
Tối ưu hóa Pipeline RAG: Tại sao bạn cần Cross-Encoders và Reranking?
Tìm kiếm ngữ nghĩa (semantic search) là nền tảng của nhiều ứng dụng AI, nhưng chỉ sử dụng bi-encoder thường chưa đủ. Bài viết này đi sâu vào cách sử dụng cross-encoders và kỹ thuật reranking để nâng cao độ chính xác của hệ thống RAG mà không ảnh hưởng quá nhiều đến hiệu suất.
Tìm kiếm ngữ nghĩa (semantic search), hay truy xuất dựa trên embedding, đã trở thành một thành phần cốt lõi trong nhiều ứng dụng AI hiện nay. Tuy nhiên, khá ngạc nhiên khi vẫn có nhiều ứng dụng bỏ qua bước reranking (xếp hạng lại), mặc dù việc triển khai nó không quá phức tạp.
Nếu bạn từng xây dựng một pipeline RAG (Retrieval-Augmented Generation) và cảm thấy kết quả "chấp nhận được nhưng chưa thực sự xuất sắc", giải pháp không phải lúc nào cũng là chọn một mô hình embedding tốt hơn. Thay vào đó, bạn nên cân nhắc thêm bước reranking, và cross-encoders chính là ứng cử viên sáng giá nhất cho việc này.
Bài viết này sẽ giải thích cross-encoders là gì, tại sao chúng lại hiệu quả trong việc reranking, cách fine-tune chúng trên dữ liệu của riêng bạn, cùng một số kỹ thuật nâng cao để tối ưu hóa hệ thống.
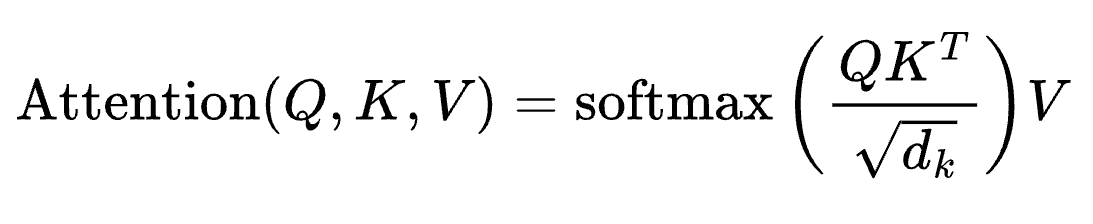 Kiến trúc so sánh
Kiến trúc so sánh
Vấn đề của việc truy xuất truyền thống
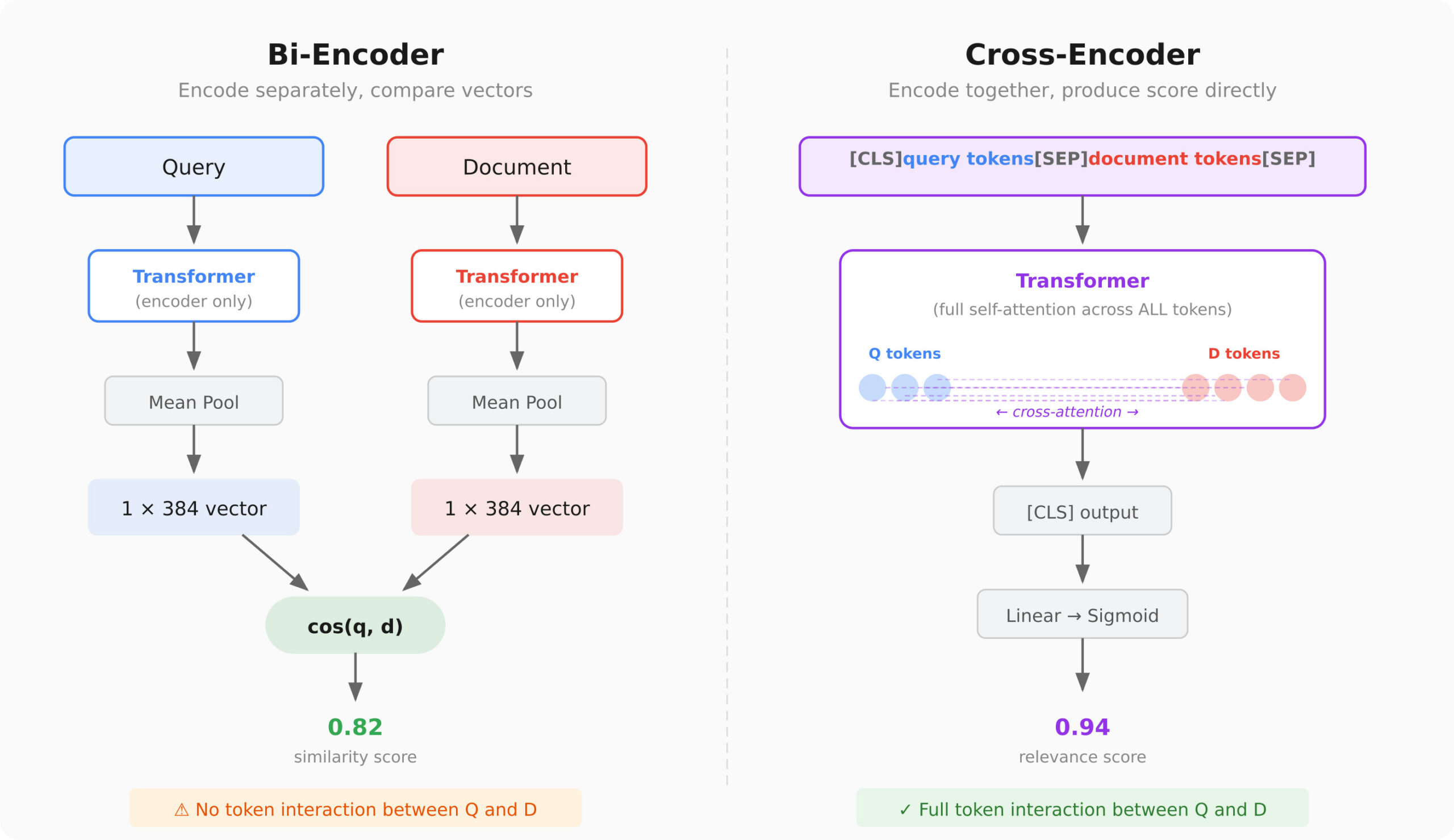
Hầu hết các hệ thống tìm kiếm ngữ nghĩa hiện nay sử dụng bi-encoders. Chúng mã hóa câu truy vấn (query) thành một vector, mã hóa tài liệu (documents) thành các vector, sau đó tìm các kết quả khớp nhất. Đây là một thao tác nhanh, dễ mở rộng quy mô và thường cho kết quả khá tốt.
Tuy nhiên, việc mã hóa độc lập query và document làm mất đi khả năng tương tác giữa các tín hiệu. Mô hình embedding phải nén tất cả ngữ nghĩa vào một vector duy nhất trước khi bất kỳ sự so sánh nào diễn ra.
Hãy xem một ví dụ cụ thể. Bạn tìm kiếm "khách sạn giá rẻ ở Tokyo" và nhận lại:
- "Khách sạn sang trọng ở Tokyo giá khởi điểm $500/đêm"
- "Nhà nghỉ bình dân ở Tokyo giá $30/đêm"
- "Chuyến bay giá rẻ đến Tokyo"
Kết quả #1 điểm cao vì khớp từ "khách sạn" và "Tokyo". Kết quả #3 khớp "giá rẻ" và "Tokyo". Nhưng kết quả #2 — cái bạn thực sự cần — có thể xếp dưới cả hai vì "giá rẻ" và "bình dân" không gần nhau trong không gian embedding.
Một bi-encoder không thể lý giải mối quan hệ giữa "giá rẻ" trong query và "$500/đêm" trong document. Nó chỉ thấy sự trùng lặp token ở các vector nén. Ngược lại, một cross-encoder sẽ "đọc" query và document cùng lúc, nhận ra sự mâu thuẫn và xếp hạng nó thấp hơn.
Mô hình hai giai đoạn (Two-Stage Pattern)
Trong thực tế, chúng ta có thể kết hợp bi-encoders và cross-encoders để đạt hiệu suất tối ưu:
- Giai đoạn 1: Truy xuất nhanh. Sử dụng bi-encoder hoặc BM25 để "vây bắt" rộng, thu về top k ứng viên hàng đầu (cao recall).
- Giai đoạn 2: Reranking chính xác. Chạy cross-encoder trên các ứng viên đó theo từng cặp (query, document) để có thứ hạng tốt hơn (cao precision).
Đây thực chất là một mô hình chuẩn trong sản xuất hiện nay. Các nền tảng như Cohere cung cấp API Rerank riêng biệt, Pinecone tích hợp sẵn reranking, và Google đã sử dụng BERT để xếp hạng lại kết quả tìm kiếm từ năm 2019. Các thư viện như LangChain và LlamaIndex cũng đều hỗ trợ bước này.
Tại sao không chỉ dùng Cross-Encoder cho mọi thứ?
Vấn đề nằm ở chi phí tính toán (compute).
- Bi-encoder: Mã hóa tất cả tài liệu một lần lúc lập chỉ mục (O(n)). Lúc query, chỉ mã hóa query và tìm kiếm láng giềng gần nhất (O(1) với ANN index).
- Cross-encoder: Không thể tính toán trước. Nó cần xem query và document cùng lúc. Ở thời điểm query, nó phải chạy một forward pass đầy đủ của transformer cho từng cặp (query, document).
Với kho dữ liệu 1 triệu tài liệu, đó là 1 triệu forward pass cho mỗi query. Rõ ràng điều này là không khả thi về mặt chi phí GPU. Nhưng nếu chúng ta thu hẹp xuống khoảng 100+ ứng viên từ giai đoạn 1, việc này chỉ mất vài trăm mili-giây.
Đó là lý do truy xuất hai giai đoạn hiệu quả: tìm kiếm rẻ rồi xếp hạng chính xác.
Cách hoạt động của Bi-Encoder và Cross-Encoder
Kiến trúc Bi-Encoder
Bi-encoder sử dụng hai transformer encoder riêng biệt, tạo ra các embedding có kích thước cố định cho query và document. Điểm tương đồng chỉ đơn giản là độ tương đồng cosine giữa hai vector. Hạn chế lớn là mô hình nén mọi ý nghĩa vào một vector trước khi so sánh, làm mất nhiều sắc thái ngữ nghĩa.
Kiến trúc Cross-Encoder
Cross-encoder nối query và document thành một chuỗi đầu vào duy nhất trước khi đưa qua một transformer. Mọi token trong query có thể "chú ý" (attend) đến mọi token trong document. Đầu ra không phải là embedding mà là điểm số liên quan trực tiếp giữa query và document.
Tối ưu hóa với Fine-tuning và Distillation
Nhiều cross-encoder được huấn luyện sẵn vẫn mang tính chung chung. Nếu lĩnh vực của bạn là hợp đồng pháp lý, hồ sơ y tế hay báo cáo an ninh mạng, việc fine-tune (huấn luyện lại) là cần thiết để mô hình hiểu đúng thuật ngữ chuyên ngành.
Quá trình này thường sử dụng kỹ thuật transfer learning từ các mô hình như BERT hoặc MiniLM, huấn luyện trên các cặp (query, document, nhãn liên quan).
Một kỹ thuật mạnh mẽ khác là Knowledge Distillation (Chưng cất kiến thức). Bạn có thể dạy cho một bi-encoder nhanh (student) bắt chước cách xếp hạng của một cross-encoder chậm nhưng chính xác (teacher). Kết quả là bạn có chất lượng gần giống cross-encoder nhưng với tốc độ của bi-encoder.
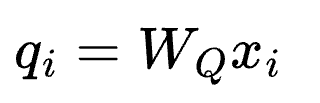 Kết quả benchmark
Kết quả benchmark
Các kỹ thuật nâng cao khác
Semantic Caching
Để tiết kiệm tài nguyên, bạn có thể sử dụng cross-encoder để phát hiện các query giống nhau (paraphrase). Nếu một query mới đủ tương đồng với query đã có trong cache, hệ thống sẽ trả về kết quả đã xếp hạng sẵn mà không cần tính toán lại. Trong thử nghiệm, kỹ thuật này giúp giảm 76% số thao tác xếp hạng.
Multi-stage Funnel
Bạn có thể xây dựng một phễu nhiều giai đoạn:
- Bi-encoder: Lọc từ 50 tài liệu -> 20 tài liệu.
- Cross-encoder: Xếp hạng lại 20 tài liệu -> 10 tài liệu.
- LLM: Sử dụng Mô hình ngôn ngữ lớn để xếp hạng danh sách (list-wise reranking) 10 tài liệu -> 5 tài liệu cuối cùng. LLM có thể lý giải về tính liên quan tương đối ("Tài liệu A tốt hơn B vì...").
ColBERT và Late Interaction
ColBERT (COntextualized Late interaction over BERT) là một giải pháp trung gian. Nó giữ lại tất cả các embedding token-level thay vì gộp chúng thành một vector như bi-encoder. Khi so sánh, nó sử dụng hàm MaxSim để tìm sự khớp tốt nhất cho từng token query trong document. Cách này cho phép tính toán trước (pre-indexing) như bi-encoder nhưng giữ được độ chính xác cao gần giống cross-encoder.
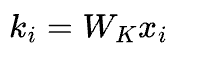 Phân tích độ trễ
Phân tích độ trễ
Kết luận
Việc xây dựng một hệ thống tìm kiếm hiệu quả không chỉ dừng lại ở việc chọn một mô hình embedding tốt. Các tùy chọn nâng cao như Cross-encoder reranking, Fine-tuning theo lĩnh vực, Distillation, hay ColBERT late interaction mang lại những sự đánh đổi thú vị giữa tốc độ và độ chính xác.
Một hệ thống tìm kiếm trưởng thành có thể kết hợp nhiều kỹ thuật này: một bi-encoder đã distillation cho lần truy xuất đầu, cross-encoder để reranking các ứng viên hàng đầu, và semantic caching để bỏ qua các công việc dư thừa.
Tất cả mã nguồn demo cho các kỹ thuật trên đều có sẵn tại GitHub để bạn có thể thử nghiệm và áp dụng ngay vào dự án của mình.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026