
Xây dựng Pipeline "LLM-as-a-Judge": Tự động đánh giá chất lượng Mô hình Ngôn ngữ Lớn
Các benchmark công cộng không phản ánh hết nhu cầu thực tế của nhà phát triển. Bài viết giới thiệu một pipeline đánh giá LLM tùy chỉnh, sử dụng chính AI để chấm điểm output, giúp so sánh hiệu năng và chi phí giữa các model một cách khách quan.

Các chỉ số chuẩn (benchmarks) công cộng rất hữu ích, nhưng chúng không thực sự cho biết liệu một thay đổi nhỏ trong prompt hay việc chuyển sang một mô hình giá rẻ hơn có đủ tốt cho quy trình làm việc riêng của bạn hay không.
Vấn đề này thường xuyên xuất hiện trong thực tế, nên tôi đã quyết định xây dựng một quy trình đánh giá (pipeline) dựa trên tệp cấu hình: chạy các trường hợp thử nghiệm, kiểm tra định dạng lược đồ (schema), sử dụng một LLM riêng để đóng vai trò "người chấm điểm", và cuối cùng là tạo báo cáo so sánh chi tiết.
Cách hoạt động của Pipeline
Đây là một hệ thống pipeline gồm 3 giai đoạn chính:
- Inference (Suy luận): Chạy các test case của bạn chống lại các model ứng viên. Quá trình xác thực định dạng và schema sẽ tự động chạy trong bước này.
- Judge (Đánh giá): Một LLM riêng biệt sẽ chấm điểm các đầu ra dựa trên 9 chỉ số khác nhau bao gồm: độ chính xác, sự trung thành (faithfulness), độ hoàn thiện, v.v.
- Compare (So sánh): Tổng hợp các điểm số thành một báo cáo so sánh dưới dạng JSON và Markdown.
Những lựa chọn thiết kế chính
Hệ thống này được xây dựng với một số tính năng kỹ thuật quan trọng để đảm bảo tính công bằng và chính xác:
- Kiến trúc Judge 3 lớp: Định dạng, nội dung và cách diễn đạt được đánh giá trong các lệnh gọi LLM riêng biệt mà không chia sẻ ngữ cảnh. Điều này ngăn chặn các vấn đề về định dạng làm thiên lệch điểm số nội dung.
- Chế độ đánh giá linh hoạt: Hỗ trợ so sánh trực tiếp hai mô hình (pairwise), chấm điểm độc lập (absolute), hoặc kết hợp cả hai (hybrid).
- Tổng hợp theo đa số: Chạy quy trình đánh giá nhiều lần và lấy kết quả đa số để giảm nhiễu.
- Blinding (Che dấu): Các nhãn của ứng viên được ngẫu nhiên hóa để ngăn chặn thiên lệch về vị trí.
- Chế độ nhất quán: Nếu thiết lập
inference_repeats >= 2, pipeline sẽ tự động chuyển sang đo lường độ ổn định của đầu ra thay vì chất lượng.
Hỗ trợ đa nhà cung cấp
Công cụ này hỗ trợ nhiều nền tảng khác nhau bao gồm OpenAI, Azure OpenAI, Gemini (native REST) và bất kỳ endpoint nào tương thích với OpenAI (như LM Studio, vLLM, v.v.). Bạn có thể kết hợp linh hoạt, ví dụ: sử dụng GPT để chấm điểm (judge) trong khi các model ứng viên chạy cục bộ.
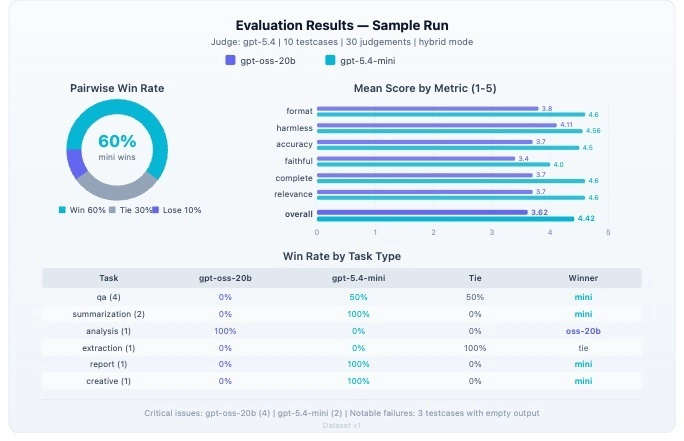 Kết quả đánh giá mẫu
Kết quả đánh giá mẫu
Đầu ra nhận được
Bạn sẽ nhận được một tệp comparison-report.json chứa tỷ lệ thắng, điểm số trung bình theo từng chỉ số, khoảng tin cậy và số lượng vấn đề nghiêm trọng. Ngoài ra, một báo cáo Markdown cũng được tạo ra để dễ đọc nhanh.
Bộ tiêu chí đánh giá (rubric) là một tệp Markdown độc lập với các mốc điểm (1/3/5), các rào cản thiên kiến và quy tắc vấn đề nghiêm trọng. Bạn có thể tùy chỉnh các tiêu chí đánh giá chỉ bằng cách chỉnh sửa tệp rubric này mà không cần thay đổi mã nguồn.
Những điều công cụ này KHÔNG phải là
- Không phải là bộ benchmark: Bạn phải tự mang đến các trường hợp thử nghiệm của mình.
- Không phải là công cụ huấn luyện mô hình: Nó đánh giá đầu ra, không phải các trọng số (weights).
- Không phải là khung tác nhân (agent framework): Đây là một pipeline đánh giá theo lô (batch evaluation).
Công nghệ sử dụng
Hệ thống yêu cầu Python >= 3.11, Pydantic và Typer CLI. Chỉ cần 3 lệnh để chạy: uv sync, cấu hình tệp .env, và uv run llm-judge run-all.
- Kho lưu trữ (Repo): archminor/llm-as-a-judge
Rất mong muốn nhận được ý kiến từ mọi người về cách xử lý đánh giá LLM trong môi trường sản xuất (production).
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026