
Tỷ lệ sử dụng GPU cao có thể là "lừa dối": Vấn đề hệ thống ẩn khiến AI hiện đại chậm chạp
Tỷ lệ sử dụng GPU cao không đồng nghĩa với việc hệ thống AI đang hoạt động hiệu quả. Bài viết phân tích cách sự phân mảnh tài nguyên và các nút thắt I/O ẩn giấu có thể gây lãng phí hàng triệu đô la chi phí hạ tầng, ngay cả khi GPU dường như đang bận rộn.
Tỷ lệ sử dụng GPU cao có thể là "lừa dối": Vấn đề hệ thống ẩn khiến AI hiện đại chậm chạp
Vào lúc 2 giờ sáng, một đội ngũ hạ tầng nhận được cảnh báo vì độ trễ suy luận (inference latency) đột ngột tăng vọt 60%. Các bảng điều khiển (dashboard) gây khó hiểu vì chỉ số sử dụng GPU vẫn trông rất khỏe mạnh: 79%, 82%, 84%. Không có gì có vẻ sai sai nghiêm trọng cả. Tính năng tự động mở rộng quy mô (autoscaling) kích hoạt, thêm nhiều nút hơn, hóa đơn đám mây tăng lên, nhưng độ trễ hầu như không được cải thiện.
Một giờ sau, vấn đề thực sự hóa ra lại khá bình thường: ba nút đã âm thầm chuyển sang trạng thái tái xây dựng RAID bị suy giảm, làm giảm thông lượng lưu trữ đến mức làm "đói" các tác vụ suy luận lân cận. Trình lập lịch (scheduler) vẫn coi những nút này là "khá khỏe mạnh" vì các chỉ số GPU và bộ nhớ trông chấp nhận được. Nói một cách đơn giản, một trong các ổ lưu trữ trên những máy này đã bị lỗi hoặc không ổn định, và máy chủ đang bận rộn tái tạo dữ liệu bị mất trên các ổ còn lại. Các máy về mặt kỹ thuật vẫn trực tuyến. Chúng không "chết" đến mức phải bị loại khỏi dịch vụ. Nhưng hiệu suất đĩa của chúng đã bị chậm lại đáng kể.
Loại lỗi này đang ngày càng trở nên phổ biến trong hạ tầng AI hiện đại. Và nó phơi bày một ảo ảnh sâu hơn ẩn dưới nhiều hệ thống GenAI: GPU có thể bận rộn mà không mang lại hiệu quả sản xuất.
Sự phân biệt đó nghe có vẻ tinh tế. Về mặt tài chính, nó có thể đồng nghĩa với hàng triệu đô la.
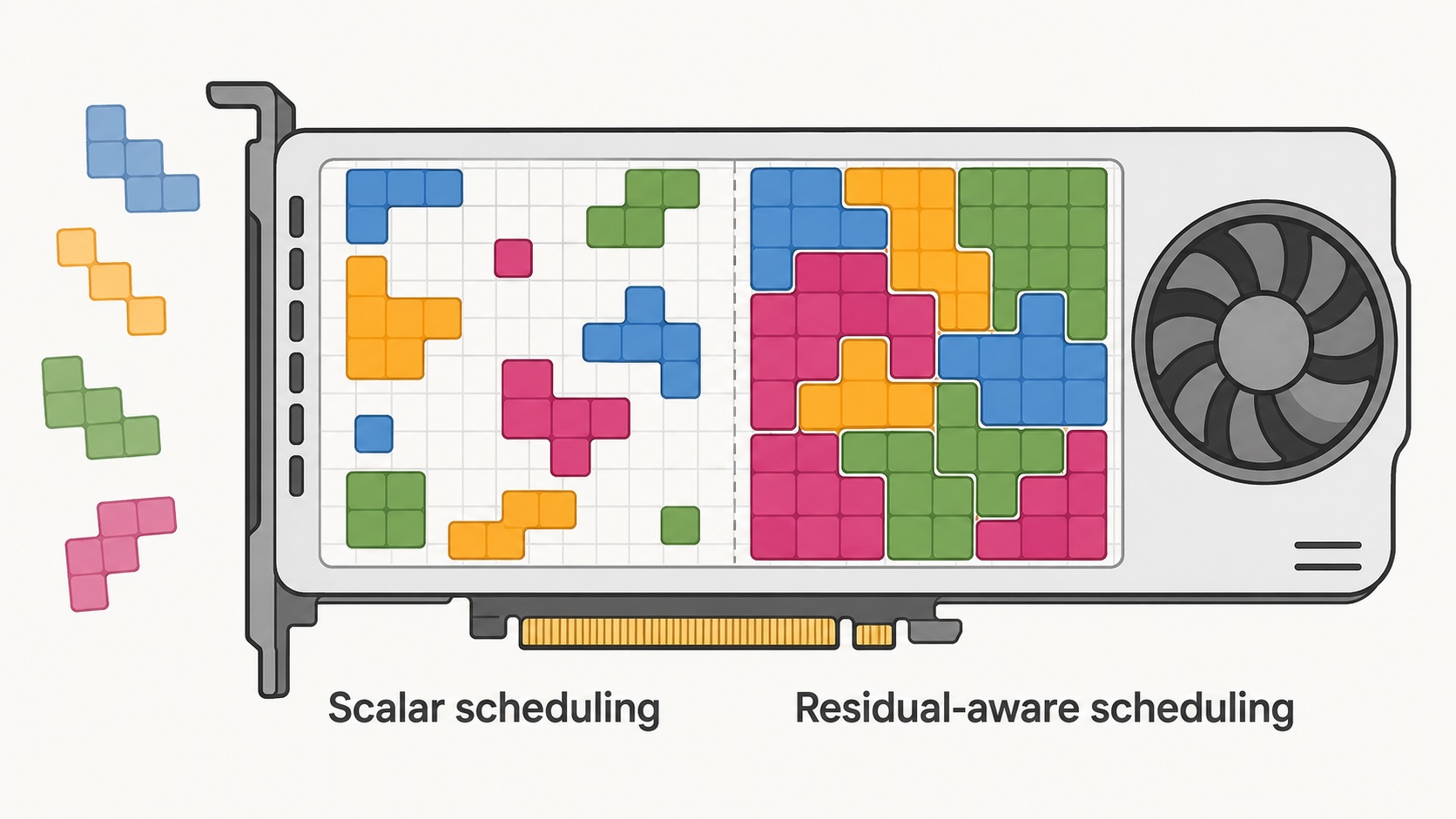
 Hình ảnh minh họa về sự phân mảnh tài nguyên
Hình ảnh minh họa về sự phân mảnh tài nguyên
Ảo ảnh về mức sử dụng
Tỷ lệ sử dụng GPU là một trong những chỉ số bị tin tưởng quá mức trong hạ tầng AI. Mức sử dụng cao tạo cảm giác hiệu quả. Nếu GPU chủ yếu bận rộn, cụm máy (cluster) có vẻ khỏe mạnh.
Tuy nhiên, mức sử dụng trung bình che giấu cấu trúc của những gì còn lại. Một cụm máy có thể báo cáo mức chiếm dụng GPU cao, khối lượng công việc hoạt động và sử dụng bộ nhớ nặng nề, trong khi vẫn có dung lượng hiệu quả kém. Vấn đề thường không phải là tài nguyên bị cạn kiệt, mà là tài nguyên còn lại chỉ tồn tại trong các kết hợp không thể sử dụng được.
Hãy tưởng tượng một thành phố lớn vào giờ cao điểm. Một số con đường trống trải. Những con đường khác bị tắc nghẽn hoàn toàn. Về mặt kỹ thuật, thành phố vẫn có công suất đường sá. Nhưng nếu các ngã tư sai bị tắc nghẽn, giao thông trên toàn hệ thống vẫn chậm lại.
Hệ thống AI phân tán hoạt động tương tự. Một cụm máy có thể vẫn chứa GPU dự phòng, HBM, lưu trữ và CPU, nhưng vẫn không thể chứa hiệu quả khối lượng công việc thực tế tiếp theo. Không phải vì công suất biến mất, mà vì công suất còn lại tồn tại trong các "hình dạng" sai lệch.
Sự phân mảnh: Chế độ lỗi vô hình
Hãy xem xét ba nút sau một đợt bùng nổ của các khối lượng công việc GenAI hỗn hợp:
- Nút A: GPU Có sẵn, HBM Gần đầy, Băng thông lưu trữ Có sẵn, I/O CPU Có sẵn.
- Nút B: GPU Có sẵn, HBM Có sẵn, Băng thông lưu trữ Bão hòa, I/O CPU Có sẵn.
- Nút C: GPU Hạn chế, HBM Có sẵn, Băng thông lưu trữ Có sẵn, I/O CPU Bão hòa.
Bây giờ, giả sử một khối lượng công việc suy luận mới đến yêu cầu: GPU vừa phải, HBM vừa phải, băng thông lưu trữ khỏe mạnh và dung lượng I/O khỏe mạnh.
Trên toàn cụm máy, tổng tài nguyên vẫn đủ. Nhưng không có nút nào có sự kết hợp tài nguyên còn lại phù hợp. Khối lượng công việc không vừa chỗ nào một cách sạch sẽ.
Đây là sự phân mảnh tài nguyên. Cụm máy không trống. Nó bị phân mảnh thành các phần sót lại khó sử dụng hiệu quả.
Một cụm máy có thể có GPU dự phòng và hàng đợi tăng lên
Đây là phần phản trực giác nhất của toàn bộ vấn đề. Một cụm máy có thể đồng thời có: GPU dự phòng, thời gian chờ hàng đợi tăng, độ trễ tồi tệ hơn và thông lượng giảm.
Thoạt nhìn, điều đó nghe có vẻ mâu thuẫn. Thực tế thì không.
Nếu những GPU "trống" duy nhất nằm trên các nút có băng thông lưu trữ đã quá tải, độ sâu hàng đợi SSD đang tăng vọt hoặc CPU I/O bị tiêu thụ bởi các tác vụ nền, thì những GPU đó không có ý nghĩa sẵn sàng cho khối lượng công việc hữu ích tiếp theo.
Một trình lập lịch tham lam vẫn có thể đặt các tác vụ vào đó. Những tác vụ đó sau đó chạy chậm hơn, tăng sự cạnh tranh, kéo dài thời gian chờ hàng đợi và để lại sự phân mảnh tồi tệ hơn.
Tại sao GenAI thay đổi cảnh giới nút thắt cổ chai
Các trình lập lịch truyền thống được thiết kế cho môi trường mà CPU, bộ nhớ, GPU và mạng chi phối các quyết định đặt vị trí. Các hệ thống GenAI hiện đại đã thay đổi hình dạng áp lực hạ tầng:
- Các đường ống (pipeline) nặng về truy xuất có thể làm bão hòa băng thông SSD.
- Các tác vụ suy luận tích lũy bộ nhớ đệm KV theo thời gian.
- Việc tải điểm kiểm tra (checkpoint) có thể làm quá tải bộ nhớ đối tượng.
- Các khối lượng công việc đa phương thức tạo ra sự di chuyển dữ liệu theo đợt.
- Các tác vụ bảo trì nền âm thầm đánh cắp chu kỳ CPU vốn dùng để cấp dữ liệu cho GPU.
Sự suy giảm lưu trữ cấp nút có thể làm giảm thông lượng hiệu quả lâu trước khi một nút về mặt kỹ thuật bị lỗi.
Một GPU bị "đói" vẫn là một GPU đắt đỏ
Đây là nơi vấn đề kinh tế trở nên nghiêm trọng. Hạ tầng AI hiện đại rất đắt đỏ. Giá công khai năm 2026 cho quyền truy cập NVIDIA H100 thường dao động từ vài đô la thấp một chữ số mỗi giờ GPU đến hơn 10$/giờ, tùy thuộc vào nhà cung cấp và mô hình cam kết.
Hãy nhân quy mô đó lên một đội tàu lớn. Một cụm máy H100 1.000 GPU hoạt động với chi phí kết hợp khoảng 3$/GPU/giờ tốn khoảng:
- 3.000$/giờ,
- 72.000$/ngày,
- và khoảng 26 triệu$/năm,
trước khi tính đến mạng, lưu trữ, điều phối và chi phí kỹ thuật.
Bây giờ, hãy tưởng tượng sự phân mảnh và sự đình trệ I/O âm thầm lãng phí chỉ 10% thời gian GPU sản xuất. Điều đó trở thành khoảng:
- 300$/giờ,
- 7.200$/ngày,
- và khoảng 2,6 triệu$/năm
chi phí hạ tầng không hiệu quả. Không phải vì GPU biến mất, mà vì hệ thống không sử dụng chúng hiệu quả.
Đây là sự thay đổi quan trọng mà nhiều đội ngũ hạ tầng bắt đầu nhận ra: Chỉ số thực sự không phải là phân bổ GPU. Nó là số giờ GPU sản xuất.
Lập lịch nhận biết dư thừa (Residual-Aware Scheduling)
Hầu hết các trình lập lịch hỏi một câu đơn giản đánh lừa: "Khối lượng công việc này có vừa vào nút này không?"
Lập lịch nhận biết dư thừa hỏi một câu quan trọng hơn: "Việc đặt vị trí này tạo ra loại cụm máy dư thừa nào?"
Ý tưởng đó nằm ở trung tâm của Residual-Aware Geometric Packing (RAGP). Thay vì giảm một nút thành một vài bộ đếm vô hướng, RAGP coi dung lượng dư thừa là một hình dạng đa chiều.
Ở mức độ cao:
- Các nút không khả thi bị loại bỏ,
- Trình lập lịch mô phỏng các tài nguyên còn lại sau khi đặt vị trí,
- Nó ưu tiên các vị trí có các vectơ tài nguyên còn lại vẫn hữu ích cho các khối lượng công việc trong tương lai.
Bước cuối cùng đó cực kỳ quan trọng. Hai quyết định đặt vị trí có thể đều xuất hiện đúng lập tức trong khi tạo ra các trạng thái cụm máy hoàn toàn khác nhau trong tương lai. Một cái bảo toàn dung lượng dư thừa khỏe mạnh. Cái kia mắc kẹt tài nguyên vào các mảnh vụn không thể sử dụng.
Mở rộng RAGP thành RAGP-I/O
Công thức RAGP ban đầu chủ yếu lý luận về CPU, RAM, tính toán GPU, HBM và mạng. Điều đó hoạt động khá tốt trong các môi trường bị chi phối bởi tính toán.
Các khối lượng công việc GenAI đã thay đổi cảnh giới nút thắt cổ chai. Trong các hệ thống thực:
- Sự cạnh tranh SSD,
- Độ sâu hàng đợi lưu trữ,
- Trạng thái tái xây dựng RAID bị suy giảm,
- Áp lực truy xuất,
- Và sự bão hòa CPU I/O
có thể ảnh hưởng đến thông lượng nặng nề giống như chính việc sử dụng GPU.
RAGP-I/O mở rộng không gian lập lịch bằng cách kết hợp rõ ràng: băng thông lưu trữ và CPU I/O vào cả logic khả thi và đặt vị trí. Thay vì lý luận trên năm chiều, trình lập lịch lý luận trên bảy chiều: CPU, RAM, GPU SM, HBM, mạng, băng thông lưu trữ và CPU I/O.
Về mặt khái niệm, điều này nghe có vẻ như một phần mở rộng nhỏ. Về mặt vận hành, nó thay đổi hành vi của trình lập lịch đáng kể một khi lưu trữ trở thành một ràng buộc tích cực.
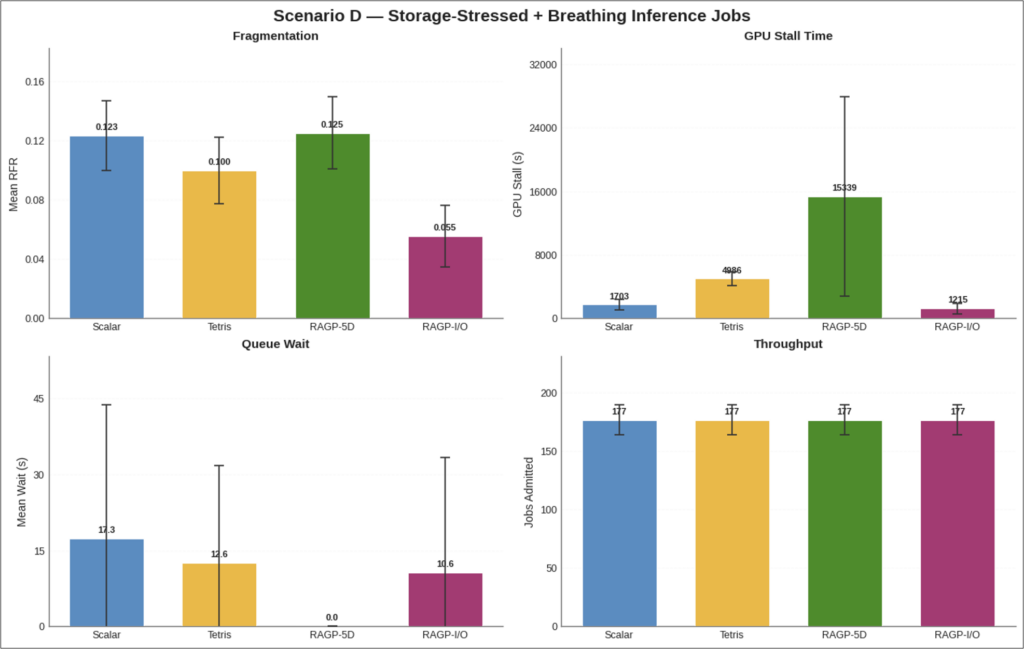 Biểu đồ so sánh kết quả mô phỏng
Biểu đồ so sánh kết quả mô phỏng
Kết quả quan trọng nhất
Kết quả quan trọng nhất không chỉ đơn giản là "RAGP‑I/O tạo ra sự phân mảnh thấp hơn". Kết quả sâu sắc hơn là:
Khi lưu trữ và I/O trở thành các ràng buộc chi phối, các trình lập lịch hợp lý khác sẽ bị đánh lừa một cách có hệ thống nếu bỏ qua các chiều đó.
Đó là một hiểu biết sâu sắc về hệ thống rộng hơn. Vì các khối lượng công việc GenAI hiện đại ngày càng nặng về truy xuất, nhạy cảm với lưu trữ và phát triển động, trình lập lịch không còn có thể xử lý GPU như một thiết bị tính toán cô lập. Toàn bộ đường dẫn dữ liệu đều quan trọng.
Sự đình trệ: Thuế vô hình tốn kém
Sự phân mảnh một mình không phải là vấn đề vận hành. Triệu chứng đau đớn hơn là sự đình trệ (stall).
Các tác vụ xuất hiện "đang chạy", nhưng tiến trình có ý nghĩa chậm lại vì nút không thể cấp dữ liệu cho GPU hiệu quả. Một khối lượng công việc suy luận có thể hiển thị mức chiếm dụng GPU cao và sử dụng bộ nhớ khỏe mạnh trong khi các nhân (kernels) dành một lượng thời gian đáng kể để chờ di chuyển lưu trữ, truy xuất hoặc các đường ống dữ liệu phía CPU bị quá tải.
Trong thực tế, các đội ngũ hạ tầng thường nhận thấy hành vi vấn đề trước khi họ xác định nó theo số liệu. Một số nút đơn giản là "cảm thấy bị nguyền rủa", tạo ra độ trễ ồn ào hơn hoặc làm suy giảm các khối lượng công việc lân cận một cách bất ngờ.
Bài học hệ thống lớn hơn
Bài viết này cuối cùng là về nhiều hơn là các trình lập lịch. Nó là về hành vi hệ thống. Các hệ thống khỏe mạnh không được định nghĩa thuần túy bởi mức sử dụng. Chúng được định nghĩa bởi dòng chảy được phối hợp. Mẫu hình này xuất hiện ở khắp nơi: hệ thống giao thông, chuỗi cung ứng, cơ sở dữ liệu phân tán, hạ tầng đám mây và thị trường tài chính.
Tối ưu hóa cục bộ không giống như tối ưu hóa toàn cầu. Một trình lập lịch được tối ưu hóa chỉ cho việc đặt vị trí ngay lập tức có thể âm thầm làm hỏng thông lượng theo chiều dài. Một cụm máy trông bận rộn vẫn có thể không hiệu quả về mặt kinh tế. Và một GPU xuất hiện hoạt động vẫn có thể dành một lượng thời gian có ý nghĩa để chờ đợi hệ thống xung quanh nó.
Các đội ngũ hạ tầng nên giám sát kỹ hơn gì
Chỉ riêng mức sử dụng GPU không còn đủ. Giám sát hạ tầng GenAI nghiêm túc ngày càng yêu cầu khả năng hiển thị vào:
- Áp lực HBM,
- Tiêu thụ băng thông lưu trữ,
- Độ sâu hàng đợi SSD,
- Lạm phát thời gian chạy so với thời lượng dự kiến,
- Sử dụng CPU I/O,
- Trạng thái lưu trữ bị suy giảm,
- Và sự chậm lại cấp nút so với thời gian hoàn thành dự kiến.
Nếu các khối lượng công việc liên tục hoàn thành chậm hơn 20%, 30% hoặc 40% trên các nút cụ thể bất chấp các chỉ số mức sử dụng trông khỏe mạnh, trình lập lịch nên xử lý các nút đó khác nhau. Đó thường là nơi sự không hiệu quả ẩn giấu sống.
Hạ tầng AI hiện đại ẩn giấu một chuỗi cung ứng khổng lồ của tính toán, lưu trữ, bộ nhớ, mạng và sự phối hợp dưới trải nghiệm người dùng trơn tru đánh lừa. Người dùng thấy các lời nhắc và phản hồi. Bảng điều khiển hiển thị phần trăm GPU. Ở đâu đó ở giữa, một trình lập lịch âm thầm quyết định xem cụm máy thực sự khỏe mạnh hay chỉ đơn giản là trông bận rộn.
Sự phân biệt đó quan trọng hơn bao giờ hết. Vì trong các hệ thống GenAI hiện đại, câu hỏi thực sự không còn là: "GPU có đang bận không?" Mà là: "GPU có đang bận rộn một cách hiệu quả không?"