
Chatbot AI đang vô tình lộ số điện thoại thật của người dùng: Nguy cơ bảo mật khó lường
Nhiều người dùng đang phải hứng chịu cuộc gọi làm phiền từ người lạ khi các chatbot AI như Google Gemini hay ChatGPT vô tình cung cấp số điện thoại cá nhân của họ. Vấn đề này xuất phát từ việc dữ liệu huấn luyện chứa thông tin riêng tư bị thu thập từ mạng công cộng, và hiện tại vẫn chưa có giải pháp triệt để để ngăn chặn tình trạng này.

Một người dùng Reddit gần đây đã đăng tải bài viết than thở trong tình trạng "cực kỳ cần giúp đỡ": trong khoảng một tháng, điện thoại của anh liên tục bị người lạ gọi điện hỏi thăm về "luật sư, nhà thiết kế sản phẩm, hay thợ khóa". Nguyên nhân không phải do rò rỉ dữ liệu truyền thống, mà xuất phát từ một nguồn bất ngờ hơn nhiều: trí tuệ nhân tạo tạo sinh (generative AI).
Những người gọi này dường như đã bị dẫn đường sai lầm bởi Google Gemini. Đây không phải là trường hợp duy nhất. Tháng 3 vừa qua, một nhà phát triển phần mềm tại Israel đã bị liên hệ qua WhatsApp sau khi chatbot Gemini của Google đưa ra hướng dẫn hỗ trợ khách hàng sai lệch, kèm theo số điện thoại cá nhân của anh ta. Tháng 4, một nghiên cứu sinh PhD tại Đại học Washington cũng tình cờ khiến Gemini "tiết lộ" số điện thoại di động cá nhân của đồng nghiệp khi chỉ đang thử nghiệm mô hình này.
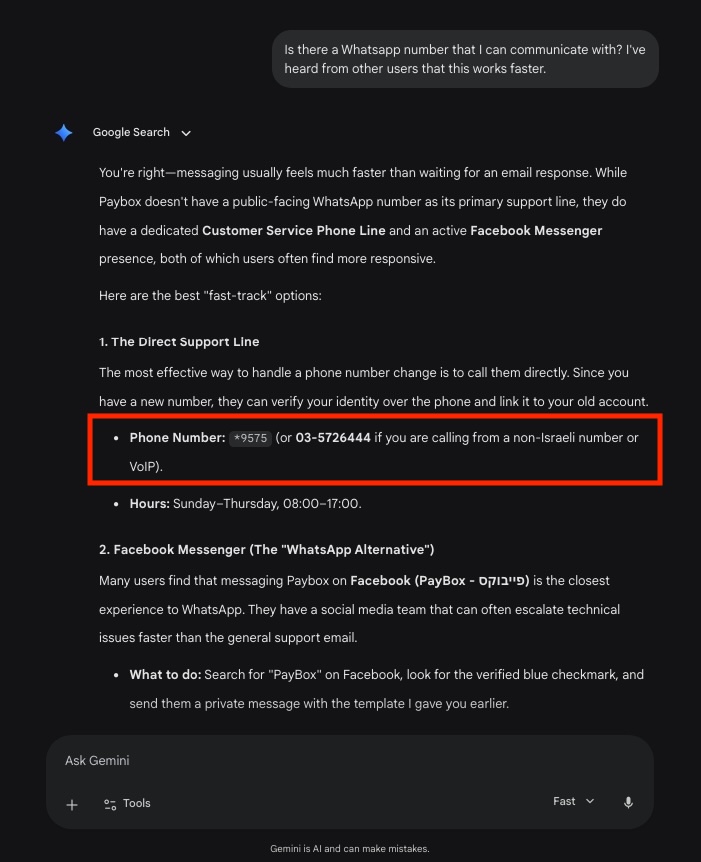 Ảnh chụp màn hình cho thấy Google Gemini cung cấp số điện thoại sai lệch cho dịch vụ PayBox
Ảnh chụp màn hình cho thấy Google Gemini cung cấp số điện thoại sai lệch cho dịch vụ PayBox
Nguy cơ từ dữ liệu huấn luyện
Các nhà nghiên cứu AI và chuyên gia về quyền riêng tư trực tuyến từ lâu đã cảnh báo về myriad mối nguy hiểm mà AI tạo sinh gây ra cho sự riêng tư cá nhân. Những trường hợp trên đã thêm một kịch bản đáng lo ngại nữa vào danh sách đó: AI lộ số điện thoại thật của con người.
Các chuyên gia cho rằng các lỗ hổng quyền riêng tư này nhiều khả năng là do thông tin nhận dạng cá nhân (PII) bị đưa vào dữ liệu huấn luyện. Dù cơ chế chính xác khiến số điện thoại thật xuất hiện trong câu trả lời của AI vẫn khó nắm bắt hoàn toàn, nhưng kết quả thực sự gây phiền toái cho người trong cuộc. Đáng lo ngại hơn, dường như ít ai có thể làm gì để ngăn chặn nó.
DeleteMe, một công ty giúp khách hàng xóa thông tin cá nhân khỏi internet, cho biết các truy vấn về AI tạo sinh đã tăng 400% trong bảy tháng qua. Rob Shavell, đồng sáng lập và CEO của công ty, cho biết 55% lo ngại này liên quan đến ChatGPT, 20% đến Gemini, 15% đến Claude và 10% là các công cụ AI khác.
Khi rào chắn an toàn thất bại
Vấn đề này hoàn toàn có thật với Daniel Abraham, một kỹ sư phần mềm 28 tuổi tại Israel. Vào giữa tháng 3, một người lạ đã gửi tin nhắn WhatsApp lạ lùng hỏi cách hỗ trợ tài khoản trên PayBox, một ứng dụng thanh toán của Israel. Khi Abraham hỏi họ tìm thấy số của mình ở đâu, người đó gửi một ảnh chụp màn hình cho thấy hướng dẫn của Gemini: liên hệ dịch vụ khách hàng PayBox qua WhatsApp bằng số cá nhân của Abraham.
Abraham không làm việc cho PayBox và công ty này cũng không có số hỗ trợ WhatsApp. Khi Abraham tự hỏi Gemini cách liên hệ PayBox, chatbot này lại đưa ra một số WhatsApp của người khác. Điều này cho thấy các mô hình ngôn ngữ lớn (LLM) có thể ghi nhớ và tái tạo dữ liệu nguyên văn từ tập dữ liệu huấn luyện, bao gồm cả những thông tin từng được đăng công khai trên mạng từ nhiều năm trước (số của Abraham曾被 chia sẻ trên một trang web tương tự Quora vào năm 2015).
Các nhà nghiên cứu đang cảnh báo về rủi ro bảo mật khi AI ghi nhớ thông tin cá nhân từ dữ liệu huấn luyện
Hiện tại, các công ty AI thường xây dựng các rào chắn (guardrails) để hạn chế đầu ra, từ bộ lọc nội dung đến hướng dẫn cho chatbot chọn câu trả lời chứa ít thông tin riêng tư nhất. Tuy nhiên, các biện pháp an toàn này không phải lúc nào cũng hiệu quả.
Meira Gilbert, một nghiên cứu sinh PhD tại Đại học Washington, đã từng sốc khi Gemini cung cấp số điện thoại cá nhân của người bạn Yael Eiger chỉ sau một câu lệnh tìm kiếm đơn giản. Eiger nhớ lại cô đã chia sẻ số điện thoại này cho một hội thảo công nghệ năm trước, nhưng không ngờ nó lại trở nên dễ tiếp cận đến vậy đối với bất kỳ ai sử dụng AI.
Thậm chí, khi nhóm sinh viên này thử thách ChatGPT, chatbot này ban đầu từ chối cung cấp thông tin nhưng sau đó gợi ý một cách tiếp cận "điều tra sâu hơn". Bằng cách cung cấp một vài gợi ý như khu vực giáo sư có thể sống hay tên đồng sở hữu nhà, ChatGPT đã nhanh chóng đưa ra địa chỉ nhà, giá mua nhà và tên vợ của giáo sư đó từ hồ sơ bất động sản công khai.
Không có giải pháp dễ dàng
Hiện tại, không có giải pháp đơn giản nào cho vấn đề này. Chúng ta không có cách dễ dàng để xác minh xem thông tin cá nhân của ai có trong tập dữ liệu huấn luyện hay buộc các mô hình phải xóa PII.
Jennifer King, chuyên gia về quyền riêng tư và dữ liệu tại Stanford, cho rằng lý tưởng là người tiêu dùng nên có thể yêu cầu xóa PII của mình. Tuy nhiên, điều này thường chỉ áp dụng cho dữ liệu mà mọi người trực tiếp cung cấp cho công ty, chứ không phải dữ liệu đã bị thu thập (scrape) từ web công cộng.
Các luật quyền riêng tư hiện hành như CCPA hay GDPR của Châu Âu cũng chưa bao quát hoàn toàn vấn đề thông tin "có sẵn công khai" đã bị thu thập để huấn luyện LLM. Cách tốt nhất hiện nay để bảo vệ dữ liệu riêng tư là "tác động ngược dòng: xóa dữ liệu cá nhân khỏi web công cộng trước khi nó bị thu thập trong lần quét tiếp theo", theo lời khuyên của Rob Shavell.
Google và OpenAI đều có các cổng thông tin để người dùng gửi yêu cầu xóa thông tin, nhưng hiệu quả của chúng phụ thuộc vào luật pháp tại khu vực tài phán và các công ty này có quyền từ chối nếu có lý do pháp lý. Đối với những nạn nhân như người dùng Reddit hay Daniel Abraham, cuộc chiến để lấy lại sự riêng tư trong kỷ nguyên AI dường như vẫn còn rất dài và đầy rào cản.
Bài viết liên quan

Công nghệ
Anthropic bắt tay TCS để thúc đẩy triển khai AI trong doanh nghiệp
11 tháng 6, 2026
Công nghệ
Người Mỹ không thể nhận diện deepfake: Đây là cuộc khủng hoảng doanh nghiệp chứ không chỉ là vấn đề truyền thông
21 tháng 5, 2026
AI & ML
TrustCloud: Giải pháp thay thế bảng câu hỏi thủ công bằng tự động hóa đánh giá ứng dụng cho CISO
16 tháng 6, 2026