
Xây dựng Trợ lý Email AI Riêng tư và Chạy Local: Từ Hộp thư đến Nhân vật ảo
Tác giả đã xây dựng "Llamail", một tác nhân AI email riêng tư chạy hoàn toàn trên máy tính cá nhân với khoảng 3700 dòng code Python. Hệ thống sử dụng mô hình Llama, giao diện Telegram và kết hợp tìm kiếm ngữ nghĩa để quản lý, tóm tắt email mà không gửi dữ liệu lên đám mây, đảm bảo tối đa quyền riêng tư và tiết kiệm chi phí API.
Tôi có hơn 18.000 email trong hộp thư cá nhân, và đó mới chỉ là một trong những tài khoản mà tôi sở hữu. Tôi muốn tìm kiếm chúng theo ngữ nghĩa, nhận được bản tóm tắt của AI, soạn thảo回复 và chạy các chiến dịch email — tất cả đều thực hiện ngay từ điện thoại. Tuy nhiên, tôi không muốn OpenAI hay Google AI đọc email của mình. Hay bất kỳ ai khác. Đối với tôi, AI cục bộ (local AI) là câu trả lời thực sự duy nhất cho việc xử lý dữ liệu riêng tư vì không ai có thể đọc hay huấn luyện mô hình của họ trên dữ liệu của bạn trong khi bạn đang trả tiền cho dịch vụ đó.
Vì vậy, tôi đã tự xây dựng cho mình một dự án trợ lý email riêng tư chạy cục bộ tên là Llamail. Nhân vật tổng hợp mặc định của nó là Sable. Nó giúp tôi tìm kiếm, tóm tắt và quản lý email, cũng có thể trò chuyện theo kiểu tán gẫu, roleplay để làm cho mọi thứ trở nên thú vị hơn. Khoảng 3.700 dòng code Python, một mô hình Llama chạy trên GPU laptop thông thường, và một bot Telegram làm giao diện — mọi thứ đều được viết thủ công, không phải do AI sinh ra (vibecoded). Dưới đây là cách thức hoạt động.
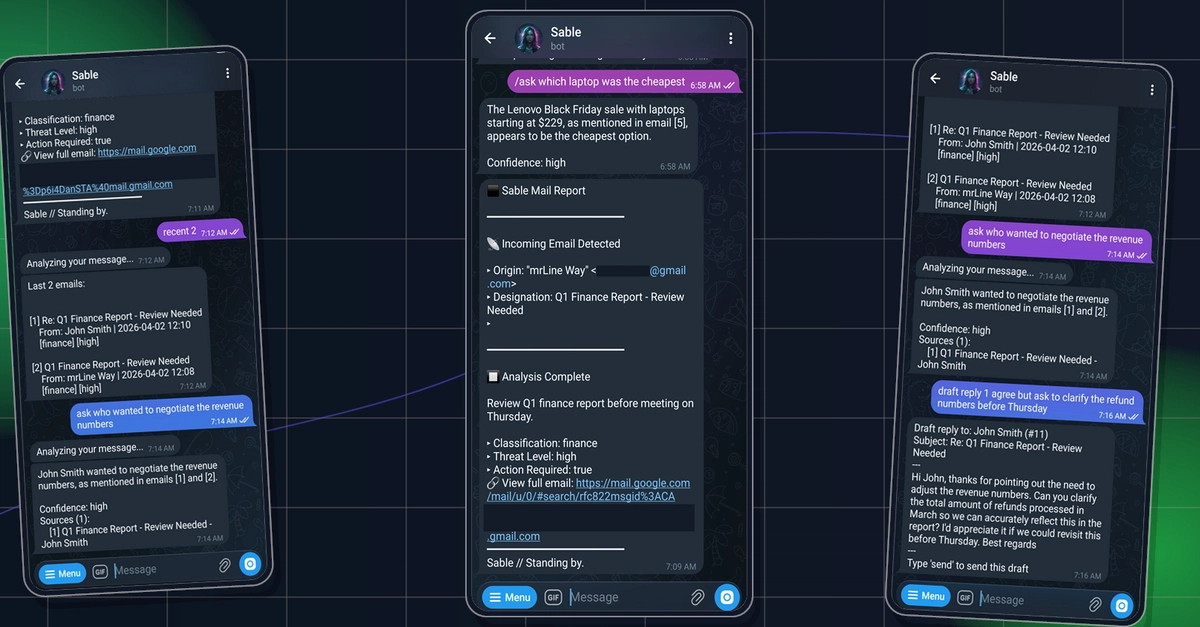
 Giao diện chào mừng của Sable
Gặp gỡ Sable — một trợ lý email riêng tư, chạy local với nhân vật tổng hợp có thể cấu hình.
Giao diện chào mừng của Sable
Gặp gỡ Sable — một trợ lý email riêng tư, chạy local với nhân vật tổng hợp có thể cấu hình.
Tại sao lại chọn Local?
Tôi hoàn toàn có thể sử dụng OpenAI hay Gemini hoặc bất kỳ API đám mây nào khác và xong việc trong một cuối tuần. Nhưng email mang tính cá nhân và chứa đựng hợp đồng, các cuộc thảo luận về lương, thông tin y tế, những cuộc trò chuyện với những người không đồng ý để lời nói của họ được xử lý bởi AI bên thứ ba, và tôi không cảm thấy thoải mái với điều đó.
Còn về khía cạnh thực tế: hơn 18.000 email đồng nghĩa với chi phí API thực sự. Với mức giá của GPT-5.4 tính đến ngày 5 tháng 4 năm 2026 ($2,50/1M input, $15/1M output tokens), chỉ riêng quá trình nhập ban đầu thôi cũng sẽ tốn khoảng 60–120 USD tùy thuộc vào độ dài email trung bình và kích thước tóm tắt — không phải là một khoản tiền phá sản, nhưng vẫn là chi phí trước mặt tăng lên theo kích thước của hộp thư. Sau đó còn có các truy vấn tìm kiếm, tạo bản nháp, và câu hỏi tiếp theo — nó cộng thêm rất nhanh. Một LLM cục bộ chỉ tốn tiền điện và sự kiên nhẫn, nhưng nó không tính phí bạn trên từng token. Và một cách trung thực, tôi chỉ thích chạy mọi thứ cục bộ. Sự độc lập khỏi một gói đăng ký có giới hạn khác chính là phần thưởng xứng đáng.
Vì vậy, ràng buộc là: mọi thứ chạy trên phần cứng của tôi, không có gì rời khỏi mạng của tôi ngoại trừ một ngoại lệ — Telegram. Đó là máy chủ bên thứ ba và về lý thuyết họ có thể đọc nó nếu thực sự muốn. Nhưng về mặt giấy tờ, không giống như các nhà cung cấp AI đám mây, việc xử lý dữ liệu của tôi không phải là sản phẩm của họ — họ là nền tảng nhắn tin, không phải đường ống huấn luyện mô hình. Hiện tại đó là sự đánh đổi mà tôi chấp nhận để có sự tiện lợi của giao diện di động hoạt động mọi nơi. Trong tương lai, tôi đang nghĩ về việc triển khai một lớp bộ chuyển đổi (adapter) để Telegram có thể được hoán đổi cho các giao diện khác như bot Matrix tự lưu trữ, giao diện web, hoặc thậm chí là một CLI đơn giản.
Trải nghiệm thực tế
Tôi kiểm soát mọi thứ từ Telegram. Dưới đây là một quy trình thực tế:
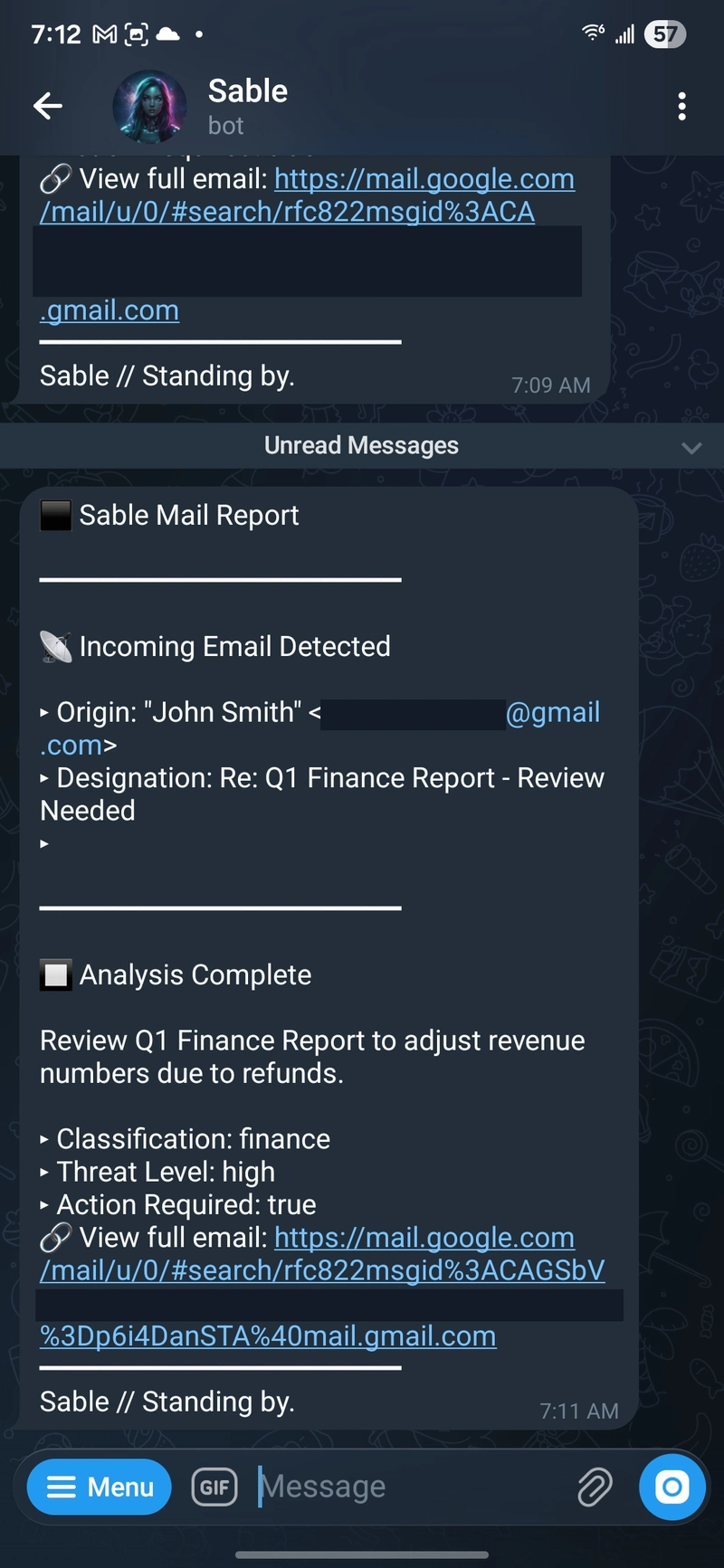 Xử lý email trực tiếp trên Telegram
Các email mới được tự động tóm tắt và đẩy thông báo tới Telegram.
Xử lý email trực tiếp trên Telegram
Các email mới được tự động tóm tắt và đẩy thông báo tới Telegram.
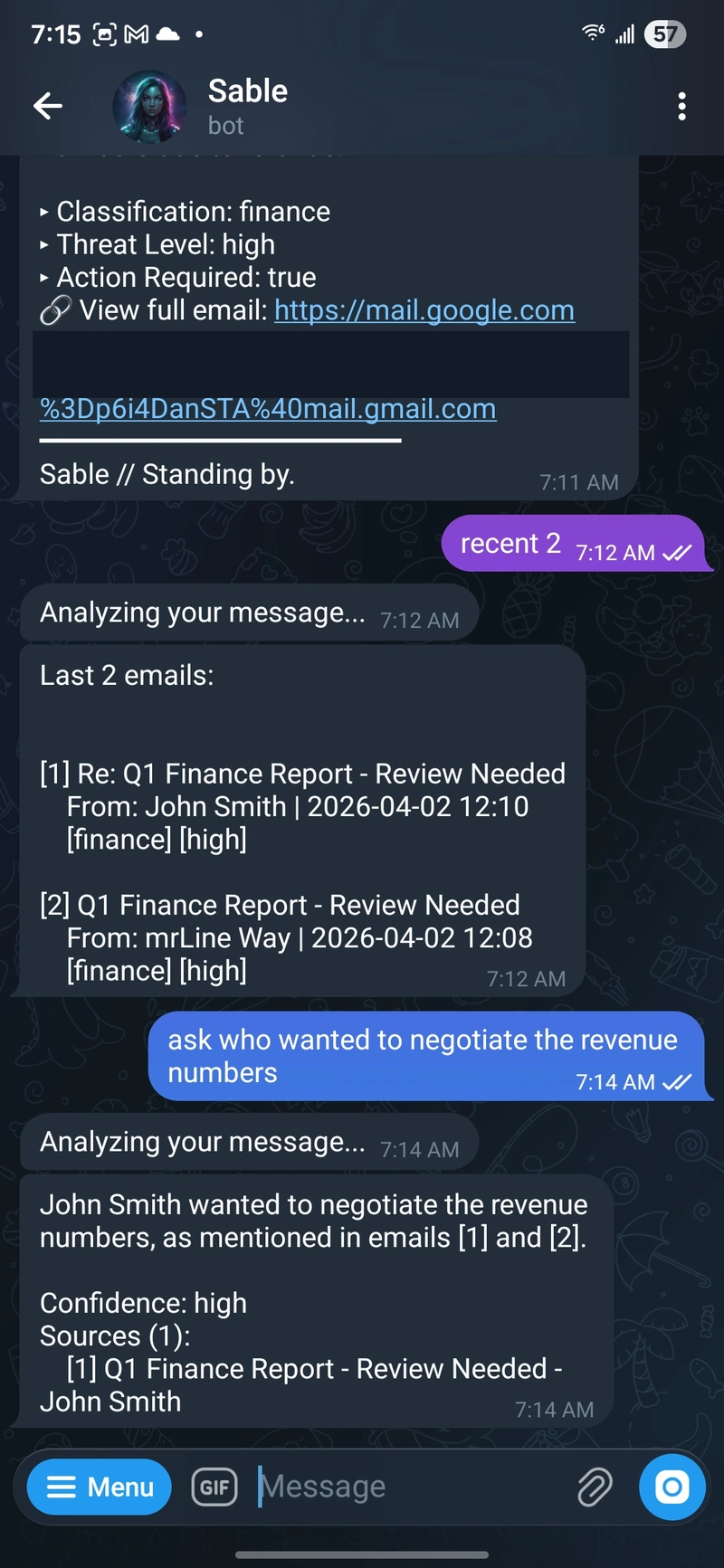 Tìm kiếm email và đặt câu hỏi
Tìm kiếm email và đặt câu hỏi theo dõi bằng công nghệ RAG.
Tìm kiếm email và đặt câu hỏi
Tìm kiếm email và đặt câu hỏi theo dõi bằng công nghệ RAG.
Tác nhân xử lý tìm kiếm và Q&A (với bộ nhớ theo dõi đơn giản), soạn thảo và gửi email (bao gồm cả gửi theo lịch), nhập hàng loạt từ Gmail, chặn người gửi và hủy đăng ký, kiểm tra ngữ pháp, và các chiến dịch email được cá nhân hóa bởi LLM với tính năng theo dõi trả lời.
Bạn có thể sử dụng các lệnh slash (ví dụ: /search budget), các lệnh trần (ví dụ: import status), hoặc chỉ cần trò chuyện tự nhiên với nó — "này, nhóm đã thảo luận điều gì tuần trước?" LLM sẽ đọc tin nhắn của bạn, chọn công cụ phù hợp từ hơn 30 hành động có sẵn, trích xuất các tham số từ ngữ cảnh (bao gồm cả việc tính toán "tuần trước" thành một ngày cụ thể), và thực thi lệnh. Giữa các nhiệm vụ, nó vẫn giữ nhân cách như một nhân vật có thể cấu hình — bạn có thể tán gẫu với nó, và nó nhớ lịch sử cuộc trò chuyện của bạn xuyên suốt các phiên. Tôi đã thiết kế cho nó một giọng nói tổng hợp lạnh lùng để nó cảm giác như một tác nhân thực thụ thay vì một trợ lý generik.
Kiến trúc hệ thống
Hệ thống có hai nửa hầu như không biết gì về nhau:
n8n (chạy trong Docker) hoạt động như một cầu nối thông điệp "ngu ngốc". Nó giám sát Gmail để tìm email mới và chuyển tiếp tin nhắn Telegram. Đó là tất cả. Quy trình lệnh Telegram theo nghĩa đen chỉ có ba nút: Trigger → HTTP Request → Send Message. Không có logic, không có nhánh, không có nút code. Chắc chắn tôi có thể bỏ qua n8n và xây dựng các dịch vụ Python cho Gmail và Telegram API, nhưng tôi quyết định tiết kiệm thời gian. Hơn nữa, n8n có thư viện kết nối tốt nên nếu tôi cần cắm Slack, Discord, hoặc dịch vụ khác, đó chỉ là thao tác kéo thả nút thay vì một tích hợp API mới.
Dịch vụ web Python (FastAPI) là bộ não. Mọi lệnh, mọi cuộc gọi LLM, mọi truy vấn cơ sở dữ liệu, mọi tương tác Gmail API đều diễn ra ở đây. Khi tôi cần thêm tính năng mới, tôi viết một hàm Python — không phải một nhánh quy trình làm việc.
Cả hai nửa giao tiếp qua HTTP. n8n sống trong Docker, dịch vụ web chạy trên máy chủ. host.docker.internal kết nối chúng.
Dưới đây là danh sách công nghệ đầy đủ:
| Thành phần | Công cụ | Tại sao |
|---|---|---|
| LLM | llama.cpp + Llama 3.1 8B (Q8_0) | Cục bộ, miễn phí, API tương thích OpenAI |
| Embeddings | llama.cpp + Nomic Embed v2 MoE (Q6_K) | Máy chủ riêng để không chặn LLM |
| Lớp API | FastAPI | Xác thực Pydantic, lifespan cho luồng nền |
| Lưu trữ | SQLite (WAL) + ChromaDB | Một tệp cho dữ liệu quan hệ, kho vector nhúng cho tìm kiếm ngữ nghĩa. FTS5 cho tìm kiếm từ khóa — không cần dịch vụ thêm |
| Điều phối | n8n (Docker) + Cloudflare Tunnel | Kích hoạt Gmail/Telegram. Tunnel cung cấp URL HTTPS miễn phí cho webhooks |
| Giao diện | Telegram Bot | Hoạt động từ điện thoại. Không cần terminal, không cần venv, không cần SSH |
Tôi phát triển trên Windows với một chiếc RTX 4080 Mobile (12GB VRAM, CUDA). Môi trường sản xuất chạy trên một mini-PC Linux Mint với Ryzen 7 8845HS (Vulkan). Cùng một codebase Python cho cả hai — llama.cpp xử lý sự khác biệt của backend GPU.
Toàn bộ client LLM chỉ dài 81 dòng. Không LangChain, không framework — chỉ là httpx.post() đến một endpoint tương thích OpenAI.
Mẫu thiết kế cốt lõi
Mọi tác vụ LLM trong hệ thống — từ tóm tắt, Q&A, phân loại ý định, soạn thảo, cá nhân hóa chiến dịch, phân loại phản hồi, kiểm tra ngữ pháp và cả những cuộc trò chuyện bình thường — đều tuân theo một khuôn mẫu chính xác:
Jinja2 template → llama.cpp → parse JSON
Có 11 template. Mỗi template là một hợp đồng: "đây là những gì tôi đưa cho bạn, đây là cấu trúc JSON tôi mong muốn trả lại." Tôi nhận thấy hệ thống template hoạt động hoàn hảo để thiết lập các giới hạn và kỳ vọng hành vi của LLM, đơn giản vì chúng là các tệp hướng dẫn được tách biệt hỗ trợ cú pháp biến inline và bạn giữ tất cả hướng dẫn của mình trong một không gian sạch sẽ, biệt lập.
Cùng một mẫu đó xử lý phân loại ý định (người dùng gõ "tìm email về ngân sách" → LLM trả về {"intent": "search", "params": {"query": "budget"}}), tạo bản nháp (hướng dẫn + email gốc → LLM trả về văn bản bản nháp), và mọi thứ khác. Cùng một hàm generate(), template khác.
Đây là quyết định tôi hài lòng nhất. Thêm một tính năng mới được hỗ trợ bởi LLM có nghĩa là viết một tệp Jinja2 và một hàm Python mỏng. Không có sự trừu tượng hóa mới, không có công việc ống nối phức tạp.
Bộ định tuyến lệnh 3 tầng
Đây là mẫu thú vị nhất trong codebase. Khi bạn gửi một tin nhắn, hệ thống sẽ thử ba chiến lược — từ nhanh đến chậm:
Tầng 1: Lệnh Slash. /search budget → tức thì. Hệ thống tách chuỗi bằng khoảng trắng, tìm kiếm lệnh và điều phối. Không có sự tham gia của LLM.
Tầng 2: Lệnh ghép trần. import status hoặc draft reply 1 sounds good (không có slash) → cũng tức thì. Những cái này an toàn để so khớp mà không cần LLM vì chúng luôn bắt đầu bằng một từ khóa đã biết (import, draft, campaign, schedule).
Tầng 3: Ngôn ngữ tự nhiên. "này, quá trình nhập của tôi thế nào rồi?" → tác nhân sẽ gửi cho bạn một thông báo "Đang phân tích tin nhắn của bạn..." (để bạn biết nó đang hoạt động), chuyển văn bản của bạn cho LLM với một template phân loại liệt kê hơn 30 ý định, nhận lại JSON có cấu trúc, và điều phối đến trình xử lý đúng.
Thay vì chuyển tất cả hướng dẫn trực tiếp vào một cuộc gọi LLM và hy vọng nó sẽ xử lý mọi thứ cùng lúc chính xác, tôi sử dụng sự tách biệt mối quan tâm (tất nhiên, SOLID tốt cũ): đầu tiên, tác nhân phân loại ý định của người dùng và chỉ có thế. Chỉ sau khi nó chọn chính xác hành động phù hợp — bao gồm cả việc liệu có cần xử lý LLM thêm hay không — nó mới chuyển dữ liệu ý định trở lại hệ thống, hệ thống sẽ thực hiện bước tiếp theo.
Điểm mấu chốt: LLM là phương án dự phòng (fallback), không phải đường dẫn chính. Các lệnh slash có độ trễ bằng không và là một cách thực sự tiện lợi cho những người biết rõ họ muốn gì và chỉ muốn nhận kết quả mà không cần lan man: command -> result -> done. Ngôn ngữ tự nhiên thêm khoảng ~4 giây — và chỉ khi không có cách nào khác để hiểu đầu vào. Bạn có được sự tiện lợi của trò chuyện tự do mà không phải trả chi phí độ trễ trên mỗi tin nhắn.
Những lỗi đã gặp
Dưới đây là các lỗi mà tôi đã dành nhiều thời gian nhất để sửa. Nếu bạn đang xây dựng cái gì đó tương tự, hy vọng điều này giúp bạn tiết kiệm được vài giờ.
1.628 lần nhập thất bại do một lỗi. Tôi đang nhập 18.000 email, và 1.628 email liên tục thất bại với lỗi ràng buộc khóa ngoại. Nguyên nhân: Tôi đang lưu các đoạn email trước khi hàng email cha tồn tại. Cách sửa chỉ là di chuyển một cuộc gọi hàm lên trên một cuộc gọi khác. Bài học thì kém thú vị hơn — tôi nên có các bài kiểm tra tích hợp (integration tests) ngay từ đầu. Không, tôi vẫn chưa có chúng, và vâng, tôi biết tôi có thể nhờ Codex hay Claude tự tạo ra một số, nhưng điều đó sẽ phá vỡ tinh thần thủ công của dự án. Nếu bạn trung thực, hãy trung thực cho đến cùng.
Gmail IDs nói dối. Gmail API trả về các ID hex như 19c54cb15118c128. Giao diện web Gmail sử dụng các ID hoàn toàn khác như QgrcJHrtw.... Tôi đã dành cả một chiều cố gắng tạo liên kết "Xem trong Gmail". Hóa ra không có sự chuyển đổi nào giữa hai định dạng này. Không có API, không có công thức, không tài liệu. Cuối cùng tôi đã sử dụng các liên kết tìm kiếm rfc822msgid: — header RFC822 Message-ID có trong mọi email, và tìm kiếm Gmail có thể tìm thấy theo nó. Nó mở một tìm kiếm với một kết quả thay vì một liên kết trực tiếp, nhưng nó hoạt động. Hầu như vậy.
Google OAuth và dấu gạch chéo ở cuối. http://localhost:9090 và http://localhost:9090/ là các URI chuyển hướng khác nhau đối với Google. Một cái hoạt động. Một cái báo lỗi redirect_uri_mismatch. Tôi đã thử cái sai trước và mất 10 phút đọc các chủ đề trên Stack Overflow về cấu hình sai ID client trước khi nhận ra dấu gạch chéo.
Telegram nuốt dấu ngoặc nhọn. Tôi có "Usage: import history <account_email>" trong một phản hồi. Trình phân tích cú pháp HTML của Telegram đã cố gắng hiểu <account_email> như một thẻ HTML, không tìm thấy thẻ đóng, và âm thầm xóa toàn bộ tin nhắn. Điều này xảy ra hai lần — một lần với văn bản tĩnh, một lần với nội dung email chứa <[email protected]>. Cách sửa thực sự là html.escape() ở cấp độ route để tôi không bao giờ phải bận tâm về nó nữa.
Thông số thực tế
| Hoạt động | Thời gian |
|---|---|
| Xử lý một email (tóm tắt) | ~2-3.5 giây |
| Xử lý một email (embedding) | < 0.1 giây |
| Tốc độ nhập hàng loạt | ~5 email/phút |
| Tìm kiếm kết hợp (ngữ nghĩa + từ khóa) | ~3 giây |
| RAG Q&A (tìm kiếm + tạo câu trả lời) | ~7 giây |
| Phân loại ý định ngôn ngữ tự nhiên | ~4 giây |
| Lệnh Slash | Tức thì |
Tất cả số liệu được đo trên dữ liệu thực — tốc độ nhập hàng loạt từ dấu thời gian công việc SQLite, thời gian gọi LLM từ nhật ký máy chủ llama.cpp, mọi thứ khác bằng đồng hồ bấm giờ và một cuộc trò chuyện Telegram.
Phần cứng: RTX 4080 Mobile (12GB VRAM), 32GB RAM. Mô hình 8B ở lượng tử hóa Q8_0 sử dụng khoảng 9GB VRAM. Bạn có thể chạy Q4 trên thẻ 6GB, nhưng chất lượng phản hồi giảm đáng kể đối với đầu ra JSON có cấu trúc.
Thử ngay
Mã nguồn: github.com/sviat-barbutsa/llamail
Bạn sẽ cần:
- GPU với 8GB+ VRAM (NVIDIA với CUDA, hoặc bất kỳ thẻ nào hỗ trợ Vulkan)
- 16GB+ RAM
- Docker cho n8n
- Tài khoản Gmail và một bot Telegram (cả hai đều miễn phí)
Kho lưu trữ có hướng dẫn thiết lập hướng dẫn bạn qua mọi thứ.
Trong bài viết tiếp theo, tôi sẽ đi sâu vào hệ thống tìm kiếm kết hợp — cách kết hợp tìm kiếm ngữ nghĩa ChromaDB với tìm kiếm từ khóa SQLite FTS5 tạo ra kết quả tốt hơn là chỉ dùng một mình, và tại sao nó chỉ mất 120 dòng code để xây dựng.
Nếu bạn đang xây dựng cái gì đó với LLM cục bộ, tôi rất muốn nghe về nó trong phần bình luận. Và nếu bạn đã giải quyết vấn đề ID Gmail một cách thanh lịch hơn tôi, hãy cho tôi biết nhé.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026