
10 Sai Lầm Phổ Biến Khi Triển Khai Hệ Thống RAG Trong Môi Trường Production
Bài viết phân tích 10 sai lầm kinh điển trong việc xây dựng hệ thống RAG (Retrieval-Augmented Generation) ở quy mô doanh nghiệp, từ việc xử lý tài liệu sai cách đến phụ thuộc quá mức vào vector database. Tác giả đề xuất giải pháp kiến trúc bốn tầng để khắc phục các vấn đề về chi phí, độ chính xác và khả năng kiểm tra.

Trong môi trường doanh nghiệp, nhu cầu xử lý tài liệu không đơn thuần là tải một file PDF lên ChatGPT và hỏi một câu hỏi. Một nhân viên xử lý bồi thường có thể cần chạy cùng một câu hỏi qua toàn bộ danh mục hồ sơ của một môi giới, hoặc đội tuân thủ cần quét mọi hợp đồng trong một danh mục đầu tư. Ở quy mô đó, cách làm "nhồi dữ liệu vào ChatGPT" sẽ ngừng hoạt động và trở nên đắt đỏ một cách nhanh chóng.
Dưới đây là tổng hợp 10 sai lầm phổ biến mà chúng tôi thường xuyên gặp thấy trong các hệ thống RAG đang vận hành, cùng với cách khắc phục dựa trên kiến trúc bốn tầng (four-brick architecture).
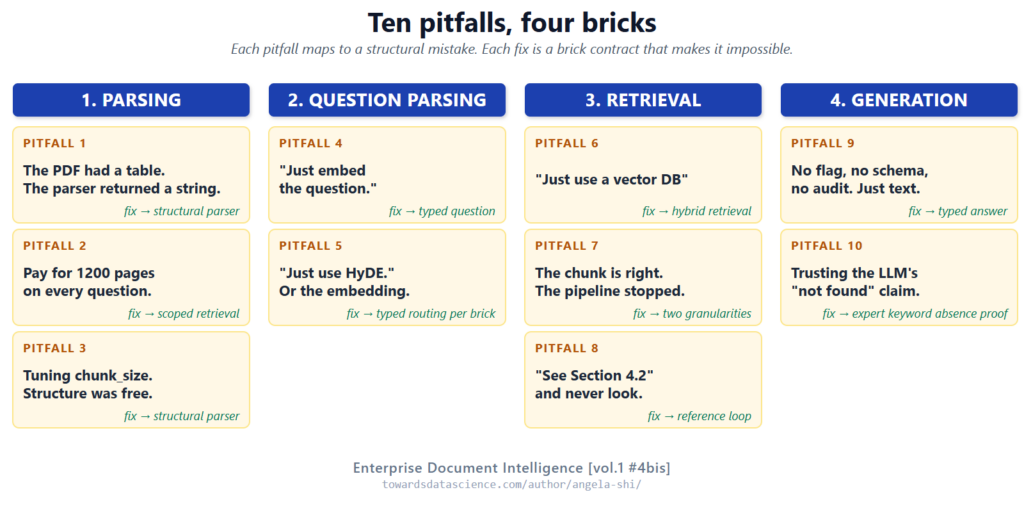 Tổng quan 10 sai lầm và kiến trúc giải pháp
Tổng quan 10 sai lầm và kiến trúc giải pháp
1. Phân tích cú pháp (Parsing): Khi tài liệu mất đi hình dạng gốc
Sai lầm lớn nhất bắt đầu từ việc coi tài liệu là một chuỗi văn bản thuần túy thay vì một đối tượng có cấu trúc.
Sai lầm 1: Biến bảng biểu thành chuỗi ký tự
Phản xạ mặc định của nhiều người là trích xuất PDF thành một khối văn bản duy nhất và để LLM tự xử lý. Vấn đề nảy sinh khi tài liệu chứa các bảng có nhãn hàng nhóm. Ví dụ, một bảng hợp đồng có cùng tên hàng "Premium" (Phí bảo hiểm) dưới hai mục "Health" (Sức khỏe) và "Dental" (Nha khoa). Khi bị làm phẳng thành văn bản, các danh mục này biến mất trong dòng token. Khi hỏi "Phí bảo hiểm của Kế hoạch B là bao nhiêu?", mô hình sẽ thấy hai câu trả lời hợp lệ nhưng không có dấu hiệu nhóm nào để phân biệt, dẫn đến việc đoán mò.
Giải pháp là sử dụng trình phân tích quan hệ (relational parser) tạo ra các bảng có kiểu dữ liệu (line_df, page_df, toc_df...) thay vì một chuỗi phẳng.
Sai lầm 2: Trả tiền cho 1200 trang cho mỗi câu hỏi
Một sai lầm khác là bỏ qua phân tích và nhồi toàn bộ PDF vào prompt. Với một tài liệu 12 trang thì ổn, nhưng với 1200 trang và 200 câu hỏi mỗi ngày, chi phí sẽ tăng vọt từ vài xu lên hàng nghìn đô la mỗi tháng.
 So sánh chi phí giữa phương pháp nhồi dữ liệu và pipeline có định hướng
So sánh chi phí giữa phương pháp nhồi dữ liệu và pipeline có định hướng
Trong một kịch bản thực tế với hợp đồng tái bảo hiểm 1200 trang, phương pháp nhồi toàn bộ tốn khoảng 131.000 USD mỗi năm, so với chỉ 330 USD cho một pipeline truy xuất có định hướng (scoped pipeline). Prompt caching có thể giảm chi phí nhưng không thay đổi bản chất của vấn đề.
Sai lầm 3: Điều chỉnh chunk_size khi PDF đã có cấu trúc
Nhiều đội ngũ dành hàng tháng để tinh chỉnh chunk_size và chunk_overlap, nhưng thực tế họ đang cố gắng khắc phục hậu quả của việc mất cấu trúc ngay từ đầu. Một hợp đồng 200 trang có mục lục (TOC), tiêu đề với kích thước phông chữ khác nhau và bảng biểu được lưu dưới dạng hộp giới hạn (bounding box). Hàm extract_text() mặc định thường bỏ qua các thông tin này và trả về một dòng văn bản vô hồn.
 Chunking cố định cắt ngang bảng so với chunking nhận biết cấu trúc
Chunking cố định cắt ngang bảng so với chunking nhận biết cấu trúc
Giải pháp là sử dụng trình phân tích cấu trúc giữ nguyên kiểu dáng phông chữ, lưới bảng và TOC. Các khối (chunk) sau đó sẽ dựa trên ranh giới phần, không phải cửa sổ ký tự cố định.
2. Phân tích câu hỏi: Bỏ qua người dùng
Sai lầm 4: "Chỉ cần nhúng câu hỏi (embed) thôi"
Cách đơn giản nhất là lấy câu hỏi của người dùng, nhúng nó và gửi đi truy xuất. Tuy nhiên, câu hỏi mang nhiều thông tin: phạm vi, hình dạng câu trả lời mong đợi, định dạng, điều kiện, hoặc phủ định. Việc nhúng làm phẳng tất cả这些 thành một vector, làm mất các ràng buộc quan trọng. Ví dụ, câu hỏi "Những gì KHÔNG được bảo hiểm bởi chính sách này?" có thể trả về các đoạn về những ĐƯỢC bảo hiểm vì từ "không" thường bị bỏ qua trong vector.
Giải pháp là một đối tượng ParsedQuestion có kiểu dữ liệu rõ ràng, mang theo tất cả các ràng buộc và phạm vi.
Sai lầm 5: "Chỉ dùng HyDE" hoặc tin tưởng vào nhúng
Nhiều người dùng HyDE (Hypothetical Document Embeddings) để tránh trích xuất từ khóa thủ công. Mặc dù hiệu quả trên các benchmark, HyDE thực chất là trích xuất từ khóa do LLM điều khiển nhưng không có xác minh của chuyên gia. Nó thêm một bước tạo sinh mỗi truy vấn mà không có tính kiểm toán.
Giải pháp vẫn là trình phân tích câu hỏi tạo ra các trường riêng biệt cho hình dạng câu trả lời, phạm vi và định dạng, định tuyến chúng đến các khối xử lý phù hợp.
3. Truy xuất (Retrieval): Phản xạ Vector DB và điểm mù
Sai lầm 6: "Chỉ dùng Vector Database"
Đây là sai lầm lớn nhất và tốn kém nhất để sửa đổi. Mô hình mặc định là: chia nhỏ tài liệu, nhúng, và trả về top-k theo độ tương đồng cosine. Vấn đề là cosine không tốt với các từ khóa chính xác, mã sản phẩm, số liệu, hoặc các tham chiếu pháp lý cụ thể. Embeddings làm mất tính rời rạc của các thuật ngữ này.
Giải pháp là truy xuất kết hợp (hybrid retrieval): bộ phát hiện từ khóa (deterministic) chạy song song với bộ phát hiện nhúng, có một trọng tài LLM xếp hạng các ứng viên tổng hợp.
Sai lầm 7: Chunk đúng nhưng Pipeline dừng ở đó
Pipeline truy xuất một chunk và đưa cho LLM, nhưng không biết chính xác dòng nào trong chunk chứa câu trả lời. Điều này phá vỡ các tính năng như làm nổi bật văn bản gốc hoặc trích dẫn dòng số. Hơn nữa, lượng văn bản xung quanh cần thiết phụ thuộc vào câu hỏi (ví dụ: chỉ cần 2 dòng cho một ngày tháng, nhưng cần cả đoạn cho chính sách hủy bỏ).
Giải pháp là truy xuất ở hai cấp độ hạt (granularities) cùng lúc: một cấp độ chính xác để làm nổi bật (dòng cụ thể) và một cấp độ phù hợp với nhu cầu câu hỏi.
Sai lầm 8: "Xem Mục 4.2" và không tra cứu thêm
Khi tài liệu tham chiếu nội bộ như "các loại trừ được liệt kê trong Mục 4.2", pipeline thường dừng lại ở đoạn chứa câu tham chiếu đó. LLM sau đó hoặc bịa ra nội dung của Mục 4.2, hoặc từ chối trả lời.
Giải pháp là vòng lặp giải quyết tham chiếu: lần chạy đầu tiên đánh dấu tham chiếu đang chờ xử lý, bộ điều phối tìm đến mục được trích dẫn, chạy truy xuất trên các trang đúng và lần chạy thứ hai trả về câu trả lời dựa trên chính mục đó.
4. Tạo sinh (Generation): Nơi chuỗi kiểm toán bị đứt gãy
Sai lầm 9: Không có cờ, không có schema, không có kiểm toán
Nhiều hệ thống RAG vận hành chỉ trả về một chuỗi văn bản thô từ LLM. Bạn không có tín hiệu nào để biết câu trả lời có đáng tin hay không. Mô hình trả về câu trôi chảy dù đoạn văn có chứa câu trả lời hay không.
Giải pháp là schema câu trả lời có kiểu dữ liệu (typed answer schema) kết hợp với bộ xác minh (verifier) thực hiện các kiểm tra chương trình như regex hoặc kiểm tra độ phủ tập hợp để đảm bảo tính chính xác trước khi gửi cho người dùng.
Sai lầm 10: "Không tìm thấy trong các chunk" không có nghĩa là "Không tìm thấy trong kho dữ liệu"
Khi LLM nói "not found", thực chất nó có nghĩa là "không tìm thấy trong các đoạn văn bản này", không phải là không có trong toàn bộ tài liệu. Điều này dẫn đến việc từ chối sai lệch khi truy xuất bị bỏ sót.
Giải pháp là sao cho khẳng định "không tìm thấy" phải đi kèm với bằng chứng vắng mặt xác định. Từ điển từ khóa của chuyên gia sẽ được chạy tìm kiếm chuỗi con trên toàn bộ kho dữ liệu. Nếu không có kết quả nào, hệ thống mới có thể tự tin nói rằng thông tin không tồn tại.
Kết luận
Mỗi sai lầm nêu trên đều là một lựa chọn cấu trúc được đưa ra sớm trong quá trình phát triển. Để khắc phục, chúng ta cần một kiến trúc bốn tầng chặt chẽ: trình phân tích quan hệ giữ cấu trúc tài liệu, câu hỏi có kiểu dữ liệu mang theo mọi ràng buộc, truy xuất kết hợp ở hai cấp độ hạt, và câu trả lời có kiểu dữ liệu được kết nối với các kiểm tra chương trình. Đây là chìa khóa để xây dựng hệ thống RAG doanh nghiệp hiệu quả và tiết kiệm chi phí.
Bài viết liên quan
Phần mềm
BootProof: "Nút chạy" trung thực cho các kho mã nguồn, ưu tiên bằng chứng thay vì cảm tính
11 tháng 6, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026

Phần mềm
Shii haa: Ứng dụng biến micro điện thoại thành cảm biến phát hiện nhịp thở
02 tháng 6, 2026