
Xử lý Node.js Cluster Một Cách An Toàn: Tắt Nhóm Graceful, Khắc Phục Vấn Đề Windows và Kiểm Thử Black-Box
Bài viết chia sẻ kinh nghiệm xử lý module cluster trong Node.js khi xây dựng Torus Proxy, tập trung vào cách nhận diện lỗi, tắt nhóm đúng cách và xử lý khác biệt tín hiệu trên Windows, đồng thời giới thiệu cách kiểm thử tích hợp black-box thực tế.
Xử lý Node.js Cluster Một Cách An Toàn: Tắt Nhóm Graceful, Khắc Phục Vấn Đề Windows và Kiểm Thử Black-Box
Node.js vốn chạy đơn luồng, vì vậy mô-đun cluster được xem là giải pháp tiêu chuẩn để tận dụng đa lõi CPU bằng cách tạo nhiều tiến trình con chia sẻ cùng một cổng server. Khi xây dựng Torus, một reverse proxy bằng Node.js, tác giả đã áp dụng cluster nhưng phát hiện ra một lỗ hổng tiềm ẩn nguy hiểm trong cách quản lý vòng đời worker, ảnh hưởng nghiêm trọng đến quá trình triển khai không gián đoạn (zero-downtime deployment).
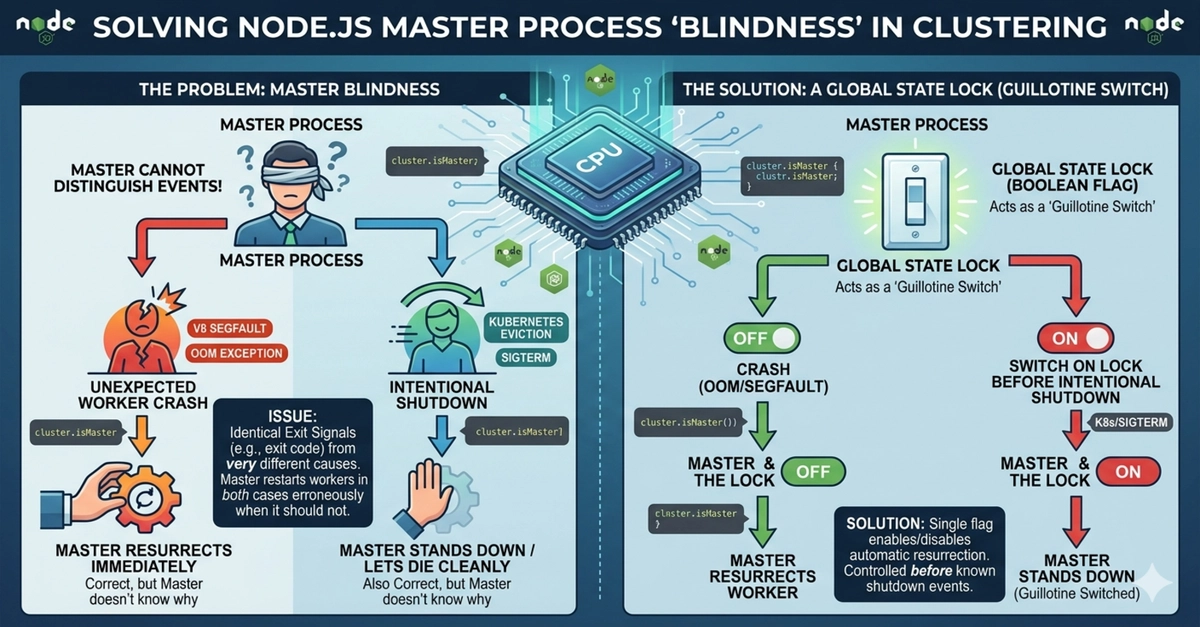
Cái bẫy của việc “tự động hồi sinh mù quáng”
Cách sử dụng phổ biến là lắng nghe sự kiện exit của worker, khi worker chết sẽ tự động khởi tạo lại worker mới:
cluster.on('exit', (worker, code, signal) => {
logger.warn(`Worker ${worker.process.pid} died. Booting a replacement...`);
cluster.fork();
});
Điều này cho phép tự phục hồi khi worker bị lỗi bất ngờ, như thiếu bộ nhớ hay crash V8 engine. Tuy nhiên, đoạn code này hoàn toàn "mù" nguyên nhân và chỉ nhìn thấy worker chết là khởi tạo lại ngay.
Khi chạy trong môi trường Kubernetes, kịch bản này lại trở thành thảm họa: Kubernetes gửi tín hiệu SIGTERM để dần đóng pod, các worker bắt đầu thoát và đóng kết nối TCP sạch. Tuy nhiên, ngay khi worker đầu tiên thoát, master lại khởi tạo worker thay thế ngay lập tức. Kết quả là master liên tục tạo worker mới trong khi Kubernetes muốn thu hồi pods, gây ra cuộc "chiến" giữa quá trình rollout và master. Kubernetes phải cuối cùng dùng SIGKILL để ép dừng hoàn toàn, gây mất kết nối cho client đang hoạt động.
Giải pháp: Quản lý trạng thái tắt nhóm có điều kiện
Để xử lý, cần phân biệt rõ 2 trường hợp xảy ra:
- Crash bất ngờ: Worker chết do lỗi, nên khởi tạo lại ngay.
- Shutdown có chủ đích: Như khi Kubernetes yêu cầu tắt, cho phép worker thoát sạch rồi mới đóng master.
Để làm được điều này, ứng dụng cần:
- Khóa trạng thái toàn cầu (
isShuttingDown) để biết khi nào đang trong quy trình tắt nhóm. - Broadcast IPC gửi lệnh tắt cho toàn bộ worker.
- Lifecycle manager trong worker chịu trách nhiệm sửa soạn đóng kết nối, có timeout chặt chẽ tránh treo vô thời hạn.
Ví dụ đoạn xử lý sự kiện exit trong master:
let isShuttingDown = false;
cluster.on("exit", (worker, code, signal) => {
if (isShuttingDown) {
logger.info(`Worker ${worker.process.pid} exited cleanly during shutdown.`);
if (Object.keys(cluster.workers || {}).length === 0) {
logger.info("All workers stopped. Master exiting with code 0.");
process.exit(0);
}
} else {
logger.warn(`Worker ${worker.process.pid} crashed. Forking a replacement...`);
cluster.fork();
}
});
Khi nhận SIGTERM hoặc SIGINT, master sẽ bật cờ isShuttingDown và gửi lệnh tắt cho toàn bộ worker qua IPC:
const initiateClusterTeardown = (signal) => {
if (isShuttingDown) return;
isShuttingDown = true;
logger.info({ signal }, "Master received termination signal. Broadcasting shutdown to workers...");
for (const id in cluster.workers) {
cluster.workers[id]?.send({ type: "SHUTDOWN" });
}
};
process.on("SIGTERM", () => initiateClusterTeardown("SIGTERM"));
process.on("SIGINT", () => initiateClusterTeardown("SIGINT"));
Worker khi nhận lệnh SHUTDOWN sẽ thực hiện các bước:
- Từ chối kết nối TCP mới ngay lập tức.
- Đóng các kết nối giữ chân (idle Keep-Alive) để quản lý tài nguyên.
- Đợi cho các stream/tác vụ đang chạy hoàn thành tự nhiên với timeout 10 giây để tránh treo mãi.
Sau timeout, worker buộc thoát dù còn kết nối đang mở, đảm bảo deployment không bị đình trệ.
Thử nghiệm thực tế: Vì sao Jest không đủ
Jest chỉ chạy trong một quá trình Node.js duy nhất nên không thể kiểm thử được các cluster đa tiến trình thực sự (gọi cluster.fork() hoặc process.exit() trong test sẽ làm hỏng runner hoặc tạo tiến trình con bỏ hoang).
Tác giả chuyển sang xây dựng kiểm thử tích hợp black-box:
- Khởi động toàn cluster dưới dạng tiến trình con dùng
child_process.spawnvới kênh IPC. - Bắt đầu bằng cách theo dõi kết quả stdout từ proxy.
- Giết một worker bằng tín hiệu không thể chặn (SIGKILL) mô phỏng crash chết thật sự.
- Theo dõi master tự hồi sinh worker mới.
- Gửi lệnh tắt qua IPC (không phải tín hiệu OS) để kiểm tra luồng shutdown graceful.
Vấn đề đặc thù trên Windows: POSIX signal không tồn tại
Tín hiệu POSIX như SIGINT, SIGTERM chỉ hoạt động đúng trên Linux hoặc macOS. Trên Windows:
- Gọi
process.kill(pid, 'SIGINT')không kích hoạt handler mà trực tiếp ép dừng tiến trình. - Master không chạy được lifecycle manager, không kịp thoát mượt.
Tác giả phải tạo một "cánh cửa hậu" riêng qua IPC để gửi lệnh shutdown trên Windows, ví dụ:
process.on("message", (msg) => {
if (msg && msg.type === "TEST_SHUTDOWN") {
initiateClusterTeardown("TEST_SHUTDOWN");
}
});
Thử nghiệm chuyển đổi từ gọi kill OS sang gửi JSON qua IPC thành công, giúp cross-platform chạy chính xác.
Bẫy trong môi trường CI/CD: Thiếu tài nguyên và biến môi trường
Ban đầu pipeline trên GitHub Actions thất bại do:
- Thiếu các file chứng chỉ TLS (được gitignore).
- Thiếu file
.envchứa biến môi trường quan trọng như JWT_SECRET.
Giải pháp trong pipeline:
- Tạo chứng chỉ dummy tự ký trước khi chạy test.
- Inject biến môi trường bí mật giả trực tiếp vào
spawnthay vì rely vào file.env.
Sau khi bổ sung, pipeline chạy thành công, đánh dấu green check.
Kết luận: Đừng tin tưởng mù quáng vào mô hình cluster mặc định
Sử dụng cluster trong Node.js cần cẩn trọng:
- Cần có state machine xác định rõ nguyên nhân chết của worker.
- Đảm bảo tuần tự và đồng bộ trong quá trình tắt nhóm và tái tạo worker để tránh đối đầu với orchestrator.
- Hiểu rõ sự khác biệt nền tảng hệ điều hành, đặc biệt Windows không hỗ trợ đầy đủ POSIX signal.
- Ưu tiên tạo kiểm thử tích hợp black-box thay vì đơn vị unit test giả lập thiếu thực tế.
- Đảm bảo môi trường CI/CD tương đồng với môi trường production về files, config.
Mô-đun cluster rất mạnh, nhưng cách dùng standard đôi khi tạo cảm giác bền bỉ chứ không phải thực sự bền bỉ.
Bạn đọc có thể tham khảo mã nguồn Torus Proxy trên GitHub để hiểu chi tiết hơn.
Bài viết cung cấp góc nhìn sâu sắc giúp các lập trình viên Node.js xây dựng các hệ thống cluster ổn định, dễ bảo trì và phù hợp với môi trường triển khai chuyên nghiệp hiện nay.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026