
AI có thể giải thích được? Mô hình Neuro-Symbolic giúp phát hiện lừa đảo nhanh hơn 33 lần
Các công cụ SHAP hiện tại tốn khoảng 30ms để giải thích dự đoán, không ổn định và phụ thuộc vào dữ liệu nền. Bài viết này giới thiệu mô hình Neuro-symbolic tạo ra giải thích xác định ngay trong quá trình tính toán chỉ trong 0.9ms, tăng tốc độ 33 lần mà không làm giảm đáng kể độ chính xác phát hiện lừa đảo.

AI có thể giải thích được? Mô hình Neuro-Symbolic giúp phát hiện lừa đảo nhanh hơn 33 lần
Trong phát hiện lừa đảo tín dụng, khả năng giải thích dự đoán của mô hình AI là yếu tố sống còn. Tuy nhiên, các phương pháp hiện tại như SHAP thường gặp rào cản lớn về độ trễ và tính ngẫu nhiên khi chạy trong môi trường sản xuất thực tế.
Bài viết dưới đây sẽ phân tích một mô hình AI kết hợp giữa Học sâu và Quy tắc ký hiệu (Neuro-symbolic) nhằm giải quyết vấn đề này, mang lại tốc độ giải thích nhanh hơn 33 lần mà vẫn giữ nguyên độ chính xác trong việc bắt lừa đảo.
Vấn đề với SHAP trong môi trường thời gian thực
Khi tôi đang gỡ lỗi hệ thống phát hiện lừa đảo vào một đêm, tôi muốn hiểu tại sao mô hình lại đánh dấu một giao dịch cụ thể là gian lận. Tôi đã gọi KernelExplainer (một công cụ phổ biến trong khung SHAP) và chờ đợi. Ba giây sau, tôi nhận được biểu đồ chỉ số thuộc tính của tính năng. Khi chạy lại để kiểm tra giá trị, tôi nhận được những con số khác nhau.
Điều này cho thấy một giới hạn cấu trúc: mô hình đưa ra quyết định nhất quán, nhưng phương pháp giải thích lại không. Nếu phải chạy theo thời gian thực, độ trễ và tính ngẫu nhiên này là không thể chấp nhận được.
SHAP (Shapley Additive exPlanations) tính toán các giá trị Shapley để gán đầu ra của mô hình cho các tính năng đầu vào. KernelExplainer là biến thể không phụ thuộc mô hình, sử dụng hồi quy tuyến tính có trọng số để xấp xỉ các giá trị này dựa trên một tập dữ liệu nền. Mặc dù hữu ích cho gỡ lỗi, nhưng khi phải giải thích từng dự đoán riêng lẻ trong thời gian thực, nó gặp phải các hạn chế lớn:
- Phụ thuộc vào dữ liệu nền phải được duy trì và truyền tại thời gian suy luận.
- Kết quả thay đổi tùy thuộc vào ngẫu nhiên và số lượng mẫu.
- Tốn khoảng 30ms cho mỗi mẫu ở cấu hình giảm thiểu.
Giải pháp: Mô hình Nhân - Ký hiệu
Ý tưởng cốt lõi ở đây là "Khả năng giải thích" không nên là bước xử lý sau (post-processing). Nó nên là một phần của kiến trúc mô hình.
Mô hình Neuro-symbolic tôi xây dựng bao gồm ba thành phần hoạt động cùng nhau: xương sống học sâu, lớp quy tắc ký hiệu và lớp hợp nhất.
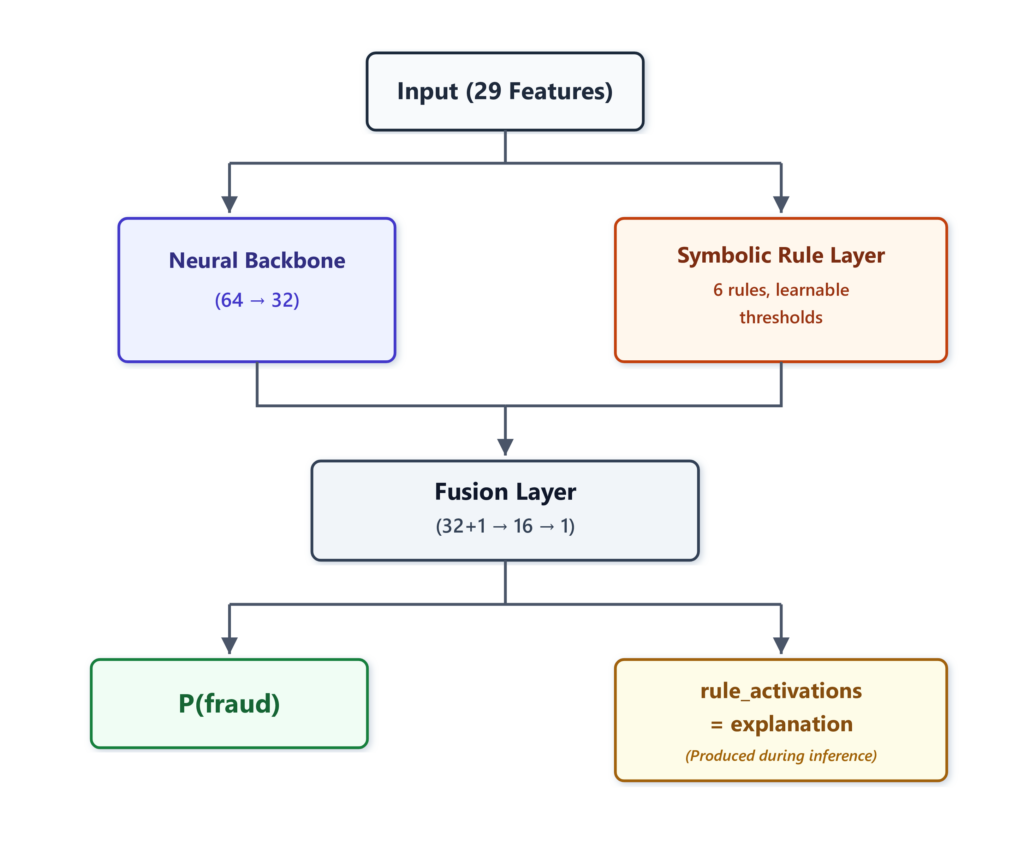 Kiến trúc mô hình Neuro-Symbolic Fraud Detector
Kiến trúc mô hình Neuro-Symbolic Fraud Detector
Mô hình này chạy hai luồng song song trong mỗi quá trình tính toán. Xương sống học sâu sản xuất các đại diện ẩn về gian lận. Lớp quy tắc ký hiệu đánh giá sáu quy tắc khác biệt hóa với các ngưỡng học được. Lớp hợp nhất kết hợp hai tín hiệu này thành xác suất lừa đảo duy nhất. Các hoạt động của quy tắc - giải thích - là một đầu ra tự nhiên của quá trình tính toán này, không phải là một bước riêng biệt.
Các quy tắc ký hiệu
Sáu quy tắc này được neo vào các tính năng có tín hiệu gian lận mạnh nhất trong dữ liệu thẻ tín dụng (V14, V17, V12, V10, V4, và Amount). Mỗi ngưỡng là một tham số học được, được khởi tạo dựa trên kiến thức miền và cập nhật trong quá trình đào tạo.
- HIGH_AMOUNT: Số tiền vượt ngưỡng.
- LOW_V17, LOW_V14, LOW_V12: Các thành phần V dưới ngưỡng (V14 là tín hiệu mạnh nhất).
- HIGH_V10_NEG: V10 âm mạnh.
- LOW_V4: V4 dưới ngưỡng.
Điều thú vị là mô hình đã tự học được vị trí của các đường phân chia này thông qua descent gradient, thay vì chỉ dựa vào kiến thức thủ công.
Hiệu suất và Tốc độ
Tôi đã chạy cả hai phương pháp giải thích trên 100 mẫu kiểm thử. Các phép đo độ trễ được thực hiện trên CPU (Intel i7, PyTorch, không có GPU).
- SHAP (KernelExplainer): Tốn tổng cộng 3.00 giây, tức là 30.0 ms cho mỗi dự đoán.
- Neuro-symbolic: Tốn tổng cộng 0.0898 giây, tức là 0.898 ms cho mỗi dự đoán.
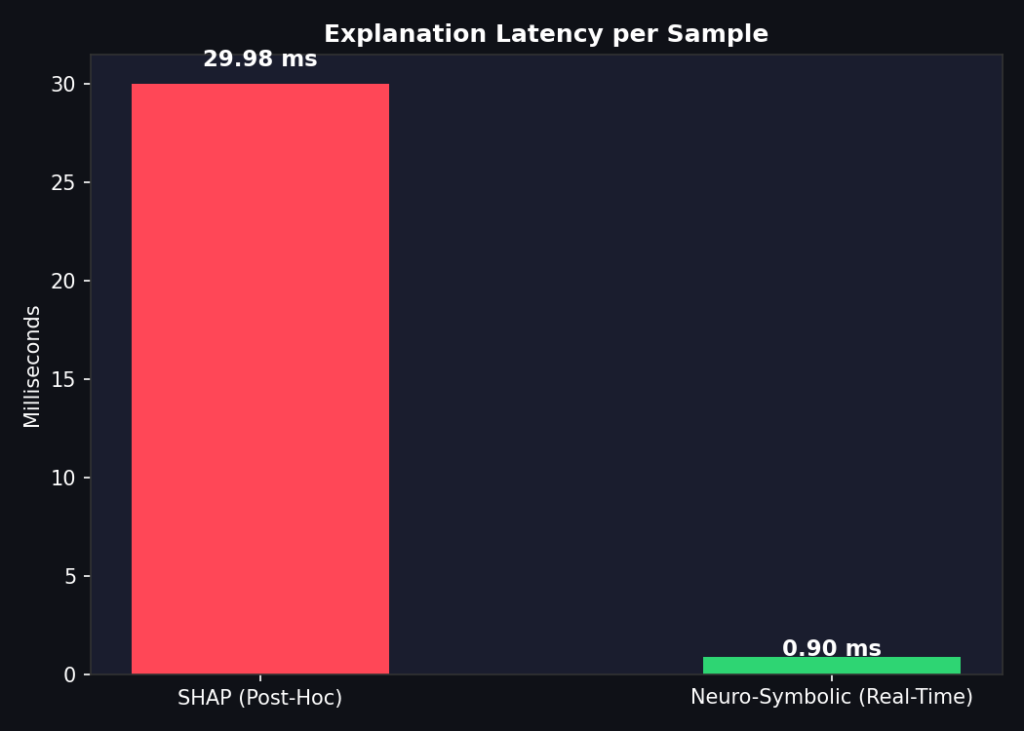 So sánh độ trễ giải thích giữa SHAP và mô hình Neuro-Symbolic
So sánh độ trễ giải thích giữa SHAP và mô hình Neuro-Symbolic
Đây là mức tăng tốc 33 lần. Hơn thế nữa, mô hình Neuro-symbolic không cần dữ liệu nền và không cần gọi hàm giải thích riêng biệt, giúp giảm đáng kể chi phí độ trễ.
Tính xác định (Deterministic)
Một điểm quan trọng khác là tính nhất quán. SHAP sử dụng Monte Carlo sampling, nên chạy lại cùng một đầu vào sẽ cho ra các số khác nhau. Trong môi trường kiểm toán, điều này là rủi ro. Ngược lại, mô hình Neuro-symbolic tạo ra cùng một giải thích cho cùng một đầu vào vì các hoạt động quy tắc là hàm xác định của các tính năng đầu vào và trọng số đã học.
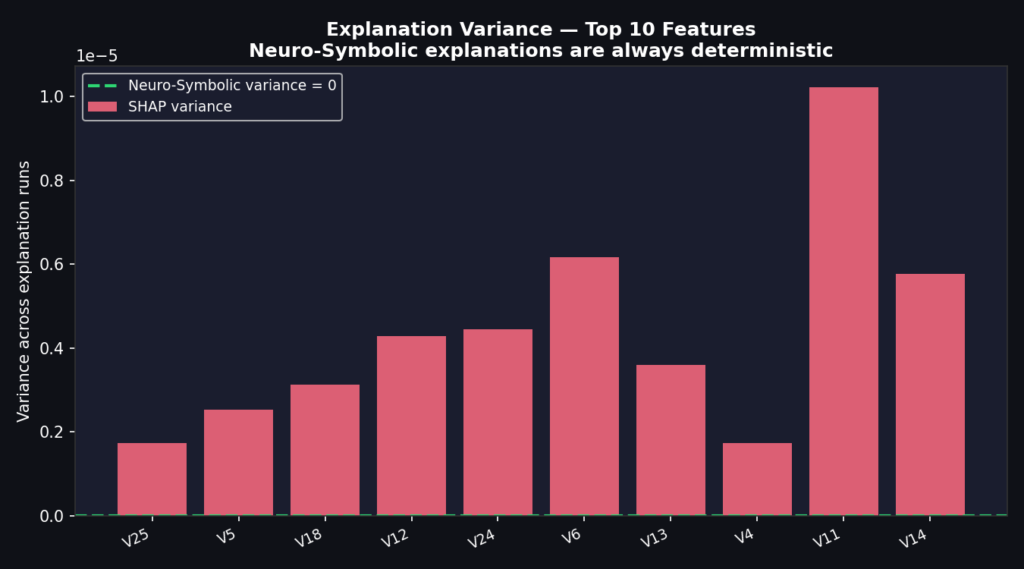 Biến thiên giải thích: Mô hình Neuro-Symbolic có giá trị bằng 0, trong khi SHAP dao động
Biến thiên giải thích: Mô hình Neuro-Symbolic có giá trị bằng 0, trong khi SHAP dao động
Kết quả trên tập dữ liệu thực tế
Tôi đã sử dụng tập dữ liệu Credit Card Fraud Detection từ Kaggle, bao gồm 284.807 giao dịch thực tế.
- Mô hình NN (Baseline): Recall (độ gọi lại) trên gian lận là 0.8469, AUC là 0.9737.
- Mô hình Neuro-symbolic: Recall là 0.8469 (giống hệt), AUC là 0.9688 (giảm nhẹ).
Điểm mấu chốt là độ gọi lại (recall) là giống nhau, nghĩa là mô hình bắt được cùng tỷ lệ gian lận như mô hình đen tối (black-box) truyền thống. Sự khác biệt nhỏ trong độ chính xác (precision) và AUC là chấp nhận được để đổi lấy khả năng giải thích tức thời và nhất quán.
Ví dụ về giải thích thực tế
Dưới đây là đầu ra từ mô hình cho một giao dịch gian lận được xác nhận (Transaction 840):
Dự đoán: GIAN LẬN Độ tin cậy: 100.0% Quy tắc kích hoạt (4) — được tạo ra trong quá trình tính toán:
- LOW_V17: -0.553 < -0.135 (trọng số 0.081)
- LOW_V14: -0.582 < -0.440 (trọng số 0.071)
- LOW_V12: -0.350 < -0.300 (trọng số 0.078)
- HIGH_V10_NEG: -0.446 < -0.320 (trọng số 0.078)
Điều này cho thấy mô hình không chỉ dự đoán "có gian lận hay không", mà còn giải thích tại sao dự đoán đó đúng thông qua các quy tắc cụ thể, tất cả trong một lượt tính toán duy nhất.
Lưu ý và Hướng phát triển
Mô hình đã học được ngưỡng cho V14, V17, V12 và V10 khớp với phân tích dữ liệu gốc, chứng tỏ khả năng học hỏi của nó. Tuy nhiên, có một vấn đề là trọng số của quy tắc LOW_V4 chiếm tới 57% tổng trọng số, làm cho lớp quy tắc có xu hướng hoạt động như một cổng một tính năng đơn lẻ.
Để khắc phục điều này, có thể cần thêm một thành phần điều chỉnh trọng số (regularization term) trong quá trình đào tạo để ngăn chặn sự tập trung trọng số quá mức.
Kết luận
SHAP vẫn là công cụ tốt cho việc gỡ lỗi và phân tích sau đó. Tuy nhiên, khi giải thích cần là một phần của quyết định (được ghi lại theo thời gian thực, có thể kiểm toán được), kiến trúc phải thay đổi. Các phương pháp hậu xử lý quá chậm và không ổn định.
Mô hình Neuro-symbolic đánh đổi một chút độ chính xác để đổi lấy giải thích xác định, tức thời và không thể tách rời khỏi dự đoán chính nó. Đây là một hướng đi thú vị cho các hệ thống phát hiện gian lận thời gian thực.
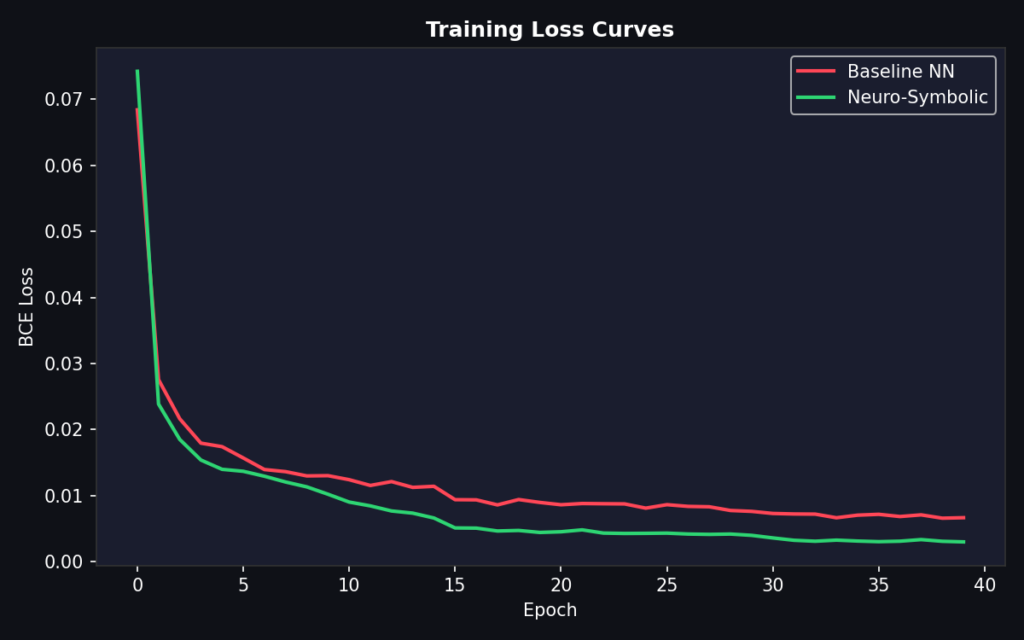 Biểu đồ độ trễ và các chỉ số hiệu suất chính
Biểu đồ độ trễ và các chỉ số hiệu suất chính
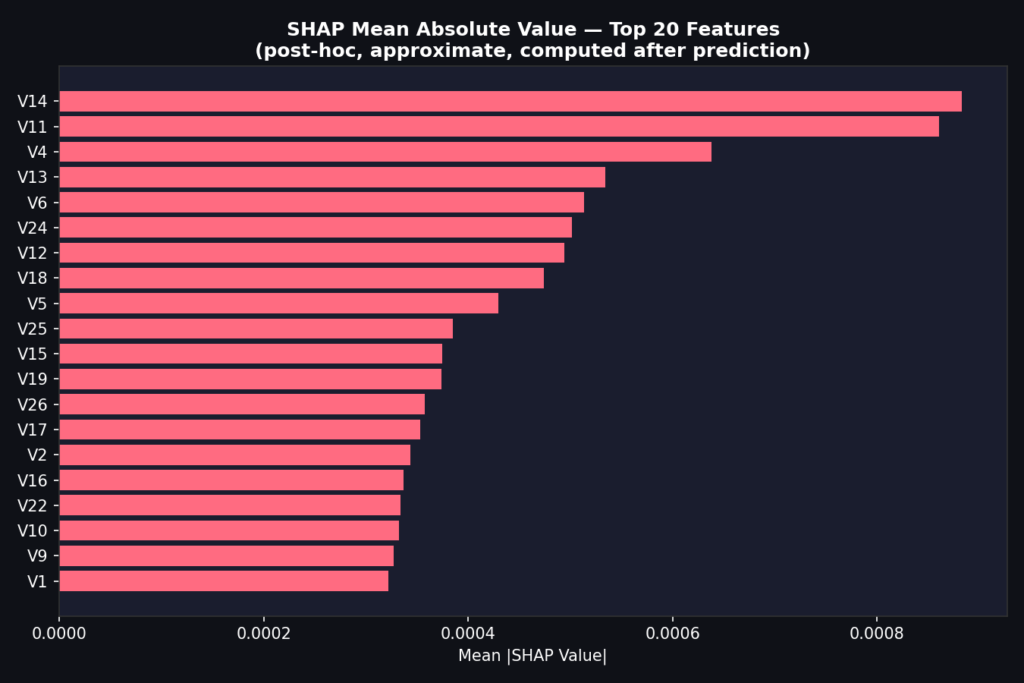 Biểu đồ tầm quan trọng tính năng toàn cầu tính bằng Shapley
Biểu đồ tầm quan trọng tính năng toàn cầu tính bằng Shapley
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026