
TPU thế hệ thứ 8 của Google: Khám phá kiến trúc chuyên biệt cho kỷ nguyên AI
Google công bố hai biến thể TPU mới là TPU 8t và TPU 8i, được tối ưu hóa riêng cho việc huấn luyện quy mô lớn và suy luận tốc độ cao. Sự nâng cấp tập trung vào kiến trúc mạng Virgo, bộ tăng tốc CAE và hỗ trợ mô hình FP4 nhằm tăng cường hiệu suất cho AI tác nhân và các mô hình thế giới.

Tại Google, triết lý thiết kế TPU của chúng tôi luôn xoay quanh ba trụ cột chính: khả năng mở rộng, độ tin cậy và hiệu quả. Khi các mô hình AI phát triển từ các Mô hình Ngôn ngữ Lớn (LLM) dạng dày đặc sang các Mô hình Hỗn hợp Chuyên gia (Mixture-of-Experts - MoE) khổng lồ và các kiến trúc đòi hỏi lý luận phức tạp, phần cứng không chỉ cần tăng số phép toán dấu chấm động mỗi giây (FLOPS), mà còn phải tiến hóa để đáp ứng cường độ vận hành cụ thể của các khối lượng công việc mới nhất.
Sự trỗi dậy của AI tác nhân đòi hỏi hạ tầng có khả năng xử lý các cửa sổ ngữ cảnh dài và logic tuần tự phức tạp. Đồng thời, các mô hình thế giới (world models) đã xuất hiện như một bước tiến hóa cần thiết từ các kiến trúc dữ liệu chuỗi hiện nay, nơi các tác tử mới mô phỏng các kịch bản tương lai, dự đoán hậu quả và học hỏi thông qua "trí tưởng tượng" thay vì thử và sai rủi ro. Các TPU thế hệ thứ 8 (TPU 8t và TPU 8i) là câu trả lời của chúng tôi cho những thách thức này.
TPU thế hệ 8: Thiết kế chuyên biệt hóa
Nhận thấy rằng yêu cầu hạ tầng cho huấn luyện trước (pre-training), huấn luyện sau (post-training) và phục vụ thời gian thực đã phân hóa, thế hệ TPU thứ 8 của chúng tôi giới thiệu hai hệ thống riêng biệt: TPU 8t và TPU 8i. Đây là các thành phần chính của AI Hypercomputer của Google Cloud, một kiến trúc siêu máy tính tích hợp kết hợp phần cứng, phần mềm và mạng để hỗ trợ toàn bộ vòng đời AI. Cả hai hệ thống đều chia sẻ DNA cốt lõi của danh mục AI của Google và hỗ trợ toàn bộ vòng đời AI, nhưng mỗi hệ thống được xây dựng để giải quyết các nút thắt cổ chai riêng biệt và tối ưu hóa hiệu quả cho các giai đoạn phát triển quan trọng.
Ngoài ra, bằng cách tích hợp các header CPU dựa trên Arm Axion trên toàn bộ hệ thống TPU thế hệ thứ 8, chúng tôi đã loại bỏ nút thắt cổ chai của máy chủ gây ra bởi độ trễ chuẩn bị dữ liệu. Axion cung cấp khả năng tính toán để xử lý việc tiền xử lý dữ liệu phức tạp và điều phối, đảm bảo các TPU luôn được cung cấp dữ liệu và không bị dừng lại.
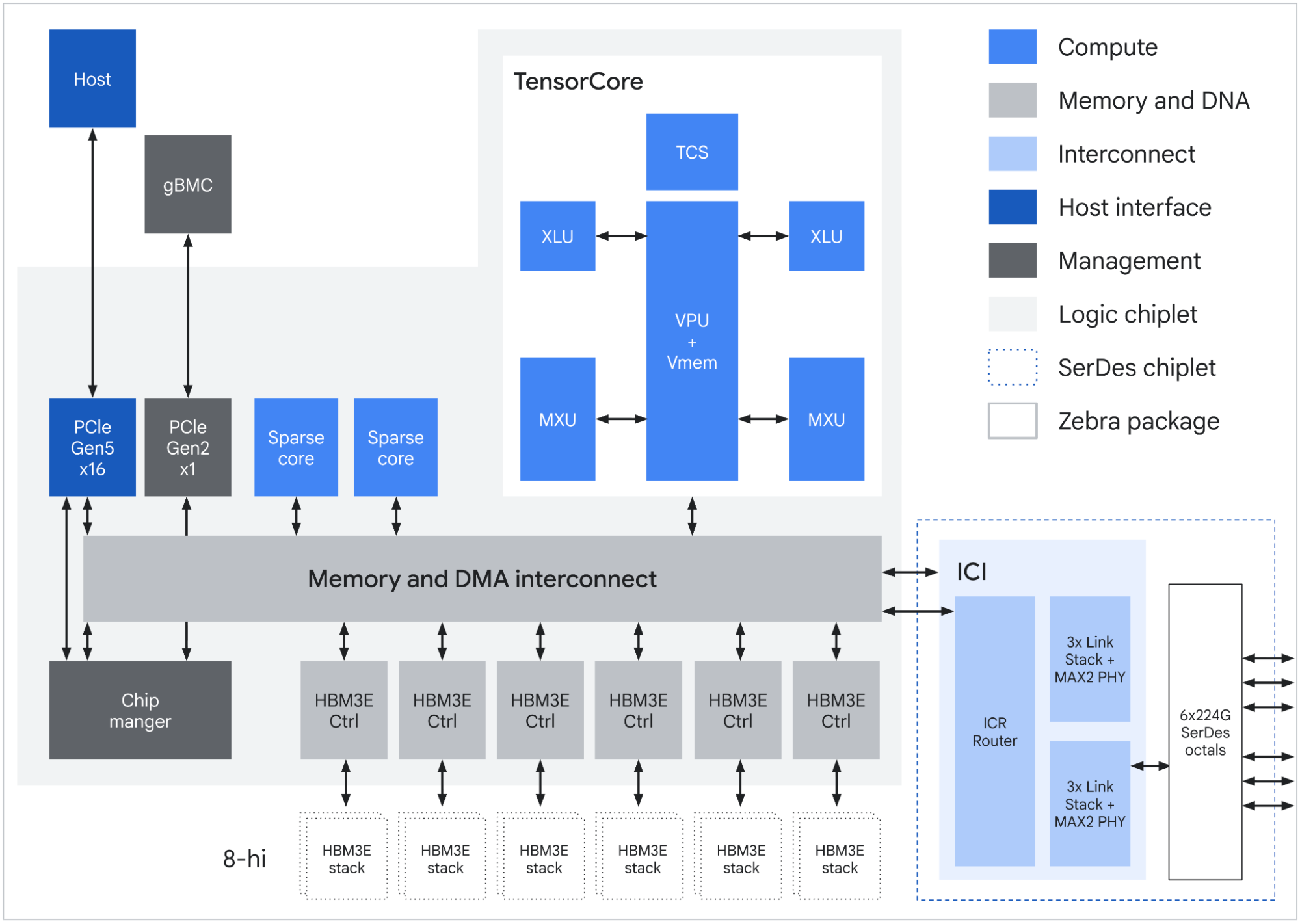 Sơ đồ khối ASIC của TPU 8t
Sơ đồ khối ASIC của TPU 8t
TPU 8t: Cỗ máy huấn luyện pre-training
Được tối ưu hóa cho huấn luyện trước quy mô lớn và các khối lượng công việc nặng về nhúng (embedding), TPU 8t sử dụng cấu trúc liên kết mạng hình xuyến 3D (3D torus network topology) đã được chứng minh ở quy mô còn lớn hơn: 9.600 chip trong một siêu cụm (superpod) duy nhất. TPU 8t được thiết kế để tối đa hóa thông lượng trên hàng trăm siêu cụm, đảm bảo các quá trình huấn luyện diễn ra đúng tiến độ.
Dưới đây là một số bước tiến chính của TPU 8t so với các thế hệ TPU trước:
Lợi thế của SparseCore: Trung tâm của TPU 8t là SparseCore, một bộ tăng tốc chuyên dụng được thiết kế để xử lý các mẫu truy cập bộ nhớ không đều của các phép tra cứu nhúng. Trong khi Đơn vị Nhân Ma trận (MXU) xử lý phép toán ma trận, SparseCore sẽ giải phóng các thao tác all-gather phụ thuộc vào dữ liệu, ngăn chặn các nút thắt cổ chai "zero-op" thường ám ảnh các chip mục đích chung.
Chồng chéo VPU/MXU và cân bằng mở rộng quy mô: TPU 8t được thiết kế để tối đa hóa việc sử dụng FLOPs được cấp phát. Bằng cách thực hiện việc mở rộng quy mô Đơn vị Xử lý Vector (VPU) cân bằng hơn, kiến trúc này giảm thiểu thời gian hoạt động vector bị lộ. Điều này cho phép chồng chéo tốt hơn giữa việc định lượng (quantization), softmax và layernorms với các phép nhân ma trận trong MXU, giúp chip luôn bận rộn thay vì chờ đợi các tác vụ vector tuần tự.
FP4 nguyên bản: TPU 8t giới thiệu dấu chấm động 4 bit (FP4) nguyên bản để vượt qua các nút thắt cổ chai băng thông bộ nhớ, tăng gấp đôi thông lượng MXU trong khi duy trì độ chính xác cho các mô hình lớn ngay cả khi định lượng ở độ chính xác thấp hơn. Bằng cách giảm số bit cho mỗi tham số, nền tảng này giảm thiểu việc di chuyển dữ liệu tốn năng lượng và cho phép các lớp mô hình lớn hơn vừa với bộ đệm phần cứng cục bộ để sử dụng tính toán đỉnh cao.
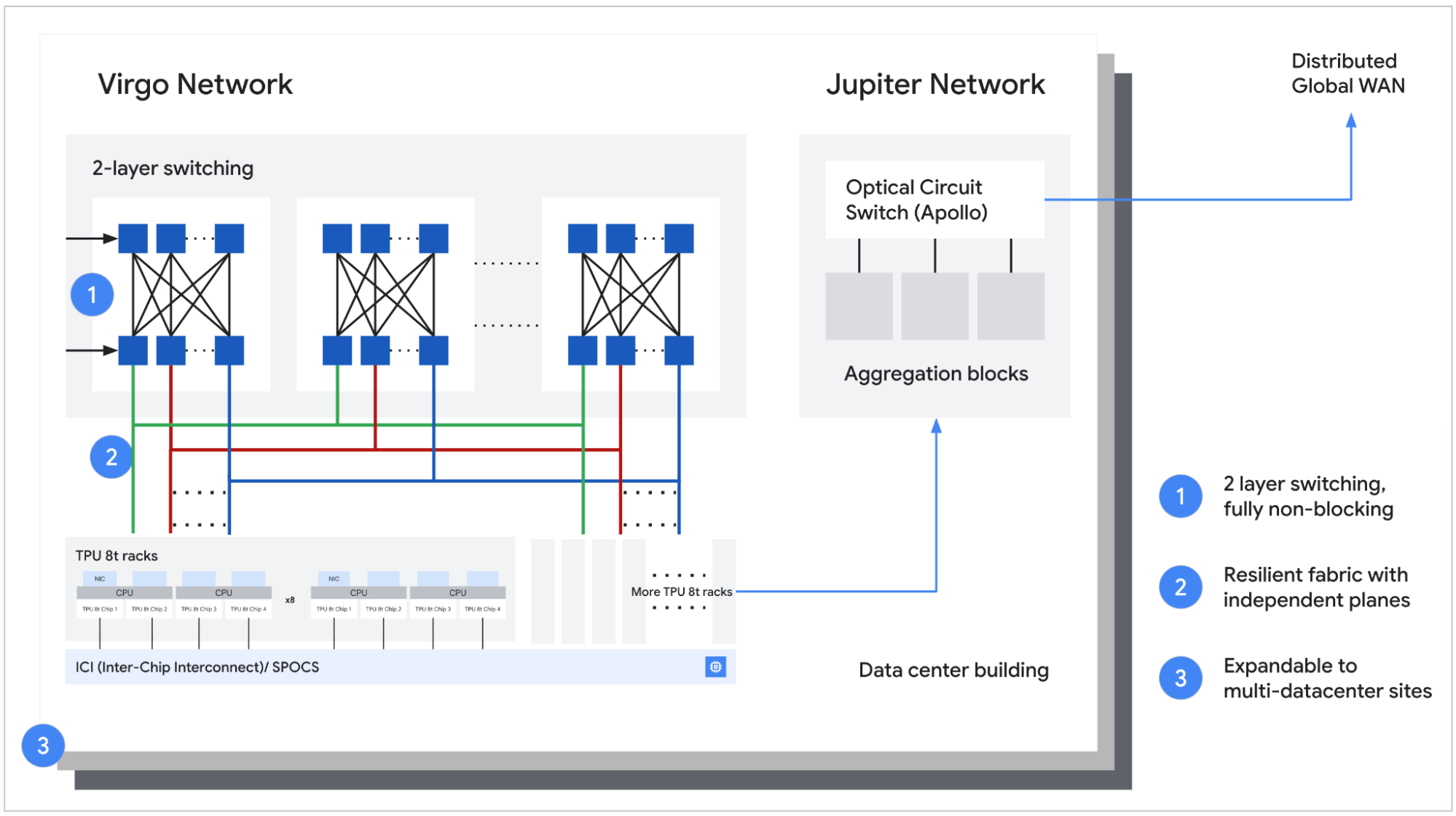 Kết nối cấp độ khung TPU 8t với nền tảng Virgo
Kết nối cấp độ khung TPU 8t với nền tảng Virgo
Cấu trúc liên kết mạng Virgo và tăng 4x băng thông trung tâm dữ liệu: Để hỗ trợ các yêu cầu dữ liệu khổng lồ của TPU 8t, chúng tôi giới thiệu Mạng Virgo. Kiến trúc mạng mới này cho phép tăng băng thông mạng trung tâm dữ liệu (DCN) lên tới 4x trên TPU 8t so với DCN. Mạng Virgo là một cấu trúc mở rộng quy mô được thiết kế cho các yêu cầu cực đoan của khối lượng công việc AI hiện đại.
Với băng thông kết nối giữa các chip (ICI) tăng gấp 2 và băng thông DCN thô mở rộng quy mô lên tới 4x so với thế hệ trước, TPU 8t giảm thiểu đáng kể các nút thắt cổ chai dữ liệu. Sử dụng JAX và Pathways, chúng tôi hiện có thể mở rộng quy mô huấn luyện phân tán vượt ra ngoài một cụm duy nhất lên hơn 1 triệu chip TPU. Mạng Virgo có thể kết nối hơn 134.000 chip TPU 8t với tới 47 petabits/giây băng thông hai chiều không chặn (non-blocking bi-sectional bandwidth) trong một cấu trúc duy nhất.
TPU 8i: Chuyên gia lấy mẫu và phục vụ
Được tối ưu hóa cho huấn luyện sau và lý luận đồng thời cao, chúng tôi thiết kế TPU 8i với bộ nhớ SRAM trên chip lớn nhất, một Bộ tăng tốc Tập thể mới (Collectives Acceleration Engine - CAE) và một cấu trúc liên kết mạng được tối ưu hóa để phục vụ gọi là Boardfly.
Bộ nhớ SRAM trên chip lớn: Với dung lượng SRAM trên chip lớn gấp 3 lần so với thế hệ trước, TPU 8i có thể lưu trữ bộ nhớ đệm KV (KV Cache) lớn hơn hoàn toàn trên silicon, giúp giảm thiểu đáng kể thời gian nhàn rỗi của các lõi trong quá trình giải mã ngữ cảnh dài.
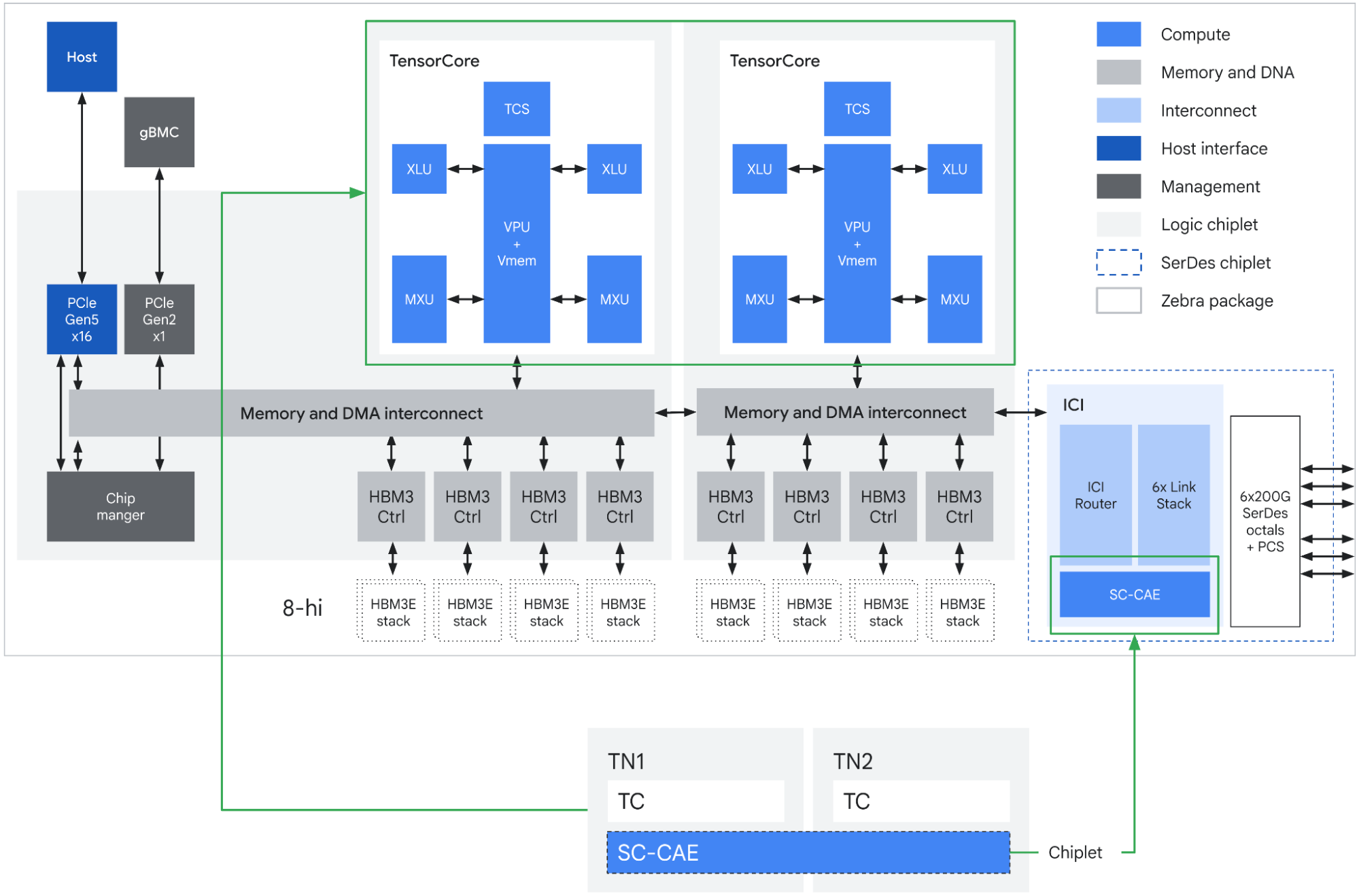 Sơ đồ khối ASIC của TPU 8i
Sơ đồ khối ASIC của TPU 8i
Bộ tăng tốc Tập thể (CAE): Để giải quyết nút thắt cổ chai lấy mẫu, TPU 8i sử dụng CAE, tổng hợp kết quả trên các lõi với độ trễ gần như bằng không, cụ thể là tăng tốc các bước giảm và đồng bộ hóa cần thiết trong quá trình giải mã tự động (auto-regressive decoding) và xử lý "chuỗi tư duy" (chain-of-thought). Bằng cách tích hợp một CAE chuyên dụng, TPU 8i giảm thêm 5 lần độ trễ trên chip của các hoạt động tập thể. Độ trễ thấp hơn cho mỗi thao tác tập thể có nghĩa là ít thời gian chờ đợi hơn, đóng góp trực tiếp vào thông lượng cao hơn cần thiết để chạy hàng triệu tác nhân đồng thời.
Cấu trúc liên kết ICI Boardfly: Trong khi hình xuyến 3D cho phép kết nối hàng nghìn chip để hoạt động gắn kết, một lưới lớn có nhiều bước nhảy (hops) hơn giữa các chip và độ trễ all-to-all cao hơn. Đối với 8i, chúng tôi thay đổi cách các chip kết nối với nhau trong các bảng kết nối hoàn toàn, sau đó được tổng hợp thành các nhóm. Sử dụng thiết kế bậc cao (high-radix), chúng tôi kết nối tới 1.152 chip này lại với nhau, giảm đường kính mạng và số lượng bước nhảy mà một gói dữ liệu phải thực hiện để đi qua hệ thống. Bằng cách cắt giảm các bước nhảy cần thiết cho giao tiếp all-to-all (trái tim của các mô hình MoE và lý luận), Boardfly đạt được mức cải thiện độ trễ lên tới 50% đối với các khối lượng công việc tốn nhiều băng thông.
Hiệu suất thế hệ trên thế hệ
Cam kết về việc thiết kế đồng bộ phần cứng và phần mềm của chúng tôi tiếp tục mang lại lợi ích. Khi so sánh với TPU Ironwood thế hệ thứ 7, các TPU thế hệ thứ 8 mang lại lợi ích to lớn:
- Hiệu suất theo giá thành huấn luyện: TPU 8t mang lại cải thiện hiệu suất trên mỗi đồng đô la lên tới 2,7 lần so với TPU Ironwood cho việc huấn luyện quy mô lớn.
- Hiệu suất theo giá thành suy luận: TPU 8i mang lại cải thiện hiệu suất trên mỗi đồng đô la lên tới 80% so với TPU Ironwood, đặc biệt là ở các mục tiêu độ trễ thấp cho các mô hình MoE lớn.
- Hiệu quả năng lượng: Cả hai chip đều mang lại hiệu suất trên mỗi watt tốt hơn tới 2 lần, yếu tố quan trọng để mở rộng quy mô thế hệ AI tiếp theo một cách bền vững.
Phần mềm hỗ trợ: Hệ sinh thái AI ưu tiên hiệu suất
Phần cứng chỉ mạnh mẽ như phần mềm điều khiển nó. TPU thế hệ thứ 8 được xây dựng trên cùng ngăn xếp ưu tiên hiệu suất mà chúng tôi tiên phong với các TPU Ironwood thế hệ thứ 7, được thiết kế để giúp phát triển kernel tùy chỉnh dễ tiếp cận mà không làm mất đi tính trừu tượng của các khung công tác cấp cao. Điều này bao gồm hỗ trợ sơ cấp cho Pallas (ngôn ngữ kernel tùy chỉnh của chúng tôi) và trải nghiệm PyTorch nguyên bản hiện đã có trong bản xem trước, cho phép các nhà phát triển mang các mô hình hiện có sang TPU một cách dễ dàng.
Bài viết liên quan

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026

Công nghệ
Đánh giá Sony Bravia Theater Bar 5: Thiết kế tối giản, chất âm đầy uy lực
13 tháng 5, 2026

Phần cứng
Tổng quan tình hình trung tâm dữ liệu AI: Cuộc đua năng lượng, tranh cãi pháp lý và những bước đột phá phần cứng
08 tháng 5, 2026