
Xây dựng công cụ trích xuất tài liệu B2B: Quy tắc (Regex) hay LLM hiệu quả hơn?
Bài viết so sánh thực tế giữa phương pháp dựa trên quy tắc (sử dụng pytesseract và regex) và phương pháp sử dụng LLM (Ollama cùng LLaMA 3) trong việc trích xuất dữ liệu từ các biểu mẫu đơn hàng B2B. Kết quả cho thấy LLM vượt trội trong việc xử lý các định dạng tài liệu đa dạng, trong khi quy tắc truyền thống vẫn là lựa chọn tối ưu cho các tài liệu chuẩn hóa và yêu cầu tốc độ cao.

Hãy tưởng tượng bạn đang làm việc trong nhóm vận hành của một công ty quy mô vừa. Mỗi ngày, đội ngũ của bạn phải xử lý hàng loạt biểu mẫu đơn hàng từ các khách hàng B2B khác nhau. Về lý thuyết, tất cả chúng đều chứa thông tin giống nhau: ID khách hàng, số đơn hàng (PO Number), ngày giao hàng và các mặt hàng đã đặt.
Tuy nhiên, trên thực tế, mỗi tài liệu lại có một giao diện hoàn toàn khác nhau. Một khách hàng có thể đặt số đơn hàng ở góc trên bên trái, trong khi người khác lại đặt ở góc dưới bên phải. Một số ghi là “PO Number”, những người khác lại dùng “Order ID”, “Order Reference” hay một thuật ngữ hoàn toàn khác.
Đối với con người, việc này thường không gây khó khăn. Chúng ta nhìn vào tài liệu, hiểu ngữ cảnh và ngay lập tức nhận ra thông tin nào có ý nghĩa. Nhưng đối với các hệ thống tự động hóa truyền thống, đây lại là một thách thức lớn: Một quy tắc regex có thể tìm kiếm cụm từ “PO Number: ”, nhưng sẽ xảy ra gì nếu khách hàng tiếp theo sử dụng “Order Reference: ” thay thế?
Đó chính là vấn đề mà bài viết này sẽ giải quyết. Chúng ta sẽ so sánh hai cách tiếp cận khác nhau để trích xuất dữ liệu có cấu trúc từ các biểu mẫu đơn hàng B2B:
- Cách tiếp cận truyền thống dựa trên quy tắc sử dụng pytesseract và regex.
- Cách tiếp cận dựa trên LLM sử dụng pytesseract, Ollama và LLaMA 3.
Mục tiêu không phải để chứng minh LLM luôn tốt hơn, mà để trả lời câu hỏi: Khi nào các quy trình trích xuất truyền thống bắt đầu đạt đến giới hạn khi độ phức tạp tăng lên? Và khi nào thì LLM thực sự giúp giảm thiểu công sức bảo trì?
Hướng dẫn từng bước
Chúng ta sẽ xây dựng lại cả hai cách tiếp cận từ đầu. Đầu tiên, chúng ta tạo hai tệp PDF mẫu chứa cùng một thông tin kinh doanh nhưng sử dụng các bố cục khác nhau. Sau đó, chúng ta trích xuất dữ liệu một lần bằng quy trình OCR và regex truyền thống, và một lần bằng quy trình OCR và LLM.
Cách tiếp cận truyền thống cơ bản đặt câu hỏi: “Tôi có thể tìm thấy chính xác mẫu mà tôi đã lập trình không?”
Cách tiếp cận dựa trên LLM lại hỏi: “Tôi có thể hiểu ý nghĩa của trường này trong ngữ cảnh không?”
Chuẩn bị môi trường
Trong hướng dẫn này, chúng ta sử dụng pip, trình quản lý gói tiêu chuẩn của Python. Bạn cần cài đặt và kích hoạt một môi trường ảo mới:
python -m venv b2bdocumentextractor
b2bdocumentextractor\Scripts\activate
Bước 1 – Cài đặt Tesseract
Tesseract là công cụ OCR (nhận dạng ký tự quang học) thực tế đọc văn bản từ hình ảnh hoặc PDF đã quét. pytesseract chỉ là cầu nối Python để giao tiếp với Tesseract.
Bạn cần tải xuống tệp .exe mới nhất cho w64 từ GitHub của Tesseract-UB Mannheim và chạy trình cài đặt. Hãy nhớ đường dẫn cài đặt (thường là C:\Program Files\Tesseract-OCR).
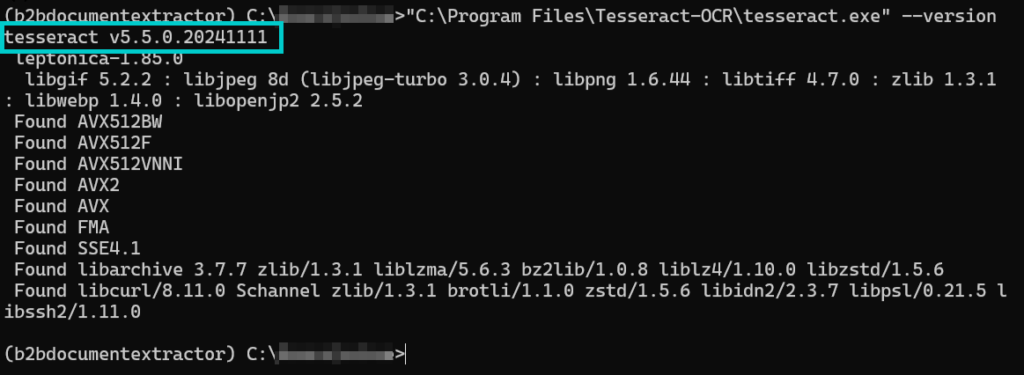 Cài đặt Tesseract
Cài đặt Tesseract
Sau khi cài đặt, hãy kiểm tra phiên bản trong terminal CMD để đảm bảo mọi thứ hoạt động đúng.
Bước 2 – Cài đặt Poppler
Tiếp theo, chúng ta cài đặt pdf2image – thư viện dùng để chuyển đổi PDF thành hình ảnh. Thư viện này yêu cầu Poppler chạy ở nền. Hãy tải phiên bản Poppler mới nhất, giải nén và di chuyển thư mục vào ổ C:. Bạn cũng cần thêm đường dẫn đến thư mục bin của Poppler vào biến môi trường PATH của Windows.
Bước 3 – Cài đặt các thư viện Python
Bây giờ chúng ta cài đặt các thư viện Python cần thiết. Hãy đảm bảo bạn đã kích hoạt môi trường ảo:
- pytesseract: Cầu nối giữa Python và Tesseract.
- pdf2image: Chuyển đổi trang PDF thành hình ảnh để Tesseract có thể phân tích.
- pillow: Thư viện xử lý hình ảnh nền tảng.
- fpdf2: Để tạo các tệp PDF thử nghiệm.
- ollama: Để cho phép script Python gửi tin nhắn đến LLM.
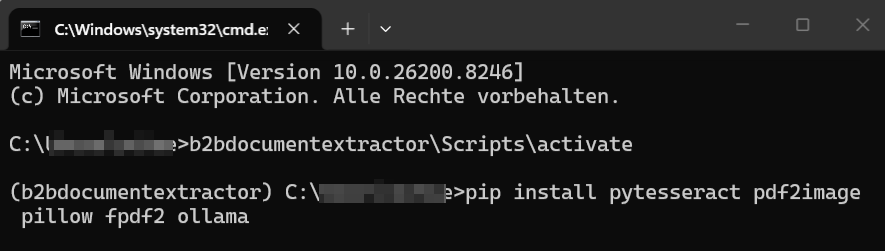 Cài đặt thư viện Python
Cài đặt thư viện Python
Bước 4 – Cài đặt Ollama và tải LLaMA 3
Ollama là công cụ cho phép chúng ta chạy các mô hình ngôn ngữ lớn (LLM) hoàn toàn miễn phí và cục bộ trên máy tính mà không cần khóa API.
Sau khi cài đặt Ollama, hãy tải LLaMA 3 bằng lệnh sau:
ollama pull llama3
Quá trình này sẽ tải xuống khoảng 4.7 GB dữ liệu. Sau khi hoàn tất, bạn có thể kiểm tra bằng lệnh ollama list.
 Tải LLaMA 3 với Ollama
Tải LLaMA 3 với Ollama
Bước 5 – Tạo thư mục dự án và tạo PDF thử nghiệm
Chúng ta sẽ tạo hai biểu mẫu đơn hàng B2B cho “Alpha GmbH” và “Beta AG” chứa thông tin giống nhau nhưng có bố cục khác nhau. Giả định rằng các đơn hàng này là bản quét, do đó chúng ta cần pdf2image.
Tạo một thư mục dự án và một file create_test_pdfs.py (mã nguồn có thể tìm thấy trong GitHub Gist của tác giả) để tự động tạo hai PDF này. Khi chạy script, bạn sẽ thấy hai tệp PDF với cùng thông tin nhưng tên trường và định dạng ngày tháng khác nhau hoàn toàn.
Cách tiếp cận 1: Cách truyền thống (pytesseract + Quy tắc Regex)
Cách tiếp cận truyền thống hoạt động theo hai bước:
- Chuyển đổi PDF thành hình ảnh.
- Sử dụng pytesseract để đọc hình ảnh và trích xuất văn bản thô qua OCR.
- Sử dụng regex để tìm kiếm các mẫu cụ thể trong văn bản.
Vấn đề phát sinh ngay ở bước thứ 3: Nếu khách hàng viết “Order Reference” thay vì “PO Number: ”, mẫu regex sẽ không tìm thấy gì. Bạn sẽ phải thêm một quy tắc mới.
Kết quả của Cách tiếp cận 1
Đối với Layout A, mọi thứ hoạt động hoàn hảo. Nhưng đối với Layout B? Không có trường nào được nhận dạng và tất cả các giá trị đều trả về “None”.
Đây chính là điểm yếu. Với mỗi khách hàng mới, các quy tắc regex mới phải được viết, kiểm tra và triển khai. Với 200 khách hàng, nghĩa là bạn cần 200 mẫu khác nhau. Và mỗi khi khách hàng thay đổi biểu mẫu của họ một chút, hệ thống sẽ lại bị lỗi.
Cách tiếp cận 2: Cách mới (pytesseract + Ollama + LLaMA 3)
Trong cách tiếp cận thứ hai, chúng ta giữ lại bước OCR nhưng thay thế các quy tắc regex cứng nhắc bằng một LLM.
Thay vì nói với mã “Tìm kiếm PO Number: ”, chúng ta yêu cầu LLM: “Đây là một tài liệu đơn hàng. Hãy trích xuất các trường này cho tôi, bất kể chúng được đặt tên là gì.”
LLM hiểu ngữ cảnh ngữ nghĩa. Nó nhận ra rằng “Order Reference” và “PO Number” có cùng ý nghĩa, ngay cả khi không có quy tắc rõ ràng.
Kết quả của Cách tiếp cận 2
Kết quả cho thấy cả hai bố cục đều được nhận dạng chính xác. Thông tin từ các trường có tên khác nhau được trích xuất và gán đúng, dù không có biểu thức regex nào được điều chỉnh. LLM hiểu cả hai bố cục vì nó đọc ngữ cảnh. Ngoài ra, định dạng ngày tháng từ Layout B cũng được chuẩn hóa để khớp với Layout A.
So sánh trực tiếp
Sau cả hai bài kiểm tra, rõ ràng là cả hai cách tiếp cận đều giải quyết được cùng một vấn đề, nhưng mỗi cái có ưu và nhược điểm riêng:
- Quy trình dựa trên Regex: Độ phức tạp nằm ở các quy tắc và công sức bảo trì. Phù hợp khi tài liệu ổn định.
- Quy trình dựa trên LLM: Độ phức tạp chuyển sang cơ sở hạ tầng, thời gian suy luận (inference time) và hành vi của mô hình. Phù hợp khi có nhiều bố cục khách hàng khác nhau.
Đối với các công ty quy mô vừa xử lý nhiều bố cục riêng biệt, sự đánh đổi này có thể trở nên quan trọng hơn về mặt chiến lược so với độ chính xác trích xuất thuần túy.
Khi nào chúng ta KHÔNG nên sử dụng LLM?
Hiện nay, cảm giác như mọi quy trình tự động hóa đều cần được thay thế bằng AI hoặc LLM. Tuy nhiên, trong thực tế, điều này không phải lúc nào cũng tốt hơn.
Dưới đây là một số tình huống mà cách tiếp cận truyền thống có thể vẫn phù hợp hơn:
- Tài liệu ổn định và chuẩn hóa: Nếu công ty chỉ xử lý một vài bố cục đã biết và hiếm khi thay đổi, regex thường là giải pháp tốt hơn vì lợi ích thêm của LLM trở nên nhỏ bé trong khi độ phức tạp của hệ thống tăng lên.
- Tốc độ và thông lượng là quan trọng: Trong ví dụ này, LLM xử lý một tài liệu trong 20–40 giây. Điều này có thể chấp nhận được cho quy mô nhỏ, nhưng nếu xử lý 10.000 tài liệu mỗi ngày, thời gian suy luận sẽ trở thành vấn đề hạ tầng thực sự. Các hệ thống dựa trên regex chạy nhanh hơn nhiều.
- Tính giải thích quan trọng hơn tính linh hoạt: Đặc biệt trong các ngành được kiểm soát như dược phẩm, bảo hiểm hoặc ngân hàng, việc hiểu rõ lý do một giá trị cụ thể được trích xuất là rất cần thiết. Quy tắc regex mang tính xác định, trong khi LLM hoạt động theo xác suất và khó kiểm toán hơn.
- Công ty không có cơ sở hạ tầng phù hợp: Việc chạy LLM yêu cầu nhiều RAM, CPU/GPU và cơ chế giám sát mà không phải doanh nghiệp nào cũng sẵn sàng.
Lời kết
Việc lựa chọn cách tiếp cận đúng không nhất thiết là một câu hỏi kỹ thuật, mà là một câu hỏi chiến lược.
Cách tiếp cận truyền thống cố gắng mô tả rõ ràng mọi tài liệu có thể có. Cách tiếp cận dựa trên LLM cố gắng hiểu ý nghĩa và ngữ cảnh. Đối với các môi trường nhỏ và ổn định, cách tiếp cận truyền thống thường là đủ. Càng nhiều bố cục và trường hợp ngoại lệ xuất hiện, việc duy trì các quy tắc càng trở nên khó khăn, và đó chính là lúc LLM bắt đầu trở nên thú vị.
Việc áp dụng LLM cho các tác vụ này cũng có thể là bước đệm tốt để một công ty làm quen với AI, từ đó chuẩn bị cho các ứng dụng phức tạp hơn trong tương lai.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026