đa ngôn ngữ, chạy trên Docker và hệ thống chấm điểm toàn diện về độ chính xác, tốc độ và chất lượng mã nguồn.

Hầu hết các ứng dụng hình thành thói quen lập trình hiện nay đều tối ưu hóa cho một tín hiệu duy nhất: trình chấm tự động có chấp nhận câu trả lời của bạn không? Điều này hữu ích khi mục tiêu ngắn hạn của bạn là sống sót qua các buổi phỏng vấn thuật toán nặng về mẹo. Tuy nhiên, nó lại kém phù hợp trong 11 tháng còn lại của năm—khi mà "kỹ thuật phần mềm" thực sự là đọc code lạ, tìm ra lỗi sai, đảm bảo đầu ra khớp với đặc tả, và triển khai một thay đổi mà bạn có thể bảo vệ trong buổi review.
Đây chính là khoảng trống mà thử thách hàng ngày của Codeground lấp đầy: một nhiệm vụ mỗi ngày theo giờ UTC, hỗ trợ đa ngôn ngữ, thực thi trên nền tảng Docker, và hệ thống chấm điểm kết hợp giữa độ chính xác, tốc độ và chất lượng code—chứ không chỉ là một giá trị boolean "đã qua tất cả các bài kiểm tra".
Nếu bạn muốn xây dựng một thói quen dài hạn vẫn giữ được tính trung thực trong kỷ nguyên AI, hãy cùng tìm hiểu dưới đây.
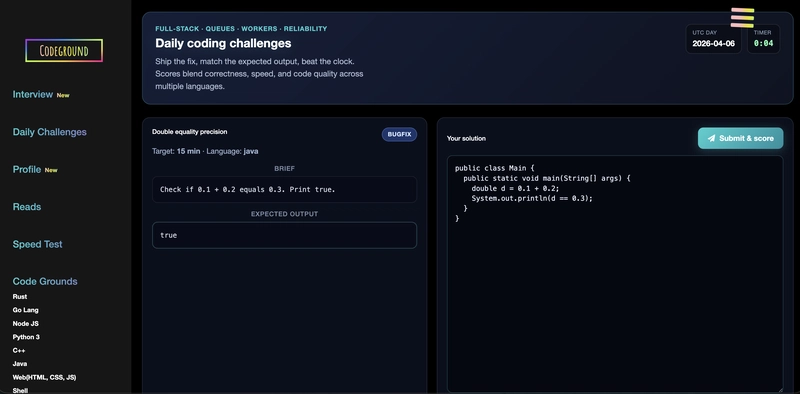 Thử thách lập trình hàng ngày
Thử thách lập trình hàng ngày
Tại sao "luyện tập hàng ngày" cần một cơ chế thưởng tốt hơn
Luyện tập sẽ tạo ra hiệu ứng cộng khi vòng lặp phản hồi khớp với công việc thực tế.
Những gì các bài toán kinh điển dạy tốt
- Nhận diện nhanh các khuôn mẫu thuật toán.
- Săn lùng các điều kiện biên trong các thế giới gọn gàng, khép kín.
- Biến trực giác về độ phức tạp thành các giải pháp được chấp nhận.
Những gì các đội ngũ kỹ thuật thực sự trả tiền để có
- Định vị hóa (Localization): Vị trí của lỗi trong code thực tế.
- Kỷ luật đặc tả (Specification discipline): "Hoàn thành" nghĩa là gì khi yêu cầu lộn xộn.
- Kỷ luật thực thi (Execution discipline): Những gì runtime nói, chứ không phải những gì bạn mong muốn nó nói.
- Khả năng bảo trì (Maintainability): Đoạn thay đổi (diff) mà "bạn của ngày mai" sẽ không ghét.
Những kỹ năng thứ hai chính là những kỹ năng vẫn mang trọng số con người trong kỷ nguyên của tính năng tự động hoàn thành (autocompletion) chất lượng cao. Các mô hình AI rất giỏi tạo ra các bản nháp hợp lý, nhưng chúng không loại bỏ được quyền sở hữu, xác minh hay rủi ro tích hợp.
Vì vậy, câu hỏi thiết kế trở nên thẳng thắn:
Nếu một kỹ sư đang làm việc có một khối thời gian tập trung hôm nay, nhiệm vụ nào sẽ vẫn cảm thấy trung thực với công việc của họ?
Đối với chúng tôi, câu trả lời đã chuyển hướng từ "một bài toán thông minh khác" sang code khởi động bạn có thể chạy, đầu ra mong đợi bạn có thể so sánh, và một bảng xếp hạng không giả vờ rằng tính dễ đọc là không quan trọng.
Đó chính là hình thức trải nghiệm đằng sau trang thử thách của ngày hôm nay.
Những gì bạn nhận được: Vòng lặp sản phẩm dưới dạng ngôn ngữ đơn giản
1) Nhiệm vụ dạng kho lưu trữ (Repo-shaped tasks)
Bạn tương tác với code khởi động cụ thể—gần giống với một vé (ticket) công việc hơn là một bài toán văn bản năm đoạn mà độ khó thực sự của nó là "đoán ra mẹo". Mục đích là để luyện tập phản xạ kỹ thuật: đọc, đưa ra giả thuyết, chỉnh sửa, chạy, so sánh.
2) Độ chính xác có thể quan sát được
"Chính xác" được neo vào kết quả thực thi mà bạn có thể lý luận—cái gì được in ra, cái gì khớp, cái gì thất bại. Điều này phản chiếu cách các sự cố được gỡ lỗi và cách CI bắt các lỗi thoái lùi (regression).
3) Đa ngôn ngữ trong một thói quen
Các đội ngũ thực tế là đa ngôn ngữ (polyglot): dịch vụ bằng Node, script bằng Python, mã JVM bằng Java, các phần nhạy cảm về hiệu suất bằng C++. Làn đường hàng ngày hỗ trợ Node.js, Python, Java và C++ để "thói quen hàng ngày" của bạn không âm thầm quá khớp với cơ bắp của một ngôn ngữ duy nhất.
Nếu tuần của bạn thường xuyên xuyên qua các runtime khác nhau, trung tâm thử thách hàng ngày được thiết kế để tôn trọng điều đó thay vì giam bạn trong một stack duy nhất mãi mãi.
4) Chạy trên nền tảng Docker
Thực thi trong container không phải là phép thuật; đó là giảm thiểu phương sai (variance reduction). Ít bí ẩn "chạy được trên máy của tôi, nhưng lỗi trên nền tảng" hơn, nhiều tự tin hơn rằng lượt chạy đã đo của bạn có thể so sánh được với lượt chạy đã đo của người khác—đặc biệt khi thời gian và thứ hạng quan trọng.
5) Chấm điểm: Độ chính xác + Tốc độ + Chất lượng
Mô hình điểm chỉ có tốc độ sẽ trở thành một cuộc thi hackathon. Mô hình điểm chỉ có độ chính xác giả vờ rằng thời hạn không tồn tại. Mô hình điểm không có tín hiệu chất lượng dạy những thói quen không sống sót qua buổi review code.
Sự kết hợp có chủ đích là:
| Trụ cột | Những gì nó xấp xỉ trong công việc thực |
|---|---|
| Độ chính xác / Đầu ra | Bạn có thực sự giải quyết những gì được yêu cầu không? |
| Tốc độ | Bạn có thể triển khai dưới áp lực đồng hồ thực không? |
| Chất lượng | Đồng nghiệp có cảm ơn bạn vì đoạn diff này không? |
Các con số chính xác có thể thay đổi; nhưng nguyên tắc thì không: triển khai (shipping) là một gói kết hợp.
6) Bảng xếp hạng công khai, bài toán trực tiếp được bảo vệ
Động lực và cộng đồng được hưởng lợi từ thứ hạng hiển thị. Sự cạnh tranh công bằng sẽ bị ảnh hưởng nếu đề bài dễ dàng bị thu thập dữ liệu.
Trên thử thách hàng ngày của Codeground, bạn có thể xem bảng xếp hạng ngày UTC công khai mà không cần đăng nhập. Bài toán trực tiếp vẫn nằm sau xác thực để ngày hôm nay vẫn có ý nghĩa và nhiệm vụ không bị các bot quét sạch một cách dễ dàng.
Một sự so sánh công bằng: Mài giũa phỏng vấn vs. Luyện tập thực thi hàng ngày
Đây không phải là "thay thế LeetCode". Các công cụ khác nhau tối ưu hóa các kỹ năng khác nhau.
Các thư viện tập trung vào phỏng vấn thường thắng về khối lượng (volume) thuần túy, phân loại học (taxonomy), và một văn hóa được điều chỉnh cho mùa tuyển dụng.
Luyện tập thực thi hàng ngày thiên về:
- Nhiệm vụ gỡ lỗi và căn chỉnh.
- Sự trôi chảy đa ngôn ngữ.
- Các lượt chạy bạn có thể tin tưởng.
- Các động lực không bỏ qua khả năng bảo trì.
Hãy sử dụng cả hai nếu bạn muốn: khối lượng kinh điển khi các buổi phỏng vấn đang đến gần, vòng lặp hàng ngày của Codeground khi bạn muốn thói quen theo dõi kỹ thuật dạng "công việc".
Trường hợp kỷ nguyên AI, không cần bài diễn thuyết sáo rỗng
Các công cụ Copilot đã giảm chi phí cho bản nháp đầu tiên. Chúng không xóa bỏ:
- Xác minh (Verification) (tái hiện lỗi, nhật ký, diff).
- Ràng buộc (Constraints) (tương thích, bảo mật, độ trễ).
- Gu thẩm mỹ (Taste) (cái gì là "đủ tốt để mở rộng" ở đây).
- Trách nhiệm giải trình (Accountability) (vẫn có người thực hiện việc merge).
Kỹ năng tạo ra hiệu ứng cộng là xác minh nhanh và trung thực: biến "nghe có vẻ đúng" thành có thể quan sát thấy là đúng. Một bài tập hàng ngày buộc phải chạy → so sánh → sửa sẽ rèn luyện cùng một vòng lặp mà bạn sử dụng khi một mô hình AI đưa cho bạn một đoạn code gần như hoạt động.
Nếu bạn muốn luyện tập phù hợp với điều đó, hãy bắt đầu tại trang thử thách hàng ngày.
Cách sử dụng mà không bị kiệt sức
Tuần 1: Coi nó như việc đo lường (instrumentation)
Hãy tìm hiểu trình chạy (runner), cảm nhận về bộ hẹn giờ và cách chấm điểm thúc đẩy bạn. Đừng coi điểm số sớm là bản sắc của bạn.
Xây dựng một nghi thức nhỏ
Cùng một ly cà phê, cùng một quy tắc: mở thử thách trước khi thông báo chiếm lĩnh buổi sáng của bạn. Một cửa sổ UTC mới cùng với bảng xếp hạng hiển thị tạo ra sự trách nhiệm giải trình nhẹ nhàng.
Luân phiên ngôn ngữ có chủ đích
Ngay cả khi công việc của bạn là "chủ yếu là Java", các lượt lặp lại Python hoặc Node đôi khi sẽ ngăn bạn nhầm lẫn sự quen thuộc với stack với chiều sâu kỹ thuật.
Sau khi bỏ lỡ, hãy thẩm vấn quy trình
Hãy tự hỏi: tôi đã giả định điều gì mà thực thi đã không đồng ý? Câu hỏi đó có thể mang đi—đến CI, trực ca (on-call), và review PR.
Dành cho ai
Phù hợp mạnh mẽ
- Các kỹ sư muốn khả năng đo lường hàng ngày mà không sống hoàn toàn bên trong các bài toán trừu tượng.
- Các nhà phát triển đa ngôn ngữ muốn một thói quen duy nhất trên Node / Python / Java / C++.
- Những người muốn thứ hạng minh bạch mà không đổ toàn bộ đề bài ra web công khai.
Phù hợp kém hơn
- Nếu mục tiêu duy nhất của bạn là tối đa hóa DSA kinh điển trong thời gian ngắn nhất.
- Nếu bạn không thích luyện tập có giới hạn thời gian.
Kêu gọi hành động
- Mở https://www.codeground.ai/daily-challenges.
- Đọc bảng xếp hạng ngày UTC công khai hôm nay.
- Đăng nhập khi bạn muốn thử thách trực tiếp, trình soạn thảo, chạy lượt, và nộp bài được chấm điểm.
- Đọc phần phân tích—độ chính xác, tốc độ, chất lượng—và chọn một điều để cải thiện vào lần tới.
Kết luận
Thói quen kỹ thuật bền vững nhất vẫn không hào nhoáng: hiện diện, thực thi, so sánh với thực tế, điều chỉnh.
Nếu bạn muốn điều đó được đóng gói như một thử thách hàng ngày với runtime thực, hỗ trợ đa ngôn ngữ, và xếp hạng công khai—trong khi vẫn giữ bài toán trực tiếp công bằng—hãy sử dụng Codeground — daily challenges làm điểm khởi đầu của bạn.
Nếu bạn không đồng ý với một nhiệm vụ, một điểm số, hoặc lựa chọn về công thái ngôn ngữ, phản hồi đó cũng là một phần của nghề thủ công, hãy để lại trong phần bình luận sau khi bạn đã chạy code ít nhất một lần.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026