
Voxtral TTS: Hướng dẫn sao chép giọng nói khi bộ mã hóa (Encoder) bị thiếu
Mô hình Voxtral-4B-TTS của Mistral sở hữu khả năng chuyển đổi văn bản thành giọng nói ấn tượng nhưng lại thiếu trọng số của bộ mã hóa âm thanh, gây khó khăn cho việc sao chép giọng nói tùy chỉnh. Bài viết này sẽ đi sâu vào kiến trúc của Voxtral và trình bày phương pháp sử dụng Gradient Descent để tái tạo mã hóa âm thanh từ dữ liệu có sẵn, giúp người dùng vẫn có thể thực hiện sao chép giọng nói dù thiếu encoder.

Mới đây, Mistral đã ra mắt Voxtral-4B-TTS, một mô hình chuyển đổi văn bản thành giọng nói (Text-to-Speech - TTS) mạnh mẽ với hiệu suất vượt trội so với ElevenLabs v2.5 Flash trong các bài kiểm thử nội bộ. Điểm nổi bật nhất của Voxtral là khả năng sao chép giọng nói (voice cloning) và kích thước đủ nhỏ để chạy cục bộ (local inference), tạo nên sự quan tâm lớn từ cộng đồng công nghệ.
Tuy nhiên, một vấn đề lớn đã xuất hiện: Mistral đã loại bỏ trọng số của bộ mã hóa (encoder) trong autoencoder âm thanh. Điều này đồng nghĩa với việc người dùng không thể tự do sao chép bất kỳ giọng nói nào mà chỉ có thể sử dụng các giọng nói có sẵn do Mistral cung cấp. Đây là một hạn chế lớn so với những gì được công bố trong bài báo khoa học ban đầu.
Trong bài viết này, chúng ta sẽ cùng khám phá kiến trúc của Voxtral TTS và tìm hiểu cách giải quyết vấn đề thiếu encoder bằng cách tái tạo mã hóa âm thanh.
Tổng quan kiến trúc Voxtral TTS
Voxtral-4B-TTS là một mô hình với 4 tỷ tham số, sử dụng xương sống (backbone) là mô hình ngôn ngữ tự hồi quy (autoregressive LLM) Ministral 3B. Về cơ bản, mô hình nhận đầu vào là các token âm thanh đại diện cho giọng nói cần sao chép và các token văn bản cần chuyển thành giọng.
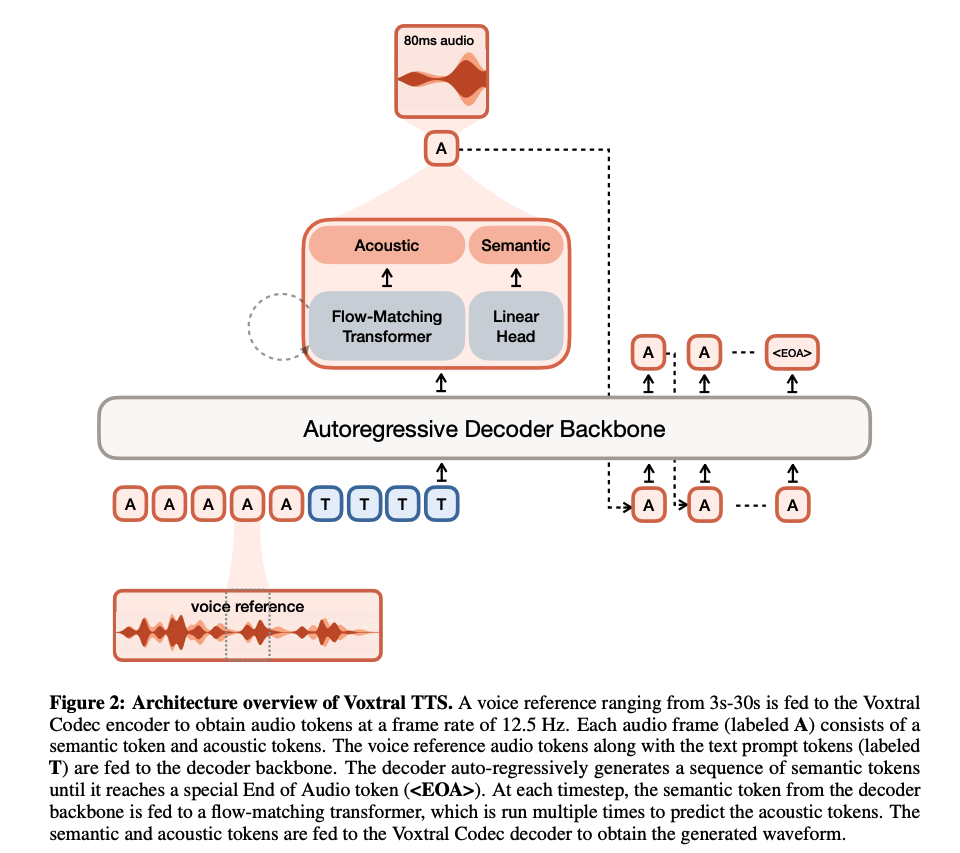 Kiến trúc Voxtral TTS
Kiến trúc Voxtral TTS
Một điểm quan trọng cần lưu ý là cả âm thanh tham chiếu và âm thanh được tạo ra đều được chia thành các token không chồng lấn và độc lập, mỗi token đại diện cho 80ms âm thanh. Cơ chế này cho phép mô hình thực hiện streaming âm thanh tự nhiên. Đầu của mô hình (head) là sự kết hợp giữa việc dự đoán token rời rạc (discrete tokens) và quá trình khớp dòng (flow-matching) để tạo ra các thành phần ngữ nghĩa và âm học.
Vấn đề về Audio Autoencoder
Để hoạt động, Voxtral cần một thành phần gọi là audio autoencoder (Voxtral Codec). Mô hình này chịu trách nhiệm tạo ra các token ngữ nghĩa (semantic) và âm học (acoustic) từ âm thanh đầu vào. Kiến trúc điển hình là encoder -> bottleneck -> decoder.
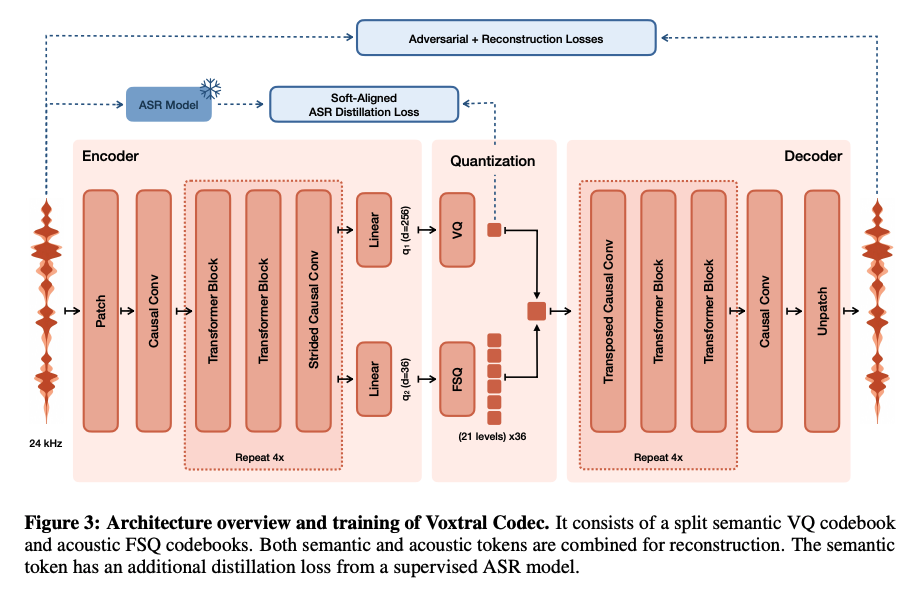 Audio Autoencoder
Audio Autoencoder
Tuy nhiên, Mistral chỉ công bố trọng số của decoder mà giữ lại encoder. Do decoder không thể đảo ngược (không invertible), chúng ta không thể tự nhiên đưa một đoạn âm thanh bất kỳ vào để lấy token làm điều kiện cho việc sao chép giọng nói.
Trong phần bottleneck, Voxtral sử dụng hai loại token:
- Semantic tokens (256-dim): Được liên kết với trạng thái tiềm ẩn của mô hình Whisper (ASR), đại diện cho nội dung văn bản/ngữ nghĩa.
- Acoustic tokens (36 scalar): Đại diện cho đặc điểm giọng nói, sử dụng kỹ thuật Finite Scalar Quantization (FSQ).
Giải pháp: Tái tạo mã hóa bằng Gradient Descent
Vì không có encoder, chúng ta cần tìm cách "đoán" mã hóa (codes) từ một đoạn âm thanh mục tiêu. Cách tiếp cận ở đây là sử dụng thuật toán Gradient Descent để huấn luyện trực tiếp các mã hóa này sao cho khi đưa qua decoder, âm thanh tái tạo lại giống nhất với âm thanh gốc.
Thách thức với token rời rạc
Các token trong Voxtral là rời rạc (discrete), khiến việc tối ưu hóa gradient trở nên khó khăn. Để giải quyết, tác giả sử dụng kỹ thuật Straight-Through Estimator (STE).
- Với Acoustic tokens: Sử dụng hàm tanh và làm tròn (rounding) để lượng tử hóa, nhưng trong quá trình lan truyền ngược (backward), gradient vẫn đi qua giá trị liên tục.
- Với Semantic tokens: Thay vì chọn một embedding cố định từ 8192 lựa chọn, ta sử dụng một phân phối xác suất mềm (soft probabilities) để tính toán embedding có trọng số, giúp gradient chảy trôi chảy.
Hàm mất mát (Loss Function)
Chỉ sử dụng L1 loss để tái tạo sóng âm thường không đủ do tính chất phức tạp của tín hiệu âm tần cao. Tác giả đã bổ sung thêm các loss khác:
- STFT Loss: Sử dụng biến đổi Fourier thời gian ngắn để so sánh đặc điểm tần số.
- Speaker Loss: Sử dụng các mô hình nhận diện người nói (như SpeechBrain) để đảm bảo giọng nói tái tạo có cùng đặc điểm nhận dạng với giọng gốc.
Kết quả nghiên cứu
Quá trình huấn luyện được thực hiện trong 5000 epochs trên một máy Mac sử dụng chip M-series. Mục tiêu ở đây là "overfitting" (quá khớp) các tham số mã hóa vào một mẫu âm thanh duy nhất dài 8 giây.
Kết quả cho thấy âm thanh tái tạo từ các mã hóa được huấn luyện rất giống với đoạn âm thanh gốc. Điều này chứng minh rằng dù thiếu encoder chính thức, chúng ta vẫn có thể sử dụng các kỹ thuật tối ưu hóa sâu để giải mã và sao chép giọng nói trên Voxtral.
Đây là một bước tiến thú vị, mở ra cơ hội cho cộng đồng phát triển các ứng dụng sao chép giọng nói tùy chỉnh dựa trên nền tảng Voxtral mạnh mẽ này.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026