
Azure Layout vs PyMuPDF: Giải pháp phân tích PDF "chuyên nghiệp" cho hệ thống RAG doanh nghiệp
Bài viết so sánh khả năng phân tích tài liệu PDF giữa thư viện PyMuPDF và dịch vụ Azure Layout trong bối cảnh xây dựng hệ thống RAG doanh nghiệp. Trong khi PyMuPDF nhanh và miễn phí nhưng gặp hạn chế với bảng tính, hình ảnh quét và chú thích, Azure Layout cung cấp khả năng trích xuất cấu trúc bảng và OCR toàn diện hơn, đổi lại là chi phí và độ trễ cao hơn.
Trong series Enterprise Document Intelligence, chúng ta đang từng bước xây dựng một hệ thống RAG (Retrieval-Augmented Generation) cấp doanh nghiệp từ những viên gạch cơ bản. Bài viết trước đã sử dụng PyMuPDF (fitz) để phân tích tài liệu. Tuy nhiên, fitz dù nhanh và miễn phí nhưng vẫn có những "điểm mù" khiến hệ thống RAG hoạt động không hiệu quả. Bài viết này sẽ khám phá cách Azure Layout (mô hình prebuilt-layout) lấp đầy những khoảng trống đó.
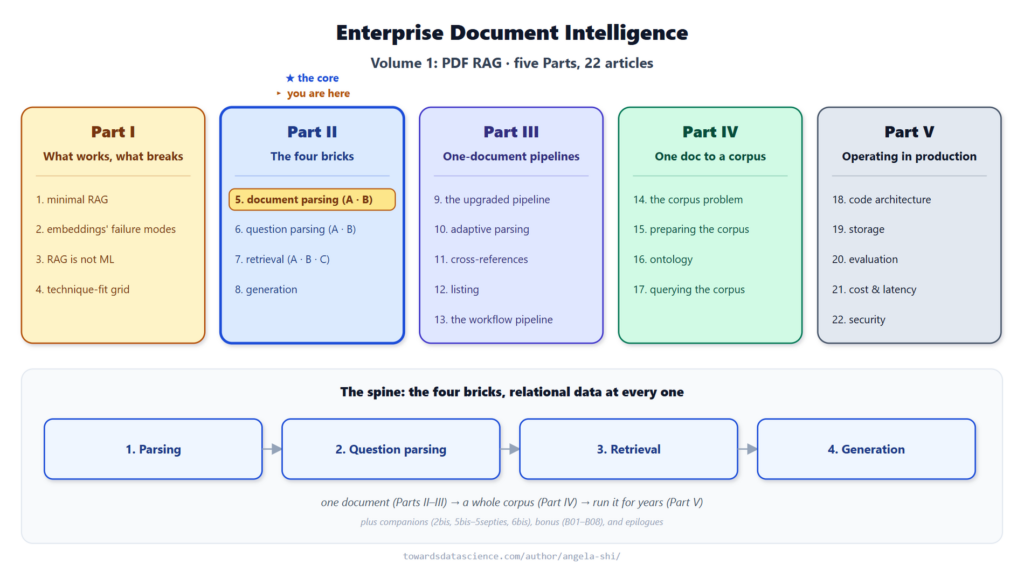 So sánh cấu trúc phân tích tài liệu
So sánh cấu trúc phân tích tài liệu
PyMuPDF hoạt động xuất sắc với các văn bản sạch sẽ, nhưng nó trở nên "mù lòa" trong ba tình huống phổ biến trong tài liệu doanh nghiệp: các bảng biểu phức tạp, các trang được quét (scanned pages), và các hình ảnh chứa văn bản bên trong.
1. Những điểm mù của PyMuPDF
1.1. Bảng biểu: Fitz trả về từ phẳng, Azure trả về ô
Khi gặp một bảng trong hợp đồng, PyMuPDF thường đọc các ô theo thứ tự từ trên xuống dưới và nối chúng lại thành một chuỗi văn bản liên tục. Cấu trúc cột và hàng bị mất đi. Ví dụ, "Phí gia hạn 500 Phí thiết lập 200" sẽ trở thành một đoạn văn vô nghĩa, khiến mô hình AI khó xác định số tiền tương ứng với loại phí nào.
Ngược lại, mô hình prebuilt-layout của Azure phát hiện bảng như một đối tượng có cấu trúc. Nó trả về danh sách các ô được lập chỉ mục theo hàng và cột, bao gồm cả việc đánh dấu dòng tiêu đề. Điều này cho phép tái tạo lại cấu trúc bảng dưới dạng Markdown, giúp RAG hiểu rõ mối quan hệ giữa dữ liệu.
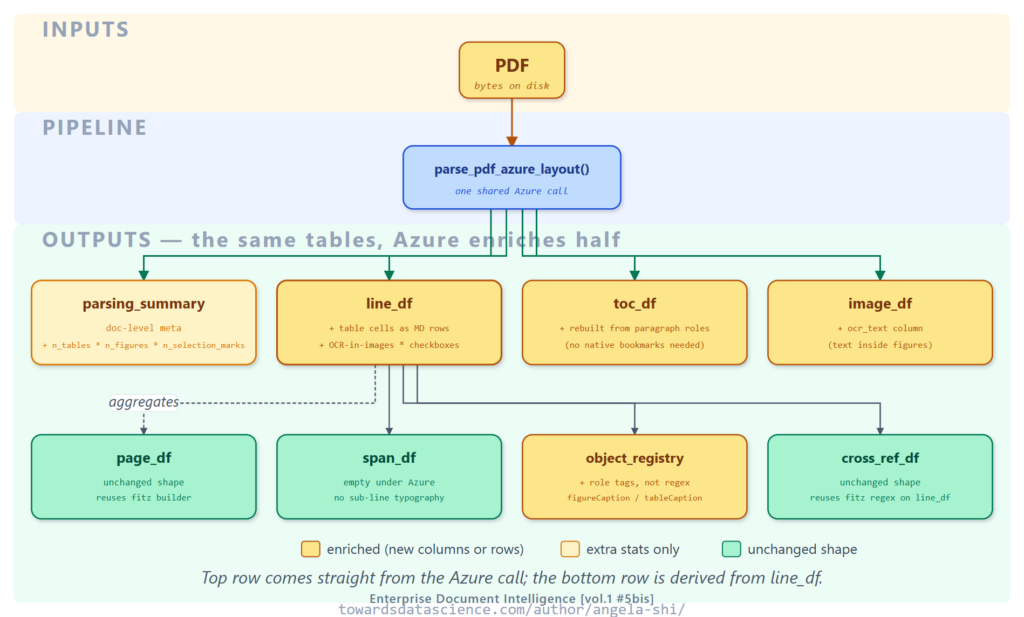 So sánh cách trích xuất bảng
So sánh cách trích xuất bảng
1.2. Hình ảnh: Fitz chỉ trả về khung, Azure trả về văn bản
Nhiều PDF chứa biểu đồ, sơ đồ kiến trúc hoặc ảnh chụp màn hình bảng tính có nhãn bên trong. PyMuPDF chỉ trả về tọa độ khung hình (bbox) và dữ liệu nhị phân của ảnh; văn bản bên trong ảnh bị vô hình đối với trình phân tích.
Azure chạy OCR trên mọi trang, bao gồm cả các pixel bên trong vùng hình ảnh. Nó thu thập các từ nằm trong hình ảnh và gán chúng vào cột ocr_text. Nhờ đó, người dùng có thể tìm kiếm câu hỏi về "multi-head attention" ngay cả khi câu trả lời chỉ nằm trong nhãn của một biểu đồ.
1.3. Trang quét và Chú thích
Với các phụ lục được quét dán vào cuối tài liệu, PyMuPDF trả về chuỗi rỗng vì không có lớp văn bản số. Azure thì xử lý đồng nhất cả trang gốc và trang quét thông qua OCR.
Đối với chú thích (caption), PyMuPDF dựa vào Regex (ví dụ: bắt đầu bằng "Figure 1"), dễ gây ra lỗi sót hoặc báo sai. Azure gán thẻ vai trò (role) rõ ràng như figureCaption, tableCaption, title cho từng đoạn văn, giúp nhận diện chính xác mà không cần biểu thức chính quy phức tạp.
2. Cùng một hợp đồng, dữ liệu phong phú hơn
Mục tiêu là thay thế động cơ phân tích mà không làm vỡ quy trình hạ lưu (downstream pipeline). Hàm parse_pdf_azure_layout được thiết kế để trả về cùng một cấu trúc từ điển dữ liệu như phiên bản PyMuPDF, đảm bảo tính tương thích.
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeDocumentRequest
from azure.core.credentials import AzureKeyCredential
client = DocumentIntelligenceClient(endpoint, AzureKeyCredential(key))
with open("contract.pdf", "rb") as f:
poller = client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(bytes_source=f.read()),
)
result = poller.result()
Một lệnh gọi duy nhất đến mô hình "prebuilt-layout" trả về tất cả: bảng, vai trò đoạn văn, OCR và thứ tự đọc. Các bảng dữ liệu đầu ra như line_df, image_df, toc_df được xây dựng từ kết quả này, giữ nguyên hình dạng để các giai đoạn xử lý tiếp theo không cần biết động cơ nào đã chạy.
3. Những gì mỗi bảng dữ liệu thu được
3.1. line_df: Hàng ô bảng, OCR hình ảnh
Thay vì chỉ là các dòng văn bản thuần túy, line_df giờ đây chứa các dòng bảng được định dạng Markdown. Ví dụ, một hàng 4 ô trở thành một dòng duy nhất chứa văn bản | Cột 1 | Cột 2 | .... Điều này giúp trình truy xuất (retriever) dễ dàng khớp từ khóa và LLM có thể đọc hiểu cấu trúc bảng.
Ngoài ra, văn bản OCR từ bên trong hình ảnh cũng được thêm vào line_df dưới dạng các dòng bổ sung.
3.2. toc_df: Tái tạo từ vai trò đoạn văn
Khi PDF không có dấu trang (bookmarks) gốc – trường hợp rất phổ biến ở tài liệu doanh nghiệp – PyMuPDF trả về mục lục rỗng. Azure xây dựng lại mục lục từ các đoạn văn có vai trò title (cấp 1) và sectionHeading (cấp 2). Mặc dù không hoàn hảo tuyệt đối, nó cung cấp đủ cấu trúc phần để RAG neo câu trả lời vào đúng đoạn văn.
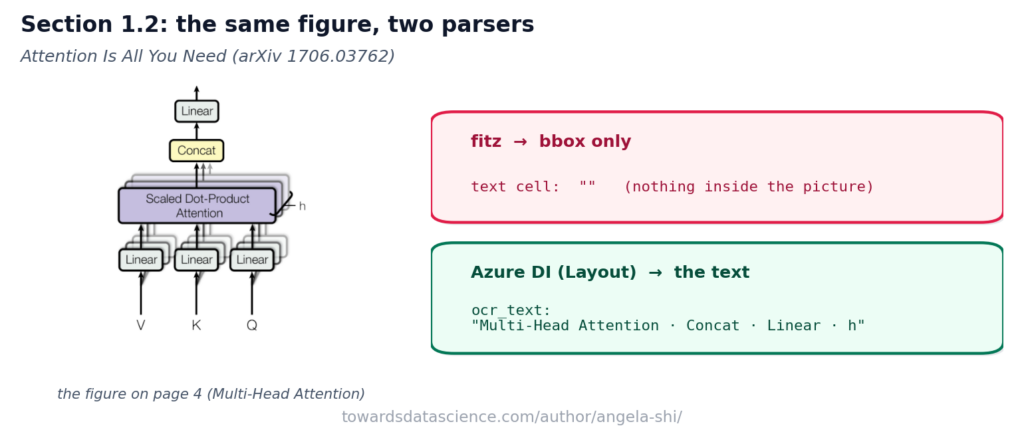 Tái tạo cấu trúc tài liệu
Tái tạo cấu trúc tài liệu
3.3. object_registry: Nhận diện chú thích bằng vai trò
Azure loại bỏ vấn đề Regex bằng cách gán thẻ figureCaption và tableCaption trực tiếp. Điều này tăng độ chính xác (recall) trong việc phát hiện các đối tượng mà PyMuPDF thường bỏ sót.
4. Chi phí và Độ trễ: Cân nhắc khi sử dụng Azure
Azure không miễn phí. Có ba yếu tố kỹ thuật quan trọng cần cân nhắc:
- Độ trễ: Một trang qua prebuilt-layout mất 2-4 giây. Một tài liệu 30 trang có thể mất 1-2 phút. Trong khi đó, PyMuPDF xử lý cùng tài liệu trong dưới một giây.
- Chi phí: Azure tính phí theo trang, khoảng 10 USD cho 1.000 trang. Một hợp đồng 30 trang tốn khoảng 0,30 USD. Nếu xử lý hàng nghìn tài liệu mỗi ngày, chi phí sẽ tăng lên nhanh chóng.
- Giới hạn: Giới hạn kích thước mỗi lần gọi là 500 MB hoặc 2.000 trang.
5. Chiến lược Phân tích Thích ứng (Adaptive Parsing)
Vì lý do chi phí và tốc độ, chúng ta không nên dùng Azure cho mọi thứ. Chiến lược khuyến nghị là:
- Mặc định dùng PyMuPDF: Nhanh và miễn phí.
- Nâng cấp lên Azure khi có tín hiệu thất bại:
- Trang có vùng bảng nhưng PyMuPDF trích xuất ít hoặc không có cấu trúc hàng.
- Trang chứa nhiều hình ảnh với văn bản thưa thớt.
- Chất lượng OCR của PyMuPDF thấp (văn bản bị lỗi).
- Tài liệu thiếu mục lục gốc và hệ thống cần ngữ cảnh phần.
Mỗi dòng dữ liệu đều có cột parsing_method để đánh dấu nguồn gốc ("fitz" hay "azure_layout"). Điều này cho phép hệ thống kết hợp dữ liệu từ cả hai động cơ một cách minh bạch, ưu tiên kết quả từ Azure khi cần thiết.
Kết luận
Hai động cơ, một hợp đồng: cùng một bảng quan hệ đầu ra, cùng một mã nguồn hạ流速 bất kể động cơ nào chạy.
Một trình phân tích tốt không chỉ trả về văn bản; nó trả về một mô hình của tài liệu. Azure làm cho mô hình đó phong phú hơn (bảng cấp độ ô, OCR trong hình ảnh, chú thích được gán thẻ) với chi phí 2-4 giây và khoảng 0,01 USD mỗi trang. PyMuPDF tốn kém 0 đồng và chạy trong mili giây. Quy tắc định tuyến đơn giản: dùng PyMuPDF theo mặc định, chỉ gọi đến Azure khi các tín hiệu cho thấy PyMuPDF không đủ khả năng.

