
Cấu trúc và Thành phần của Coding Agent
Coding Agent là những công cụ đằng sau các hệ thống như Claude Code hay Codex, giúp mô hình ngôn ngữ lớn (LLM) vượt qua giới hạn của việc chat đơn thuần. Bài viết này đi sâu vào sáu thành phần cốt lõi: ngữ cảnh thư viện mã nguồn, cách xây dựng và lưu cache prompt, quản lý công cụ, giảm thiểu độ dài context, lưu trữ phiên làm việc và khả năng phân công nhiệm vụ.
Cấu trúc và Thành phần của Coding Agent
Coding Agent là những công cụ đằng sau các hệ thống như Claude Code hay Codex, giúp mô hình ngôn ngữ lớn (LLM) vượt qua giới hạn của việc chat đơn thuần. Bài viết này đi sâu vào sáu thành phần cốt lõi: ngữ cảnh thư viện mã nguồn, cách xây dựng và lưu cache prompt, quản lý công cụ, giảm thiểu độ dài context, lưu trữ phiên làm việc và khả năng phân công nhiệm vụ.
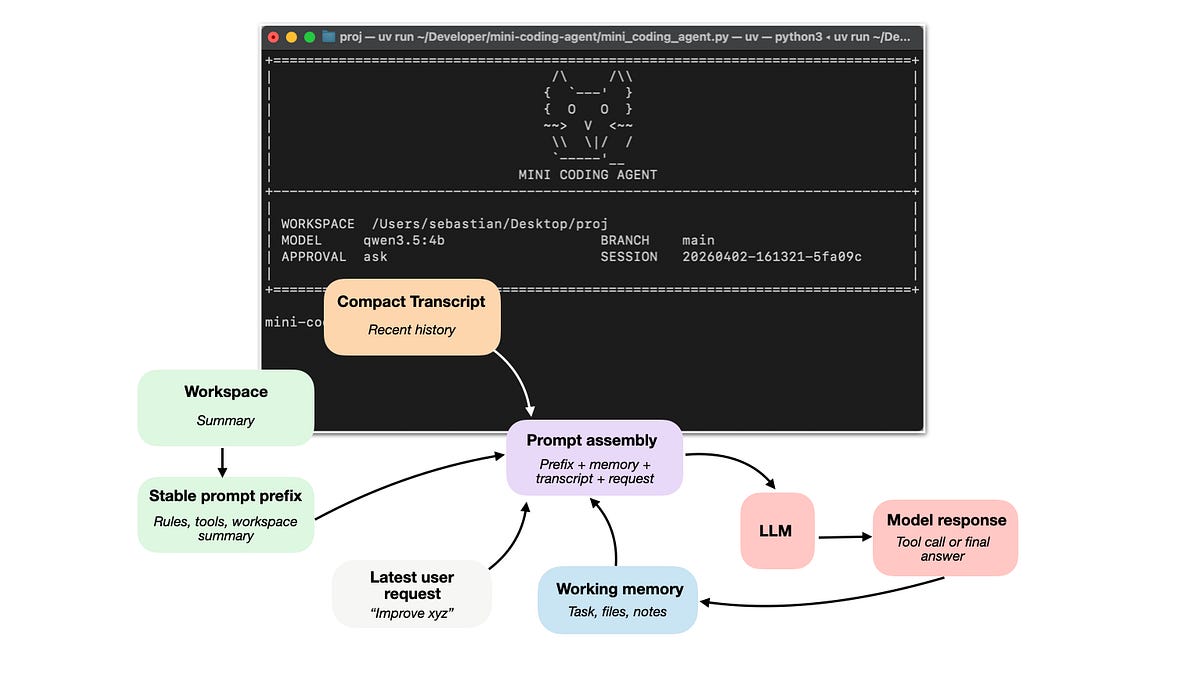
Trong kỷ nguyên AI hiện nay, sự tiến bộ không chỉ đến từ việc cải thiện mô hình ngôn ngữ lớn (LLM), mà còn từ cách chúng được tích hợp vào môi trường làm việc thực tế. Một Coding Agent thực sự hiệu quả không chỉ là một mô hình AI, mà là một lớp phần mềm bao quanh nó (harness), giúp tối ưu hóa việc viết và sửa code.
 Mô hình Coding Agent
Mô hình Coding Agent
Mối quan hệ giữa LLM và Agent
Trước khi đi vào chi tiết, cần phân biệt rõ ràng giữa LLM và Agent. LLM là động cơ cốt lõi, trả về dự đoán ký tự tiếp theo. Một Reasoning Model là một phiên bản LLM mạnh hơn, được huấn luyện để suy luận thêm ở thời gian suy luận. Trong khi đó, Agent là một lớp điều khiển bên trên, đóng vai trò như một vòng lặp (control loop). Agent quyết định xem mô hình cần xem gì, gọi công cụ như thế nào, cập nhật trạng thái ra sao và khi nào nên dừng lại.
 Sơ đồ mối quan hệ giữa LLM và Agent
Sơ đồ mối quan hệ giữa LLM và Agent
Coding Agent hay Coding Harness là một hệ thống scaffolding (khung xương) chuyên dụng cho phần mềm, quản lý bối cảnh mã nguồn, công cụ thực thi và phản hồi lặp đi lặp lại.
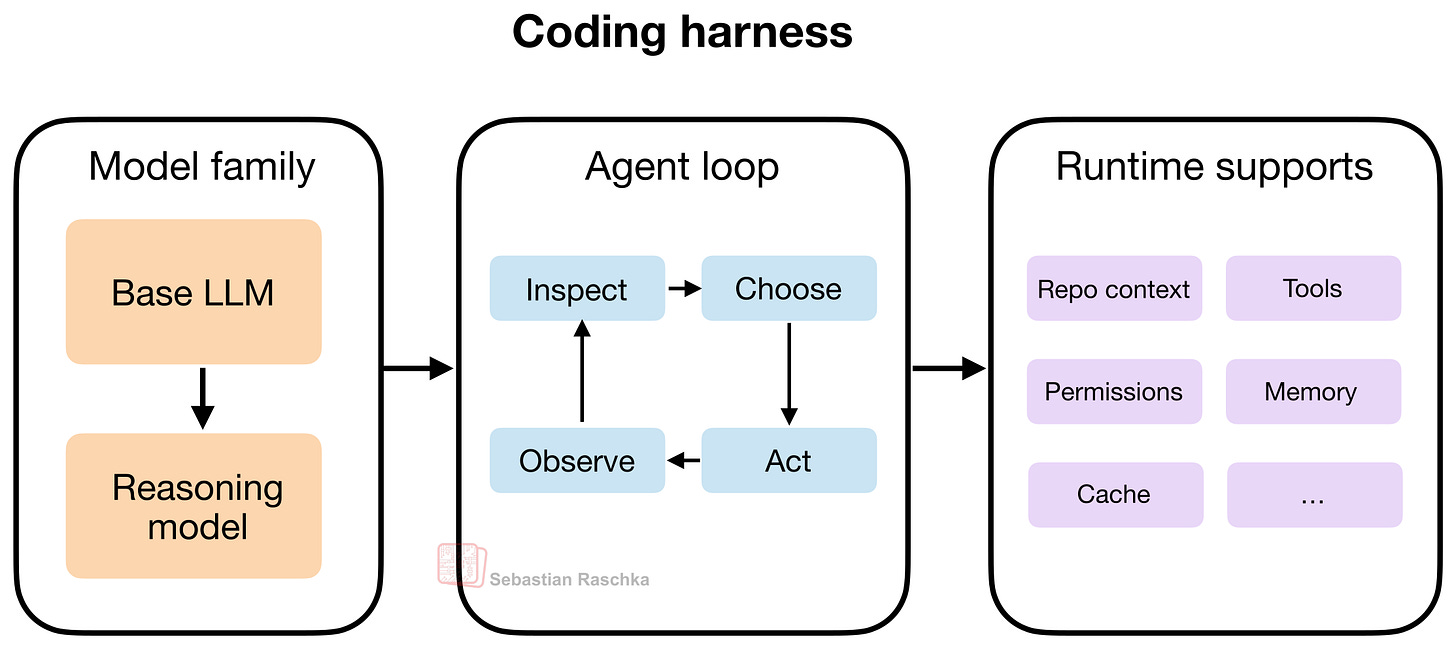
6 Thành phần cốt lõi của Coding Agent
Dưới đây là sáu yếu tố chính tạo nên một Coding Agent hiệu quả:
1. Nguồn gốc ngữ cảnh (Live Repo Context)
Đây là thành phần quan trọng nhất. Khi người dùng yêu cầu "sửa các bài kiểm tra" hay "triển khai tính năng XYZ", Agent cần biết nó đang làm việc ở đâu. Agent phải hiểu cấu trúc thư mục, nhánh Git đang hoạt động, và các tài liệu hướng dẫn trong dự án.
 Sơ đồ thành phần Coding Agent
Sơ đồ thành phần Coding Agent
Nếu Agent biết gốc thư mục (repo root) và bố cục, nó sẽ tìm đúng nơi cần thay đổi thay vì đoán mò. Điều này giúp Agent hiểu rõ "thật" (stable facts) trước khi bắt đầu công việc.
2. Hình dạng Prompt và Tái sử dụng Cache (Prompt Shape and Cache Reuse)
Sau khi có bối cảnh, vấn đề tiếp theo là làm thế nào để đưa thông tin đó vào mô hình một cách hiệu quả. Việc tổng hợp lại toàn bộ tóm tắt thư viện mã nguồn trên mỗi lần chat là lãng phí tính toán.
Một Harness thông minh sẽ xây dựng một Stable Prompt Prefix – chứa các hướng dẫn chung, mô tả công cụ và tóm tắt thư viện – và lưu vào bộ nhớ đệm (cache). Chỉ những phần thay đổi (yêu cầu mới nhất, lịch sử phiên gần đây) mới được thêm vào. Cách này giúp tiết kiệm tài nguyên và tăng tốc độ phản hồi.
3. Truy cập và sử dụng công cụ (Tool Access and Use)
Đây là lúc Coding Agent khác biệt với Chatbot. Một Chatbot chỉ có thể gợi ý lệnh bằng văn bản, nhưng một Agent thực sự có thể thực thi lệnh đó.
Agent được cung cấp danh sách các công cụ được xác định trước (ví dụ: chạy lệnh shell, đọc file, tìm kiếm). Khi mô hình muốn thực hiện hành động, nó không tự do viết bất cứ thứ gì; nó phải tuân theo cấu trúc có sẵn. Hệ thống sẽ kiểm tra xem hành động đó có hợp lệ, an toàn không, và có cần sự phê duyệt của người dùng không trước khi thực thi. Điều này giúp ngăn chặn các lệnh nguy hiểm hoặc sai cú pháp.
4. Giảm thiểu bloat context (Context Reduction and Output Management)
Mô hình LLM có giới hạn về độ dài context (số token). Trong các phiên làm việc dài, việc đọc file nhiều lần, in ra log dài dòng sẽ khiến prompt bị quá tải (bloat).
Một Coding Agent tốt phải có cơ chế nén thông tin:
- Cắt bớt (Clipping): Rút gọn các văn bản dài, log dài.
- Tóm tắt (Summarization): Biến lịch sử phiên thành một bản tóm tắt ngắn gọn hơn.
- Loại bỏ trùng lặp: Đảm bảo Agent không nhìn lại cùng một nội dung file nhiều lần một cách vô ích.
5. Bộ nhớ phiên làm việc có cấu trúc (Structured Session Memory)
Agent cần lưu trữ trạng thái để có thể tiếp tục làm việc khi khởi động lại. Có hai lớp lưu trữ:
- Full Transcript: Lưu trữ đầy đủ tất cả các yêu cầu, phản hồi và đầu ra công cụ. Đây là hồ sơ lịch sử để phục hồi phiên làm việc.
- Working Memory: Một phiên bản đã được tinh lọc, nhỏ gọn hơn, chứa các thông tin quan trọng nhất cần thiết cho nhiệm vụ hiện tại.
Sự phân biệt này giúp Agent duy trì tính liên tục của nhiệm vụ mà không bị bế tắc bởi dữ liệu quá nhiều.
6. Phân công nhiệm vụ với Subagent (Delegation with Bounded Subagents)
Một vấn đề lớn của AI là làm việc tuần tự (đợi xong việc này mới làm việc kia). Coding Agent có thể sử dụng "Subagent" để xử lý các tác vụ phụ song song hoặc độc lập.
Ví dụ: Khi Agent đang sửa lỗi, nó có thể gửi một subagent khác để tìm kiếm một hàm cụ thể trong kho mã nguồn. Điều này giúp tăng tốc độ xử lý. Tuy nhiên, subagent cần được giới hạn (bounded) – chỉ được phép truy cập một phạm vi cụ thể, thường ở chế độ chỉ đọc (read-only), để tránh xung đột và đảm bảo an toàn.
 Sơ đồ phân công Subagent
Sơ đồ phân công Subagent
Kết luận
Sự khác biệt giữa một Chatbot LLM đơn thuần và một Coding Agent chuyên nghiệp nằm ở hệ sinh thái xung quanh nó. Một Coding Agent hiệu quả không chỉ dựa vào "động cơ" mạnh mẽ (mô hình AI), mà còn nhờ vào khung phần mềm (harness) thông minh để quản lý ngữ cảnh, công cụ và bộ nhớ. Hiểu rõ sáu thành phần này là chìa khóa để xây dựng các công cụ AI thực sự hữu ích cho lập trình viên.
 Hệ thống Coding Agent
Hệ thống Coding Agent
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026