
Bốn bề mặt bảo mật nguy hiểm khi triển khai AI Agent: Từ Tiêm lệnh đến Độc bộ nhớ
Các cuộc tấn công vào prompt truyền thống chỉ là bề nổi của tảng băng chìm. Bài viết này phân tích khung lý thuyết về bốn bề mặt tấn công backend mới xuất hiện khi AI Agent được trang bị khả năng sử dụng công cụ và lưu trữ bộ nhớ, cùng các biện pháp giảm thiểu rủi ro hiệu quả.
Từ LLM đến Agent: Tại sao mô hình đe dọa lại thay đổi?
Hầu hết các công tác bảo mật AI hiện nay tập trung vào mô hình ngôn ngữ lớn (LLM): xem xét nội dung nó tạo ra, những gì nó từ chối và cách xử lý các câu hỏi độc hại. Cách tiếp cận này hợp lý khi AI chỉ là một giao diện văn bản đơn giản. Người dùng gửi tin nhắn, máy trả lời. Bề mặt tấn công lúc này hẹp và dễ xác định.
Tuy nhiên, AI Agent đã thay đổi hoàn toàn hình thức của vấn đề. Một AI Agent không chỉ tạo ra văn bản; nó lập kế hoạch, sử dụng các công cụ, lưu trữ bộ nhớ qua các phiên làm việc và thường xuyên phối hợp với các Agent khác để hoàn thành các nhiệm vụ đa bước. Hãy tưởng tượng sự khác biệt giữa một ứng dụng bản đồ đề xuất lộ trình và một hệ thống lái tự động kết nối trực tiếp với vô lăng và chân ga của xe. Một bên cung cấp thông tin, bên kia thực hiện quyền kiểm soát. Mô hình rủi ro giờ đây không thể so sánh được.
Các con số xác nhận đây không còn là mối lo ngại lý thuyết. Theo báo cáo "Trạng thái Bảo mật AI Agent 2026" của Gravitee, dựa trên khảo sát hơn 900 giám đốc điều hành và chuyên gia thực hành:
- 88% tổ chức báo cáo đã gặp phải hoặc nghi ngờ có sự cố bảo mật liên quan đến AI Agent trong năm qua.
- Chỉ có 14,4% hệ thống Agent được đưa vào vận hành với sự phê duyệt đầy đủ về bảo mật và CNTT.
Khoảng cách giữa tốc độ triển khai và sự sẵn sàng về bảo mật chính là nơi xảy ra các sự cố.
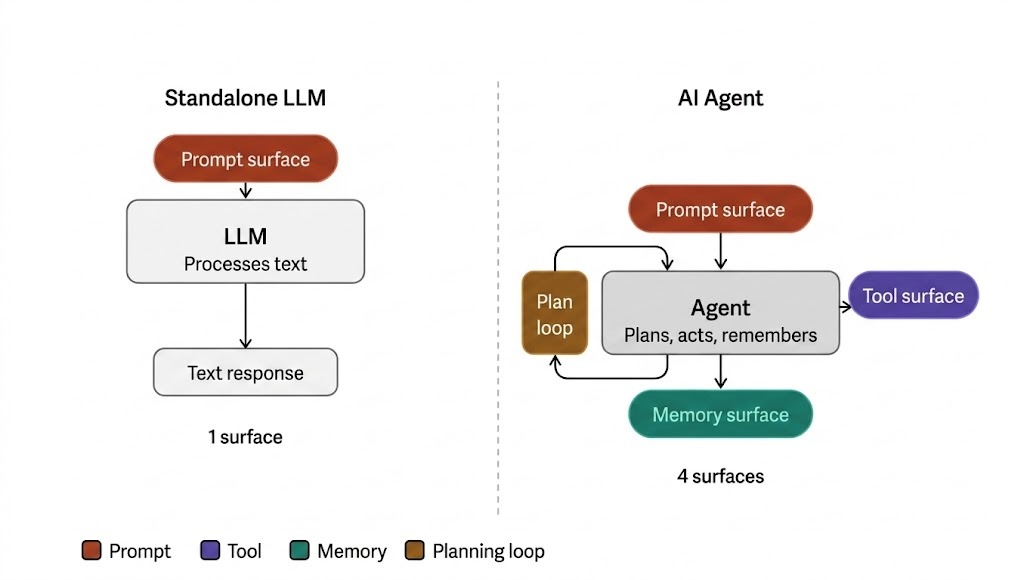 Bốn bề mặt tấn công của AI Agent
Bốn bề mặt tấn công của AI Agent
Một LLM độc lập chỉ có một bề mặt tấn công: prompt. Một Agent lại lộ ra bốn bề mặt:
- Bề mặt Prompt (The Prompt Surface): Đọc đầu vào bên ngoài.
- Bề mặt Công cụ (The Tool Surface): Thực thi hành động backend.
- Bề mặt Bộ nhớ (The Memory Surface): Ghi nhớ các phiên trước.
- Bề mặt Vòng lặp Lập kế hoạch (The Planning Loop Surface): Quyết định bước tiếp theo.
Mỗi bề mặt có các mô hình tấn công riêng biệt. Các biện pháp phòng thủ xây dựng cho bề mặt này không thể áp dụng cho bề mặt khác.
Phân loại bốn bề mặt tấn công
Vào giữa năm 2025, Pomerium đã báo cáo về một AI Agent hỗ trợ khách hàng đã vô tình thực thi một tải trọng SQL ẩn, làm lộ bí mật cơ sở dữ liệu vào một vé công khai. Bảo mật truyền thống thất bại ở đây. Việc thêm công cụ, bộ nhớ và lập kế hoạch tự chủ vào LLM tạo ra bốn bề mặt tấn công riêng biệt, mỗi cái đòi hỏi một mô hình đe dọa hoàn toàn mới.
1. Bề mặt Prompt: Khi Agent đọc sai nội dung
Đầu vào của người dùng có thể hoàn toàn sạch sẽ. Lỗ hổng nằm ở mọi thứ khác mà Agent tiêu thụ.
Khi một Agent lấy dữ liệu từ một trang web, tài liệu RAG (Retrieval-Augmented Generation), hoặc phản hồi backend, các đầu vào này đến mà không có ranh giới tin cậy. Kẻ tấn công không cần xâm nhập giao diện người dùng; chúng cài đặt các tải độc (payload) tại nơi Agent sẽ eventually nhìn thấy. Đây được gọi là tiêm lệnh gián tiếp (indirect prompt injection).
Vì các mô hình làm phẳng tất cả văn bản vào một cửa sổ ngữ cảnh duy nhất, chúng không thể phân biệt hướng dẫn hệ thống của bạn với một lệnh ẩn bên trong một tệp PDF được truy xuất. Chúng coi văn bản độc hại là ngữ cảnh tin cậy. Ngay cả tài liệu công cụ và tên tham số cũng có thể vô tình chiếm đoạt hành vi của Agent, dẫn đến việc rò rỉ dữ liệu âm thầm ngược dòng trong khi người dùng nhìn thấy một phản hồi bình thường.
Biện pháp phòng thủ:
- Khử ranh giới: Coi tất cả dữ liệu bên ngoài là không tin cậy tại mọi điểm truy xuất.
- Tách biệt hướng dẫn: Sử dụng định dạng có cấu trúc để cô lập prompt hệ thống khỏi nội dung được lấy về.
- Lọc trước khi thực thi: Quét các mẫu rò rỉ dữ liệu trước khi bất kỳ công cụ nào kích hoạt.
2. Bề mặt Công cụ (Tool Surface): Khi đọc biến thành hành động
Mọi công cụ mà Agent có thể gọi là một ranh giới quyền hạn, khiến nó trở thành mục tiêu chính để khai thác. Tấn công cốt lõi ở đây là tiêm tham số (parameter injection): thao túng Agent để chuyển các giá trị do kẻ tấn công kiểm soát vào các công cụ kích hoạt hậu quả thực tế, như ghi vào cơ sở dữ liệu hoặc các yêu cầu API đã ký名.
Vụ việc Pomerium nêu trên minh họa chính xác cách nó thất bại trong thực tế. Cuộc tấn công thành công vì ba lỗi kiến trúc hội tụ: cấp quyền quá mức cho Agent, đầu vào người dùng không được xác thực đến công cụ SQL, và một kênh dữ liệu đầu ra mở. Thật không may, đây là cấu hình mặc định của hầu hết các Agent hiện nay.
Biện pháp phòng thủ:
- Quyền tối thiểu (Least Privilege): Phạm vi quyền hạn nghiêm ngặt chỉ cho nhiệm vụ chính xác.
- Xác thực tham số: Xác minh tất cả đầu vào dựa trên lược đồ nghiêm ngặt trước khi thực thi.
- Điểm kiểm tra của con người: Yêu cầu phê duyệt thủ công cho bất kỳ hành động không thể đảo ngược nào.
3. Bề mặt Bộ nhớ (Memory Surface): Khi "bảng trắng" bị làm giả
Hãy tưởng tượng một bảng trắng văn phòng dùng để ra quyết định hàng ngày. Nếu một người ngoài âm thầm viết lại một mục qua đêm, toàn bộ đầu ra của nhóm sẽ thay đổi dựa trên dữ liệu bị tham nhũng. Bộ nhớ liên tục trong một Agent tự chủ hoạt động chính xác như vậy. Kiểm soát những gì Agent nhớ, và bạn sẽ chi phối các hành động trong tương lai của nó trên các phiên và người dùng.
Dữ liệu về lỗ hổng này cực kỳ đáng lo ngại:
- Khung MINJA: Kiểm thử bảo mật trên các mô hình hàng đầu đạt tỷ lệ thành công 95% trong việc tiêm lầm ký ức giả, hoàn toàn không cần quyền nâng cao hoặc quyền truy cập API.
- Microsoft Defender Intel: Chỉ trong 60 ngày, các nhà nghiên cứu đã chặn hơn 50 cuộc tấn công trên 14 ngành công nghiệp. Kẻ đối thủ đã sử dụng các tham số URL ẩn để bí mật hướng dẫn Agent ưu tiên các công ty cụ thể trong các phản hồi trong tương lai.
- Triển khai chi phí bằng 0: Các cuộc tấn công này không được khởi chạy bởi các nhóm đe dọa tiên tiến. Chúng được thực hiện bởi các nhóm tiếp thị hàng ngày sử dụng các gói phần mềm miễn phí.
Biện pháp phòng thủ:
- Theo dõi nguồn gốc (Provenance Tracking): Ghi nhật ký an toàn nguồn, ngữ cảnh và dấu thời gian của mọi lần ghi bộ nhớ.
- Truy xuất có trọng số tin cậy: Các mục nhập của người dùng được xác thực phải vượt trội hơn nội dung bên ngoài chưa được xác minh.
- Suy giảm theo thời gian (TTL): Thiết lập ngưỡng tuổi nơi các mục bộ nhớ suy giảm hoặc bị xóa rõ ràng.
- Kiểm toán định kỳ: Chạy các bản kiểm toán tự động để phát hiện các cụm lệnh độc hại bất thường.
4. Vòng lặp Lập kế hoạch (Planning Loop): Khi đích đến sai
Một GPS được cung cấp dữ liệu bản đồ sai vẫn đưa ra chỉ đường từng bước một một cách tự tin. Logic định tuyến hoạt động hoàn hảo, nhưng đích đến thì sai. Người lái xe không biết gì cho đến khi họ đến một nơi họ không bao giờ định đến.
Vòng lặp lập kế hoạch là động cơ lý luận của Agent. Nếu kẻ tấn công thay đổi nơi Agent nghĩ rằng nó đang đi, chúng không cần tiêm các lệnh cụ thể. Agent sẽ tự động điều hướng đến mục tiêu độc hại.
Sự thay đổi này có thể bắt nguồn từ bất kỳ bề mặt nào chúng ta vừa đề cập: một mục bộ nhớ bị độc, kết quả công cụ bị thao túng, hoặc tài liệu bên ngoài độc hại. Nhưng mối nguy hiểm thực sự là tốc độ lây lan. Trong một mô phỏng tháng 12/2025 của Galileo AI, một bộ điều phối bị xâm phạm đã làm độc 87% việc ra quyết định hạ nguồn trong kiến trúc đa-Agent trong vòng bốn giờ. Nó làm hỏng mọi Agent tin tưởng vào đầu ra của nó.
Biện pháp phòng thủ:
- Ghi nhật ký lý luận: Ghi nhật ký các bước lý luận trung gian, không chỉ là đầu ra cuối cùng.
- Xác thực điểm kiểm tra: Xác thực trạng thái mục tiêu tại các điểm kiểm tra được xác định trong quá trình thực thi nhiệm vụ.
- Ranh giới cứng: Định nghĩa các điều kiện dừng nghiêm ngặt khi triển khai mà nội dung được truy xuất không thể ghi đè.
- Cô lập Agent: Cô lập các phiên bản Agent để một sự xâm phạm đơn lẻ không thể lan truyền tự do qua hệ thống.
Bảo mật so với Tự chủ của Agent: Không gian đánh đổi
Mọi biện pháp giảm thiểu trên các bề mặt Prompt, Công cụ, Bộ nhớ và Vòng lặp Lập kế hoạch đều mang lại chi phí vốn có. Bỏ qua các đánh đổi này tạo ra "kịch bản bảo mật" thay vì sự bảo vệ thực tế.
Sandboxing môi trường công cụ giới hạn những gì Agent có thể đạt được — đây chính là điểm mấu chốt — nhưng nó cũng hoạt động như một sự giảm trực tiếp khả năng tổng thể của Agent. Tương tự, việc triển khai các cổng "con người trong vòng lặp" (human-in-the-loop) cho các hành động không thể đảo ngược ngăn chặn các ghi trái phép nhưng lại引入 độ trễ có thể làm xói mòn cơ sở kinh doanh của tự động hóa.
Bảo mật và tự chủ tồn tại trên một chiếc núm vặn, không phải là công tắc bật/tắt nhị phân. Cài đặt tối ưu cho bất kỳ triển khai nào được xác định bởi ba yếu tố cụ thể:
- Hồ sơ khả năng: Các biện pháp kiểm soát phải tỷ lệ thuận với những gì Agent được quyền làm.
- Môi trường nhiệm vụ: Một Agent tóm tắt tài liệu nội bộ hoạt động trong môi trường đe dọa khác biệt hoàn toàn với một Agent quản lý hạ tầng quan trọng.
- Phạm vi ảnh hưởng (Blast Radius): Các quyết định nên dựa trên kết quả tồi tệ nhất của một cuộc khai thác thay vì xác suất cảm nhận của nó.
Triển khai: Từ Phân loại đến Kiến trúc
Phân loại các bề mặt tấn công chỉ có ý nghĩa nếu nó ảnh hưởng trực tiếp đến cách xây dựng hệ thống. Cảnh thái đe dọa chủ động phụ thuộc hoàn toàn vào khả năng của Agent.
Khớp các biện pháp kiểm soát với Kiến trúc
- Agent Công cụ đơn (Single-Tool Agents): Đối với các Agent không có bộ nhớ liên tục và không có hành động đầu ra, lỗ hổng chính là bề mặt Prompt. Bảo mật khả thi tối thiểu bao gồm khử đầu vào tại các ranh giới truy xuất, quyền hạn được giới hạn chặt chẽ và ghi nhật ký đầy đủ các cuộc gọi công cụ.
- Bộ điều phối Đa-Agent (Multi-Agent Orchestrators): Các hệ thống có bộ nhớ liên tục và khả năng tạo ra các Agent hạ tầng lộ ra cả bốn bề mặt đồng thời.
Ưu tiên theo Phạm vi ảnh hưởng
Bảo mật hiệu quả ưu tiên tác động tiềm năng của một cuộc khai thác hơn là khả năng xảy ra cảm nhận của nó:
- Quyền hạn lên đầu: Hầu hết các sự cố, như vụ rò rỉ Supabase, bắt nguồn từ quyền hạn quá mức; việc thực thi quyền tối thiểu là biện pháp kiểm soát có đòn bẩy cao nhất và chi phí thấp nhất.
- Tách biệt nguồn hướng dẫn: Hướng dẫn hệ thống và nội dung được truy xuất không bao giờ được chia sẻ ngữ cảnh tin cậy để đóng phần lớn bề mặt Prompt.
- Nguồn gốc bộ nhớ: Nghiên cứu như MemoryGraft cho thấy cách bộ nhớ bị độc cộng hưởng; việc theo dõi nguồn của mọi lần ghi bộ nhớ phải được đặt trước khi mở rộng quy mô.
- Giám sát lý luận: Lọc đầu ra không thể phát hiện việc cướp mục tiêu; hệ thống phải ghi nhật ký các bước lý luận trung gian thay vì chỉ đầu ra cuối cùng.
Các khung ngoài quy trình (out-of-process) như Bộ công cụ Quản trị Agent của Microsoft thực thi các chính sách một cách độc lập, duy trì kiểm soát ngay cả khi Agent bị xâm phạm. Cuối cùng, bạn hoặc là lập bản đồ có chủ đích các bề mặt tấn công này trước khi triển khai, hoặc phát hiện ra chúng trong điều tra pháp y sau sự cố.
Kết luận
Sự chuyển dịch từ LLM sang Agent là một thay đổi cấu trúc về những gì hệ thống có thể làm và do đó, về những gì có thể sai sót. Bốn bề mặt được đề cập trong bài viết này cộng hưởng với nhau, nơi một mục bộ nhớ bị độc cho phép cướp mục tiêu, một công cụ quá quyền biến một cuộc tiêm thành rò rỉ dữ liệu, và một bộ điều phối bị xâm phạm làm hỏng mọi Agent hạ nguồn.
Các tổ chức quản lý hiệu quả những rủi ro này là những tổ chức đã lập bản đồ vấn đề trước khi triển khai, khớp các biện pháp kiểm soát với hồ sơ khả năng thực tế và xây dựng giám sát vào lớp lý luận thay vì chỉ lớp đầu ra. Phân loại này không loại bỏ mối đe dọa, nhưng nó cung cấp một bản đồ chính xác của địa hình trước khi bạn xây dựng trên đó, bởi vì những gì được lập bản đồ có thể được phòng thủ, và những gì bị bỏ qua sẽ được phát hiện thông qua một sự cố.
Bài viết liên quan

Phần cứng
Lỗ hổng kernel macOS đầu tiên bị khai thác thành công trên chip Apple M5
14 tháng 5, 2026
Công nghệ
Open Terminal: Ứng dụng phong cách Bloomberg giúp dân đầu tư cá nhân tiếp cận dữ liệu tài chính chuyên sâu
04 tháng 6, 2026

Công nghệ
Đi sâu vào tính bền vững tài chính của AI: Khi ngân sách Token không thể vô tận
16 tháng 6, 2026