
Cạm bẫy sự tự tin: Tại sao AI có thể sai dù chắc chắn 99%?
Các mô hình AI thường đưa ra câu trả lời sai với độ tự tin cực cao, gây hiểu lầm nghiêm trọng cho người dùng. Bài viết này khám phá cơ chế toán học đằng sau hiện tượng này và tầm quan trọng của việc hiệu chuẩn (calibration) để xây dựng lòng tin vào trí tuệ nhân tạo.

Cạm bẫy sự tự tin: Tại sao AI có thể sai dù chắc chắn 99%?
Năm ngoái, vào một ngày thứ Bảy thoải mái, tôi đã quyết định hỏi ChatGPT một câu hỏi khá đơn giản: "Ai đã giành giải Nobel Vật lý năm 2025?"
ChatGPT đã trả lời ngay lập tức: "Giải Nobel Vật lý năm 2025 đã được trao cho..." Nó thậm chí còn cung cấp cả tên người, lĩnh vực nghiên cứu và lời giải thích chi tiết về công trình nghiên cứu giúp họ giành giải!
Chỉ có một vấn đề nhỏ — thực ra là một vấn đề rất lớn. Giải Nobel năm đó vẫn chưa được công bố. Tuy nhiên, mô hình không hề do dự; không hề ngập ngừng; và chắc chắn không nói "Tôi không có đủ thông tin" hay hay hơn là "người chiến thắng giải Nobel năm 2025 vẫn chưa được công bố!"
Thay vào đó, nó tự tin bước vào phòng, ngồi xuống và trình bày những điều bịa đặt với năng lượng của một người đang bảo vệ luận án tiến sĩ. Là một người từng bảo vệ luận án tiến sĩ, tôi ước mình có sự tự tin như ChatGPT khi bịa chuyện!
Là con người, chúng ta có xu hướng làm một điều thú vị với sự tự tin: chúng ta liên kết nó với sự chính xác, nhưng điều đó không phải lúc nào cũng đúng. Nếu một người nói "Tôi nghĩ câu trả lời có thể là 42" và một người khác nói "Câu trả lời chắc chắn là 42", hầu hết chúng ta đều tin tưởng người thứ hai hơn, mặc dù khả năng sai lầm của cả hai là như nhau. Đối với chúng ta, sự tự tin đôi khi đóng vai trò là một tín hiệu hữu ích của sự chính xác. Tuy nhiên, đối với các hệ thống AI, sự tự tin có thể là một narrater (người kể chuyện) đáng tin cậy một cách đáng ngạc nhiên.
Trong bài viết này, chúng ta sẽ khám phá lý do tại sao.
Sự tự tin thường bị ngộ nhận là xác suất
Hãy giả sử chúng ta yêu cầu một Mô hình Ngôn ngữ Lớn (LLM) dự đoán con vật trong một bức ảnh nhất định. Nó nói:
- Mèo: 0.97
- Chó: 0.02
- Chim: 0.01
Hầu hết mọi người sẽ hiểu rằng: "Mô hình chắc chắn 97% đây là mèo."
Đó là một giả định hợp lý. Thật không may, ý nghĩa của những con số đó thường không giống như vậy. Chúng ta cần nhớ rằng nhiều mô hình AI sử dụng một hàm gọi là Softmax để tạo ra dự đoán.
Hàm Softmax chuyển đổi các đầu ra thô (gọi là logits) thành các giá trị tổng bằng một và giống như xác suất. Điều quan trọng cần lưu ý ở đây là số mũ (exponential term), có thể khiến những khác biệt nhỏ bỗng nhiên trở nên rất lớn.
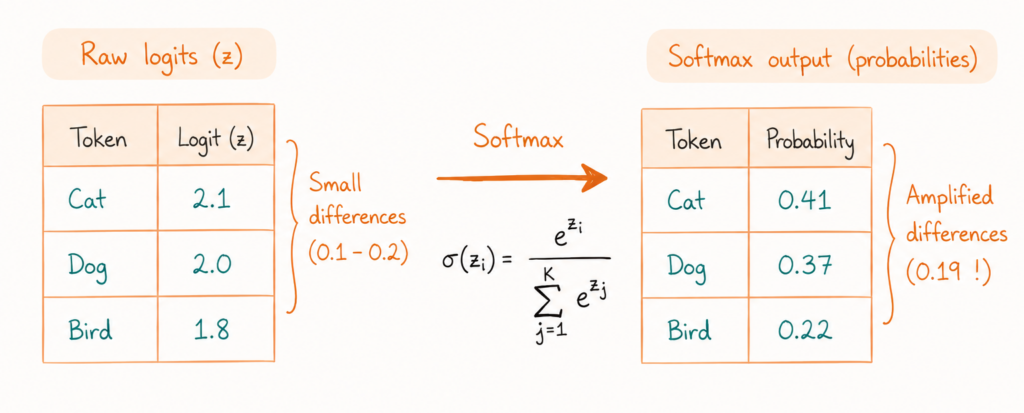 Cơ chế hàm Softmax trong AI
Cơ chế hàm Softmax trong AI
Về cơ bản, mô hình không đang nói "Tôi có bằng chứng áp đảo rằng đây là mèo". Nó có thể chỉ đang nói: "Trong số các lựa chọn này, mèo tình cờ chiến thắng với một chênh lệch nhỏ". Đó là hai tuyên bố rất khác nhau với ý nghĩa hoàn toàn khác nhau.
Con người và AI xử lý sự không chắc chắn khác nhau
Dù có thể khó chịu khi phải đối mặt với nó, con người lại khá giỏi trong việc biểu đạt và xử lý sự không chắc chắn.
Chúng ta thường xuyên nghe: "Tôi có thể sai...", "Tôi khá chắc chắn...", "Có lẽ...", hoặc "Tôi nghĩ...". Sự tự tin của chúng ta thường tồn tại dưới dạng một phổ. Tuy nhiên, các hệ thống AI lại thường cư xử giống như người trong nhóm làm việc tự tin giải thích về điều gì đó họ vừa học được ba phút trước (chắc chắn chúng ta đều từng có người bạn cùng lớp kiểu này...).
Vì vậy, khi trò chuyện với LLM, việc nói với nó "Tôi nghĩ Paris là thủ đô của Pháp" và nó phản hồi "Paris là thủ đô của Pháp với xác suất 99,8%", sẽ mang lại năng lượng tương tự như khi nói với nó "Tôi nghĩ Atlantis là hư cấu", và nó phản hồi "Atlantis nằm cách Bồ Đào Nha khoảng 400 dặm về phía tây với độ tin cậy 98,7%".
Mặc dù hai trường hợp có kết quả rất khác nhau, LLM lại đối xử với chúng như nhau.
Vấn đề của "Kẻ ngốc tự tin" (The Confident Fool Problem)
Điều này tạo ra những gì tôi gọi là vấn đề của "kẻ ngốc tự tin". Một hệ thống có thể sai một cách ngoạn mục trong khi nghe có vẻ chắc chắn ngoạn mục. Và không may thay, sự tự tin thường tăng lên chính xác vào lúc chúng ta muốn sự thận trọng hơn.
Vấn đề này trở nên đặc biệt rõ ràng khi LLM gặp phải các tình huống nằm ngoài phân phối dữ liệu huấn luyện của chúng.
Giả sử chúng ta huấn luyện một bộ phân loại hình ảnh để nhận dạng mèo và chó. Nhưng sau đó chúng ta quyết định đưa cho nó một bức ảnh của chiếc máy nướng bánh! Lý tưởng nhất, mô hình nên nói "Tôi hoàn toàn không biết đây là cái gì". Phản ứng của hầu hết mọi người khi được nhìn thấy một thứ họ chưa từng thấy là gì? Thay vì nói vậy, mô hình có thể phản hồi:
- Chó: 98%
- Mèo: 2%
Bây giờ, trừ khi chiếc máy nướng bánh của bạn có hình giống chó chó (Poodle), câu trả lời đó rõ ràng là sai!
Tại sao điều này lại xảy ra? Câu trả lời đơn giản hơn hầu hết mọi người nghĩ. Đơn giản là nó xảy ra vì mô hình chưa bao giờ được huấn luyện để nói: "Không có đáp án nào ở trên". Vì vậy, khi gặp một thứ gì đó quen thuộc, nó chọn điểm số cao nhất trong số các lựa chọn có sẵn.
Nó giống như ép buộc một người phải trả lời câu hỏi "Đây là loại quả nào?" trong khi chỉ vào một chiếc xe đạp. Cuối cùng, họ sẽ chọn một loại quả chỉ để giải quyết tình huống và nói: "Chuối?"
Hãy mô phỏng một mô hình quá tự tin.
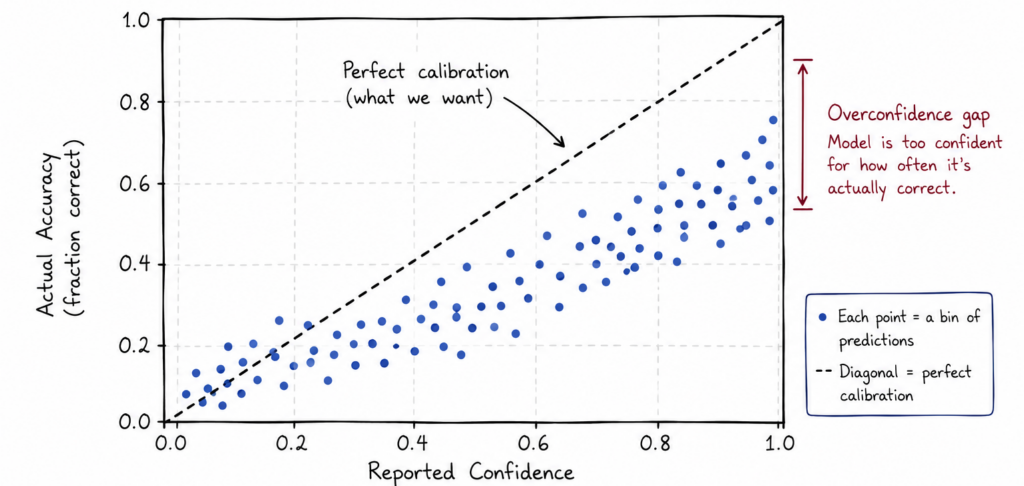 Mô phỏng sự quá tự tin của mô hình
Mô phỏng sự quá tự tin của mô hình
Nếu mô hình báo cáo "độ tin cậy 90%", chúng ta hy vọng nó đúng khoảng 90% thời gian. Thay vào đó, nhiều hệ thống trông giống như "độ tin cậy 90%, độ chính xác 65%". Khoảng cách giữa sự tự tin và độ chính xác này là lý do tại sao cách chúng ta chọn để huấn luyện các LLM này lại rất quan trọng.
Dạy mô hình thành thật hơn
Được rồi, chúng ta biết tại sao các mô hình có xu hướng sai một cách tự tin như vậy, nhưng làm thế nào chúng ta có thể vượt qua điều đó để có được các mô hình tốt hơn với độ chính xác cao hơn, hoặc độ chính xác phù hợp với sự tự tin của chúng? Đây là lúc hiệu chuẩn (calibration) đóng vai trò quan trọng.
Hiệu chuẩn không nhất thiết cải thiện dự đoán. Thay vào đó, nó cải thiện sự trung thực! Vì vậy, nếu một mô hình nói 90% sau khi hiệu chuẩn, nó có nghĩa là: "Về mặt lịch sử, các dự đoán ở mức độ tin cậy này đã đúng khoảng 90% thời gian."
Các phương pháp như:
- Platt Scaling
- Temperature Scaling
- Hồi quy đẳng hướng (Isotonic Regression)
cố gắng căn chỉnh sự tự tin dự đoán với kết quả quan sát được.
Hãy xem điều này trông như thế nào:
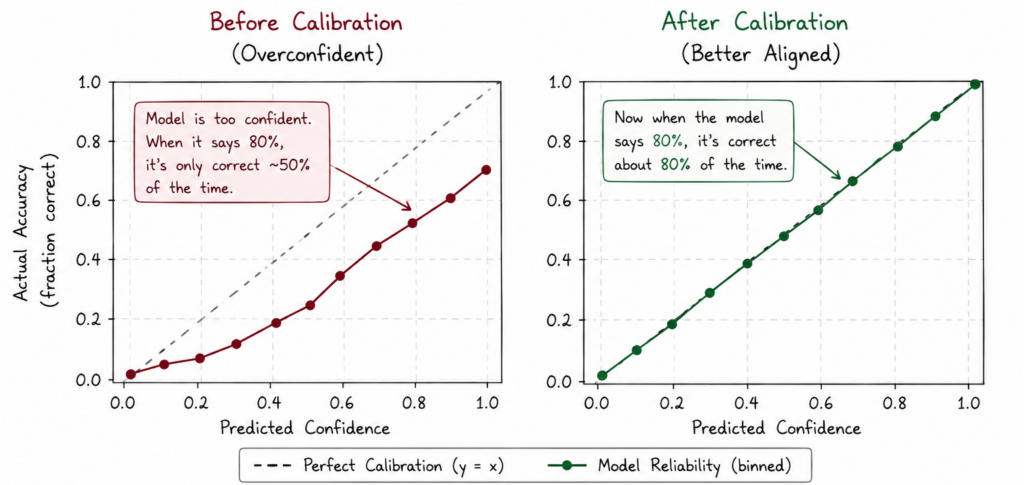 Quá trình hiệu chuẩn mô hình AI
Quá trình hiệu chuẩn mô hình AI
Tại sao điều này lại quan trọng?
Rất dễ để cười khi một AI nghĩ máy nướng bánh là con chó. Vì điều đó, tranh cãi một chút, rất hài hước. Tuy nhiên, tồn tại nhiều tình huống ít hài hước hơn. Không chỉ ít hài hước, mà còn mang tính nghiêm trọng, và có thể đe dọa đến tính mạng. Việc sử dụng LLM trong các hệ thống chẩn đoán y tế, xe tự hành, phát hiện gian lận và dự báo tài chính đòi hỏi độ chính xác cao.
Nếu một mô hình nói với bác sĩ: "Xác suất ung thư: 99%" hoặc "Xác suất ung thư: 62%", phản ứng của bác sĩ sẽ khác nhau rất nhiều!
Nếu các điểm số tự tin được hiệu chỉnh kém, mọi người có thể tin tưởng vào những dự đoán không xứng đáng được tin tưởng. Và con người đặc biệt dễ bị tổn thương ở đây vì sự tự tin nghe rất thuyết phục. Ngay cả khi chúng ta biết rõ hơn.
Khi các mô hình tiếp tục chuyển vào các quy trình làm việc trong thế giới thực, chúng ta có thể cần ngừng hỏi: "Mô hình chính xác đến mức nào?" và bắt đầu hỏi: "Khi mô hình nói 90%, có thực sự có nghĩa là 90% không?". Bởi vì có sự khác biệt giữa một mô hình thông minh và một mô hình đáng tin cậy.
Con người cũng không hoàn hảo về sự không chắc chắn. Chúng ta trở nên quá tự tin mọi lúc. Chúng ta nghĩ mình có thể hoàn thành một dự án trong hai ngày. Chúng ta nghĩ mình có thể lắp ráp đồ nội thất mà không cần đọc hướng dẫn. Chúng ta nghĩ mình chỉ cần một lần di chuyển từ xe ô tô để mang đồ tạp hóa vào nhà. Ngay cả khi lịch sử cho thấy điều ngược lại.
Có lẽ AI chỉ đơn giản là kế thừa một số thói quen xấu của chúng ta? Sự khác biệt là khi con người sai một cách tự tin, thường chỉ có vài người chịu ảnh hưởng. Khi AI sai một cách tự tin, sai lầm đó có thể mở rộng ra hàng triệu người, và sự tự tin ở quy mô lớn là một vấn đề rất khác.
Lời kết
Trong nhiều năm, chúng ta đã đo lường sự tiến bộ của AI bằng cách đặt ra các câu hỏi ngày càng ấn tượng:
Nó có thể viết mã không? Nó có thể tạo nghệ thuật không? Nó có thể vượt qua các kỳ thi không? Nó có thể suy luận không?
Những câu hỏi đó hữu ích, nhưng đôi khi chúng làm phân tâm chúng ta khỏi một câu hỏi quan trọng hơn:
Chúng ta có thể tin tưởng nó không?
Một mô hình đưa ra câu trả lời đúng một lần là thú vị. Một mô hình đưa ra câu trả lời đúng nhiều lần trong khi biết khi nào nó có thể sai là một điều hoàn toàn khác. Độ tin cậy hiếm khi tạo ra các tiêu đề gây sốc.
Sự tự tin không phải là vấn đề. Vấn đề bắt đầu khi sự tự tin trở thành một màn trình diễn thay vì một thước đo ý nghĩa về sự chắc chắn. Khi các hệ thống AI tiếp tục chuyển sang chăm sóc sức khỏe, giáo dục, tài chính, nghiên cứu và các quy trình ra quyết định, chúng ta có thể cần ngừng coi điểm số tự tin là đồng hồ đo sự thật và bắt đầu coi chúng là các ước tính cần được xác thực.
Bởi vì một mô hình nghe có vẻ chắc chắn là điều dễ dàng, trong khi một mô hình biết khi nào không nên chắc chắn có thể là một trong những vấn đề khó nhất mà chúng ta vẫn còn phải giải quyết.
Bài viết liên quan

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026

Công nghệ
Revolut bắt đầu triển khai dịch vụ cho hàng nghìn người dùng tại Ấn Độ trước khi ra mắt rộng rãi
01 tháng 6, 2026

Công nghệ
Phần mềm giám sát nhân viên đang bí mật chia sẻ dữ liệu với Meta và Google
21 tháng 5, 2026