
AI có thể viết code thay bạn không? Nghiên cứu mới về khả năng lập trình của ChatGPT
Một nghiên cứu mới đánh giá khả năng viết code thống kê của ChatGPT-4.0 Pro trên Python, R và Stata cho thấy mô hình này hoạt động hiệu quả hơn với Python và R. Bài viết cũng phân tích cách các mô hình ngôn ngữ lớn (LLM) đang thay đổi quy trình làm việc của các nhà nghiên cứu định lượng và tầm quan trọng của việc kiểm chứng kết quả.

Câu hỏi thực sự hiện nay không còn là liệu AI có thể viết code hay không, mà là liệu chúng ta có thể tin tưởng vào đoạn code mà nó tạo ra hay không.
Trong vài năm qua, ChatGPT và các mô hình ngôn ngữ lớn (LLM) khác đã trở thành công cụ quen thuộc trong công việc hàng ngày của sinh viên, chuyên gia phân tích và nhà khoa học dữ liệu. Nhiều người trong chúng ta đã sử dụng AI để tạo các hàm Python, sửa lỗi, tự động hóa tác vụ lặp lại hoặc dịch code giữa các ngôn ngữ lập trình.
Tuy nhiên, có một sự khác biệt lớn giữa việc yêu cầu ChatGPT viết một hàm hỗ trợ đơn giản và việc yêu cầu nó triển khai một phương pháp kinh tế lượng phức tạp. Liệu ChatGPT có thể viết chính xác mô hình Difference-in-Differences (Diff-in-Diff)? Liệu nó có thể triển khai Trọng số hóa xác suất nghịch đảo (IPTW) hay Phân tích hồi quy đứt gãy (RD) không chỉ bằng Python mà còn bằng R và Stata?
 Nghiên cứu về khả năng viết code của AI
Nghiên cứu về khả năng viết code của AI
Nghiên cứu mới về khả năng lập trình của ChatGPT
Bài viết "Can AI write your code? A case study of ChatGPT’s statistical coding capabilities for quantitative research" của Winberg và cộng sự, được công bố trực tuyến vào ngày 22 tháng 1 năm 2026 trên tạp chí Health Economics Review, đã thu hút sự chú ý đặc biệt. Các tác giả đã đánh giá khả năng của ChatGPT-4.0 Pro trong việc tạo code cho các tác vụ suy luận nhân quả (causal inference) trên ba ngôn ngữ: Python, R và Stata, sử dụng các giải pháp chuẩn từ cuốn sách Causal Inference: The Mixtape của Scott Cunningham.
Hầu hết các bài viết trước đây tập trung vào các tác vụ lập trình đơn giản như tự động hóa nhỏ, thống kê mô tả hoặc làm sạch dữ liệu. Nghiên cứu này đi xa hơn bằng cách đặt câu hỏi liệu ChatGPT có thể hỗ trợ nghiên cứu định lượng trong các bối cảnh đòi hỏi khắt khe hơn, nơi code không chỉ mang tính kỹ thuật mà còn mang tính phương pháp luận.
Phương pháp nghiên cứu
Các tác giả tập trung vào ba phương pháp suy luận nhân quả phổ biến:
- Difference-in-Differences (Diff-in-Diff)
- Inverse Probability Treatment Weighting (IPTW)
- Regression Discontinuity (RD)
Nghiên cứu sử dụng dữ liệu và bộ bài tập công khai từ Causal Inference: The Mixtape. Môi trường tham chiếu bao gồm R 3.6.0, Stata 18 và Python 3.13. Quy trình nghiên cứu bao gồm ba bước chính:
- Đưa ra yêu cầu (Prompting): Cung cấp cho ChatGPT các bài tập kinh tế lượng và yêu cầu tạo code. Ví dụ, một bài tập yêu cầu ước tính tác động của việc hợp pháp hóa nạo phá thai ở năm bang của Mỹ trước khi Roe v. Wade (1973) đối với tỷ lệ mắc bệnh lậu ở nữ giới 15-19 tuổi.
- Yêu cầu quy trình làm việc hoàn chỉnh: Không chỉ dừng lại ở một lệnh mô hình, các yêu cầu còn bao gồm quản lý dữ liệu, phân tích kinh tế lượng và tạo biểu đồ.
- Chạy code và so sánh kết quả: Code được tạo ra sẽ được thực thi trong môi trường tương ứng và kết quả được so sánh với đầu ra chuẩn từ The Mixtape.
Một điểm thú vị là việc nghiên cứu bao gồm cả Stata. Trong khi nhiều cuộc thảo luận về trợ lý lập trình AI tập trung vào Python và R, thì Stata vẫn được sử dụng rộng rãi trong kinh tế học và chính sách công.
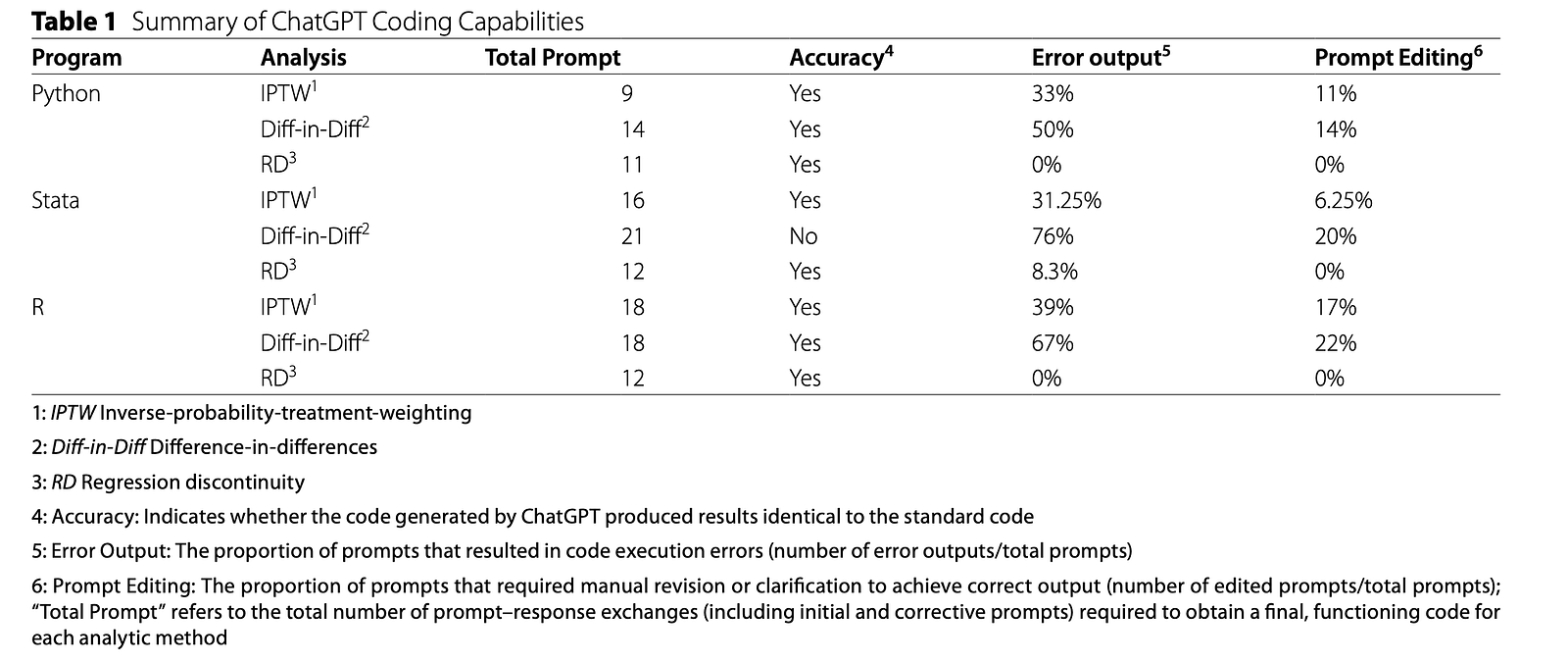
Kết quả: Python và R vượt trội hơn Stata
Kết luận tổng thể là khá cân bằng. ChatGPT hoạt động tốt hơn trong Python và R so với Stata. Các tác giả nhận thấy rằng ChatGPT tạo ra code và kết quả chính xác trong R và Python cho hầu hết các nhiệm vụ, trong khi Stata kém tin cậy hơn.
Kết quả này không quá ngạc nhiên. Python và R được sử dụng rộng rãi trong khoa học dữ liệu và thống kê, với cộng đồng trực tuyến lớn và nhiều ví dụ code công khai. Vì các mô hình ngôn ngữ lớn học từ dữ liệu văn bản và code quy mô lớn, nên việc chúng hoạt động tốt hơn với các ngôn ngữ có nhiều ví dụ công khai là điều dễ hiểu.
Năm chỉ số hiệu quả chính được đánh giá bao gồm: độ chính xác, hiệu quả, lỗi thực thi, nhu cầu chỉnh sửa và tính nhất quán. Trong đó, độ chính xác được đo bằng cách so sánh kết quả của code do ChatGPT viết với kết quả chuẩn.
AI đang thay đổi cách làm việc của các lập trình viên
LLMs thay đổi cách làm việc như thế nào?
Sự trỗi dậy của các mô hình ngôn ngữ lớn đã thay đổi đáng kể quy trình làm việc của nhiều người, bao gồm cả tôi. Trước đây, việc tổng quan tài liệu và tìm kiếm phương pháp phù hợp tốn rất nhiều thời gian. Ngày nay, ChatGPT giúp cấu trúc giai đoạn nghiên cứu ban đầu nhanh hơn nhiều.
Một thay đổi rõ rệt khác là sự dịch chuyển sang Python. Trước đây, chúng tôi chủ yếu sử dụng SAS để trích xuất dữ liệu và R để mô hình hóa. Tuy nhiên, với sự hỗ trợ của AI, chúng tôi dần chuyển một phần lớn công việc sang Python vì các công cụ như ChatGPT thường đưa ra câu trả lời tốt hơn, ít lỗi hơn và có nhiều ví dụ tái sử dụng hơn cho ngôn ngữ này.
AI cũng giúp tăng tốc đáng kể việc thu thập dữ liệu bên ngoài. Các tác vụ từng mất vài tuần để tìm nguồn, hiểu cấu trúc file và làm sạch dữ liệu giờ đây có thể được thực hiện nhanh chóng với các đoạn script do AI tạo ra.
Kết luận: Trợ lý nhanh, nhưng giám sát con người là bắt buộc
Trong công việc của tôi, tôi coi các LLM là những trợ lý nghiên cứu siêu tốc chứ không phải là các chuyên gia tự chủ. Chúng có thể làm trong vài giờ những việc mà trước đây cần vài ngày. Nhưng tốc độ này đi kèm với một điều kiện: sự giám sát và xác thực của con người vẫn là yếu tố then chốt.
Rủi ro "ảo giác" (hallucination) của AI là có thật. Một ví dụ điển hình là EY Canada đã phải rút lại một nghiên cứu sau khi phát hiện nó chứa dữ liệu bịa đặt và trích dẫn sai nguồn. Đó là lý do tại sao nghiên cứu của Winberg và cộng sự lại quan trọng đến vậy. Nó không chỉ hỏi liệu ChatGPT có thể viết code hay không, mà còn đặt ra câu hỏi quan trọng hơn: Trong điều kiện nào chúng ta có thể tin tưởng vào code do AI tạo ra?
Câu trả lời rõ ràng là: Chúng ta có thể sử dụng LLM để làm việc nhanh hơn, nhưng không thể loại bỏ trách nhiệm của nhà nghiên cứu. Nhà nghiên cứu vẫn cần kiểm tra các giả định, xác thực dữ liệu, kiểm tra code và đảm bảo sự diễn giải là chính xác. AI đang thay đổi sâu sắc cách chúng ta làm việc, nhưng nó không làm giảm đi nhu cầu về chuyên môn. Ngược lại, nó còn làm cho chuyên môn trở nên quan trọng hơn bao giờ hết.
Bài viết liên quan

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Phần mềm
Linear Cosine Palettes: Tạo bảng màu cho nghệ thuật thuật toán với hàm Cosine
05 tháng 6, 2026

Công nghệ
CEO Palantir: 10% thế giới "ghét chúng tôi một cách chuyên nghiệp"
05 tháng 5, 2026