
Uber phân quyền kho dữ liệu Hive: Di chuyển 16.000 tập dữ liệu và 10 PB đảm bảo phân tích không gián đoạn
Uber đã chuyển đổi kiến trúc kho dữ liệu Hive từ tập trung sang phân tán, di chuyển thành công hơn 16.000 tập dữ liệu với tổng dung lượng hơn 10 petabyte. Việc sử dụng phương pháp liên kết dựa trên con trỏ giúp đảm bảo thời gian chết bằng không, tăng cường kiểm soát quyền truy cập và cải thiện khả năng quản trị cho các khối lượng công việc phân tích quy mô lớn.
Uber đã thiết kế lại kho dữ liệu Hive của mình để phân tán hơn 16.000 tập dữ liệu với tổng dung lượng hơn 10 petabyte, nhằm giải quyết các thách thức về khả năng mở rộng, vận hành và bảo mật. Trước đây, một phiên bản Hive đơn lẻ (monolithic) chứa tất cả dữ liệu kinh doanh giao hàng dưới một không gian tên duy nhất, tạo ra rủi ro về sự cố lan truyền, tranh giành tài nguyên và các nút thắt trong quản trị. Bằng cách liên kết các cơ sở dữ liệu Hive, Uber nhằm duy trì tính sẵn sàng cao, thực thi quyền truy cập tối thiểu và cho phép các tập dữ liệu theo từng lĩnh vực cụ thể mở rộng độc lập, mang lại sự tự chủ vận hành cho các đội ngũ.
/filters:no_upscale()/news/2026/04/uber-hive-decentralized-data/en/resources/2newvsold-1775412962603.jpeg) Quy trình di chuyển tập dữ liệu Hive dựa trên con trỏ
Quy trình di chuyển tập dữ liệu Hive dựa trên con trỏ
Việc di chuyển tận dụng cách tiếp cận dựa trên con trỏ (pointer-based) trong Hive Metastore, cho phép chuyển hướng tập dữ liệu đến các vị trí HDFS mới mà không cần sao chép hàng petabyte dữ liệu. Mỗi tập dữ liệu được sao chép một lần đến vị trí đích phân tán, sau đó con trỏ gốc được cập nhật, đảm bảo rằng các truy vấn vẫn tiếp tục hoạt động trong quá trình di chuyển.
Vijayant Soni, kỹ sư tại Uber, giải thích:
Việc cập nhật con trỏ tập dữ liệu trong HMS là một thao tác diễn ra trong tích tắc, đảm bảo hoạt động liên tục cho các khối lượng công việc quan trọng. Cách tiếp cận này đảm bảo thời gian chết bằng không cho các công việc phân tích và quy trình máy học phụ thuộc vào Hive.
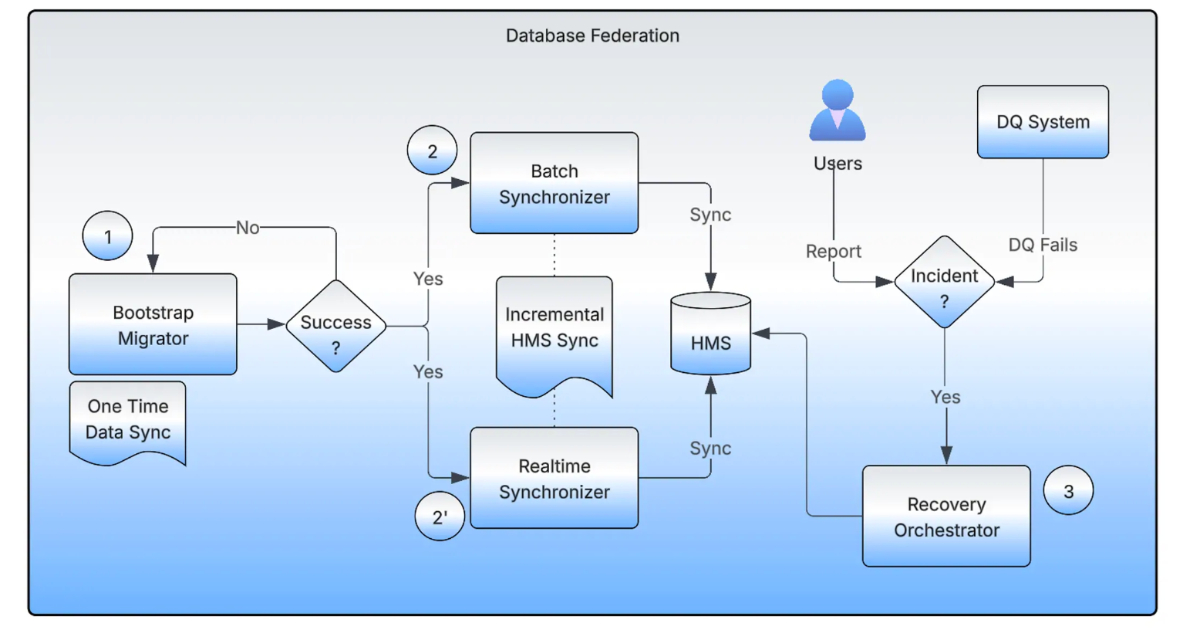
Hệ thống hỗ trợ quá trình di chuyển này bao gồm bốn thành phần chính: Bootstrap Migrator, Realtime Synchronizer, Batch Synchronizer và Recovery Orchestrator. Bootstrap Migrator quản lý việc di chuyển tập dữ liệu ban đầu, sử dụng các công việc Spark phân tán và xác thực checksum để kiểm tra tính toàn vẹn. Realtime và Batch Synchronizers duy trì sự đồng bộ metadata giữa nguồn và đích trong quá trình di chuyển, hỗ trợ cập nhật hai chiều trong khi các nhóm tiếp tục đọc và ghi dữ liệu. Recovery Orchestrator theo dõi bản sao lưu con trỏ, cho phép khôi phục an toàn nếu phát hiện sự không nhất quán. Các xác thực có sự tham gia của con người và kiểm tra tự động hóa này cho phép các nhóm thực hiện việc di chuyển một cách tự tin và giảm thiểu rủi ro vận hành.
/filters:no_upscale()/news/2026/04/uber-hive-decentralized-data/en/resources/2federated-1775412962603.jpeg) Kiến trúc của hệ thống Liên kết Cơ sở dữ liệu
Kiến trúc của hệ thống Liên kết Cơ sở dữ liệu
Kiến trúc phân tán của Uber giải quyết một số hạn chế của mô hình đơn lẻ cũ. Trong hệ thống cũ, nhiều nhóm cạnh tranh cùng một tài nguyên tính toán và lưu trữ, dẫn đến hiệu ứng "hàng xóm ồn ào" có thể làm chậm các khối lượng công việc quan trọng. Các quyền ACL rộng rãi làm tăng phạm vi ảnh hưởng của cấu hình sai, trong khi quản trị tập trung làm chậm các bản cập nhật và tạo ra nút thắt cổ chai. Bằng cách phân tán cơ sở dữ liệu Hive và thực thi các quy tắc ACL nghiêm ngặt ở cấp độ miền, các nhóm nắm quyền sở hữu tập dữ liệu, cải thiện khả năng quan sát, tuân thủ và hiệu quả quy trình làm việc.
Quá trình di chuyển cũng giúp giảm chi phí lưu trữ bằng cách tránh các bản sao tập dữ liệu dư thừa và đơn giản hóa việc đưa các tập dữ liệu mới vào hệ thống. Các quy trình tự động hóa, bao gồm kiểm tra trước khi di chuyển và ghi nhật ký kiểm toán, đảm bảo rằng các lần di chuyển bảo toàn tính toàn vẹn của dữ liệu và tuân thủ các quy định. Các kỹ sư có thể theo dõi tiến độ thông qua các bảng điều khiển theo dõi trạng thái tập dữ liệu, cập nhật con trỏ và số liệu đồng bộ hóa, mang lại sự minh bạch và sự tự tin trong vận hành. Trong suốt quá trình di chuyển, hàng nghìn tập dữ liệu đã được chuyển đi, hơn 7 triệu lần đồng bộ HMS đã được thực hiện và hơn 1 PB không gian HDFS đã được thu hồi bằng cách xóa các tập dữ liệu cũ.
Cách tiếp cận này hỗ trợ việc mở rộng liên tục và đảm bảo rằng các tập dữ liệu mới có thể được thêm vào mà không làm gián đoạn các khối lượng công việc hiện có. Bằng cách phân bổ trách nhiệm cho các nhóm, Uber giảm sự phụ thuộc vào nhóm vận hành trung tâm, rút ngắn vòng lặp phản hồi và cải thiện khả năng phục hồi của hệ sinh thái phân tích.