
Đánh Giá 14 Engine OCR: Khi Nào Cần AI Tổng Quát, Khi Nên Dùng Mô Hình Chuyên Biệt?
Một nghiên cứu chi tiết so sánh hiệu suất của 14 công cụ OCR trên 93 tài liệu đã chỉ ra rằng không có giải pháp nào tối ưu cho mọi tình huống. Trong khi Tesseract vẫn là lựa chọn miễn phí và tốc độ cao cho tài liệu sạch, thì Gemini Flash lại nổi bật ở sự cân bằng, còn Mistral OCR là giải pháp kinh tế cho bảng biểu.
Chuyển đổi hình ảnh và tài liệu giấy sang văn bản máy (OCR) là một nhiệm vụ quan trọng nhưng cũng đầy thách thức. Các hóa đơn khách sạn cũ, sao kê ngân hàng, đơn vay vốn hay các biên bản tay viết thường xuyên gây khó khăn cho các hệ thống tự động.
Trước đây, các doanh nghiệp thường phải đối mặt với lựa chọn khó khăn giữa các công cụ miễn phí kém hiệu quả hoặc các API trả phí cao như AWS Textract Structured, với mức giá lên tới khoảng 65 USD cho mỗi 1.000 trang. Tuy nhiên, vài năm gần đây, bối cảnh đã thay đổi mạnh mẽ với sự xuất hiện của các mô hình thị giác mã nguồn mở chuyên dụng, các mô hình ngôn ngữ-ảnh (vision-language) đa năng và các công cụ phân tích tài liệu mới như LlamaParse.
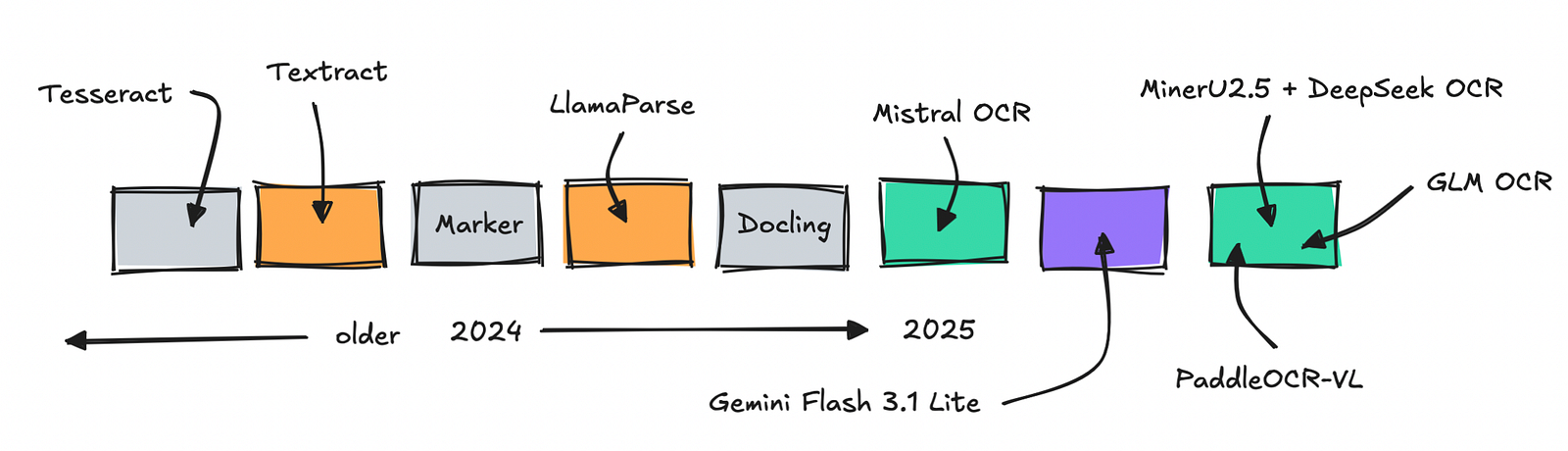 Dòng thời gian phát triển các giải pháp OCR sau năm 2024
Dòng thời gian phát triển các giải pháp OCR sau năm 2024
Để tìm ra câu trả lời cho câu hỏi "Liệu chúng ta có thực sự cần trả 65 USD cho 1.000 trang, hay có thể cắt giảm chi phí này?", tôi đã thực hiện một thí nghiệm quy mô nhỏ: chạy 14 engine OCR khác nhau trên 93 tài liệu đa dạng về độ khó.
Các engine và tài liệu tham gia thử nghiệm
Thí nghiệm bao gồm một danh sách đa dạng các engine: từ công cụ cổ điển như Tesseract, các pipeline phân tích tài liệu (Docling, Marker), các mô hình chuyên dụng mới nổi (GLM-OCR, PaddleOCR-VL, DeepSeek-OCR, MinerU), cho đến các "ông lớn" đa năng như Qwen3-VL, Gemini Flash 3.1 Lite, Claude Sonnet 4.6, và các dịch vụ đám mây như LlamaParse, AWS Textract, Mistral OCR.
Bộ dữ liệu thử nghiệm gồm 93 tài liệu được chia thành ba mức độ:
- Dễ: Hóa đơn và biên lai sạch sẽ (thuộc loại OCR đã giải quyết được từ lâu).
- Trung bình: Sao kê ngân hàng, phiếu thu, đơn vận chuyển, tờ khai thuế (từ bộ dữ liệu benchmark OmniAI OCR).
- Khó: Biểu đồ, mẫu đơn, ghi chú tay viết, bảng tài chính quét kém chất lượng, hồ sơ pháp lý và báo cáo cũ.
Kết quả: Không có engine nào là hoàn hảo
Tóm tắt nhanh (TL;DR): Không có một engine OCR duy nhất nào là tốt nhất cho mọi trường hợp. Về bản chất, đây là một bài toán đị tuyến (routing problem).
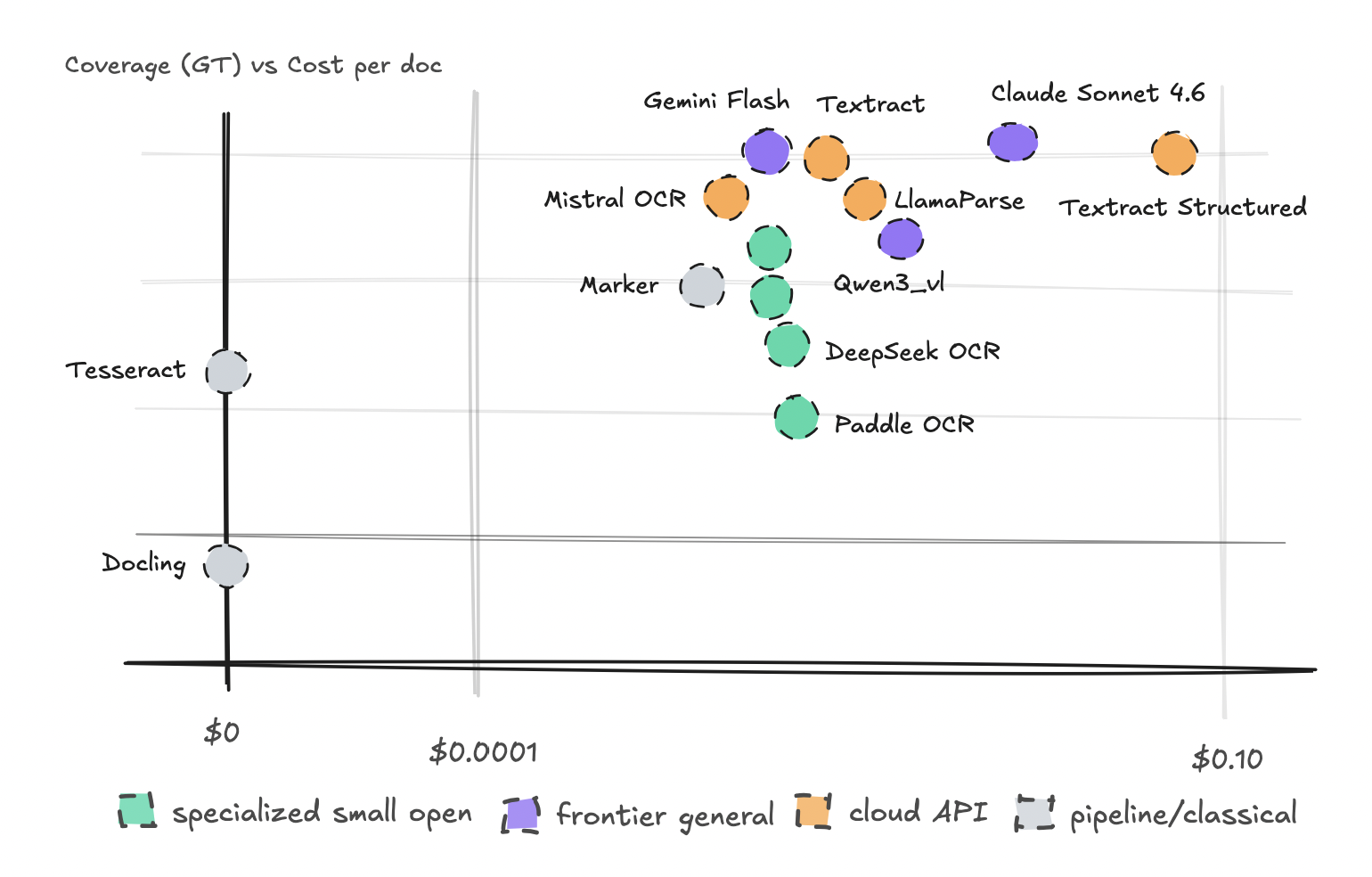
 Biểu đồ phân tán kết quả của các engine OCR
Biểu đồ phân tán kết quả của các engine OCR
Dưới đây là những điểm nhấn quan trọng từ thử nghiệm:
1. Tesseract vẫn là "vua" cho tài liệu sạch
Đối với các tài liệu PDF rõ ràng, phông chữ chuẩn và số lượng lớn, Tesseract (công cụ miễn phí, chạy cục bộ) vẫn rất khó bị đánh bại về mặt tốc độ và hiệu quả. Nó cực kỳ nhanh và nên là lựa chọn mặc định cho các trường hợp đơn giản.
2. Gemini Flash: Công cụ toàn diện tốt nhất
Trong thử nghiệm này, Gemini Flash 3.1 Lite đã thể hiện xuất sắc như một giải pháp "tất cả trong một". Nó xử lý tốt các loại tài liệu hỗn hợp trong môi trường sản xuất, vượt trội trên các biểu mẫu và ghi chú tay viết, thậm chí đánh bại cả Textract trên các tài liệu khó. Đây là lựa chọn cân bằng nhất nếu bạn muốn dùng một engine cho mọi nhu cầu.
3. Bảng biểu và cấu trúc: Mistral OCR là lựa chọn kinh tế
Khi cần trích xuất cấu trúc bảng (structured output), Mistral OCR cho thấy tiềm năng lớn với chi phí thấp hơn đáng kể so với các dịch vụ cao cấp như Textract Structured, nhưng vẫn duy trì độ chính xác cao.
4. Mô hình chuyên dụng có "vùng an toàn"
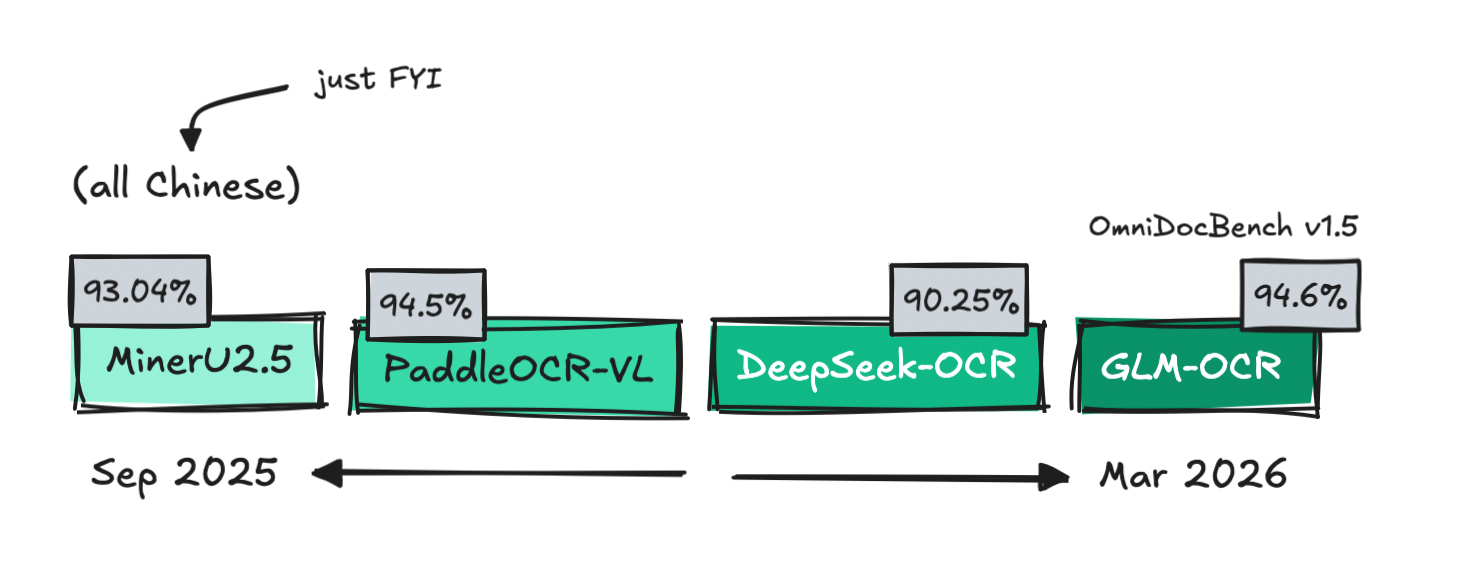
Các mô hình chuyên dụng nhỏ gọn (specialist models) hoạt động tốt trong môi trường quen thuộc, nhưng thường thất bại thảm hại khi gặp tài liệu lạ hoặc nằm ngoài tập huấn luyện của chúng. Điều này là do nhiều mô hình nhỏ có nguồn gốc từ Trung Quốc và có thể hoạt động không tốt trên tài liệu tiếng Anh hoặc các loại hình văn bản phương Tây lạ mắt.
Các mô hình chuyên dụng được phát hành trong năm qua (Ảnh: Tác giả)
 Các mô hình OCR chuyên dụng
Các mô hình OCR chuyên dụng
bài toán kinh tế và Đị tuyến tài liệu
Yếu tố quan trọng nhất rút ra từ thử nghiệm này nằm ở khía cạnh kinh tế. Đừng trả tiền cho OCR cấu trúc đắt đỏ nếu tài liệu của bạn không cần đến nó. Ví dụ, sử dụng Textract Structured cho mọi loại tài liệu có thể khiến bạn tốn tới 6.500 USD cho 100.000 tài liệu, trong khi phần lớn chúng có thể được xử lý miễn phí bằng Tesseract.
Chiến lược tối ưu được đề xuất:
- Invoices/Receipts sạch: Dùng Tesseract (miễn phí, nhanh).
- Tài liệu hỗn hợp trong sản xuất: Dùng Gemini Flash (cân bằng, chính xác).
- Cần bảng cấu trúc với chi phí thấp: Dùng Mistral OCR.
- Tài liệu quan trọng/phức tạp: Nâng cấp (escalate) lên Claude Sonnet hoặc các mô hình lớn hơn.
Những điểm đáng lưu ý khác
Đừng tin hoàn toàn vào Benchmark: Kết quả benchmark chỉ mang tính tham khảo. Cách duy nhất để biết engine nào hoạt động tốt với dữ liệu của bạn là tự chạy thử trên chính bộ tài liệu đó. OCR có tính đặc thù cao phụ thuộc vào bố cục, ngôn ngữ và chất lượng quét của từng tổ chức.
Các chế độ thất bại thú vị:
- PaddleOCR có vấn đề về lặp lại văn bản và thường chuyển sang mẫu giáo khoa tiếng Trung khi gặp lỗi.
- Docling gặp lỗi ghép ký tự, ghép từ và sai cột, gây bất ổn.
- Tesseract tạo ra rác (garbage text) khi gặp ảnh chụp hoặc chữ viết tay.
Kết luận
OCR không chỉ là việc chọn một engine tốt nhất, mà là việc xây dựng một quy trình thông minh. Hãy phân loại tài liệu của bạn, kiểm tra nhiều engine và thiết lập một bộ định tuyến (router) để chuyển tài liệu đến công cụ phù hợp nhất dựa trên chi phí, độ chính xác và yêu cầu cấu trúc.
Việc đầu tư thời gian vào việc đánh giá và thiết lập quy trình này có thể giúp doanh nghiệp tiết kiệm hàng nghìn USD mà vẫn đảm bảo chất lượng xử lý tài liệu.


