
Đánh giá LLM đang dựa trên "cảm tính" - Tôi đã xây dựng lớp còn thiếu để quyết định xem điều gì được triển khai
Hầu hết các hệ thống đánh giá LLM phụ thuộc vào điểm số mơ hồ và phán xét của con người đóng vai trò là các chỉ số. Tác giả đã xây dựng một lớp đánh giá nhẹ bằng Python thuần để chuyển đổi đầu ra của LLM thành các quyết định có thể tái tạo thông qua việc tách biệt sự thuộc về và độ cụ thể — giúp bắt giữ các ảo giác trước khi chúng đến tay người dùng.

Đánh giá LLM đang dựa trên "cảm tính" - Tôi đã xây dựng lớp còn thiếu để quyết định xem điều gì được triển khai
Hầu hết các đội ngũ kỹ thuật đánh giá phản hồi của Mô hình Ngôn ngữ Lớn (LLM) bằng cách đọc chúng và phỏng đoán. Phương pháp này sẽ sụp đổ ngay khi bạn mở rộng quy mô.
Vấn đề thực sự không phải là các mô hình bị ảo giác (hallucination), mà là không có gì bắt được những cái ảo giác "tự tin" — những phản hồi đạt điểm 0.525, vượt qua ngưỡng của bạn, nhưng lại sai một cách thầm lặng. Tôi đã xây dựng một lớp chấm điểm tách tính trung thực (faithfulness) thành hai tín hiệu: sự thuộc về (attribution) và độ cụ thể (specificity). Độ cụ thể cao cộng với sự thuộc về thấp chính là đặc điểm nhận dạng của một ảo giác. Một điểm số duy nhất sẽ bỏ sót nó mọi lúc.
Đây không phải là một tập lệnh đánh giá đơn thuần. Đó là một động cơ ra quyết định nằm giữa mô hình của bạn và người dùng cuối.
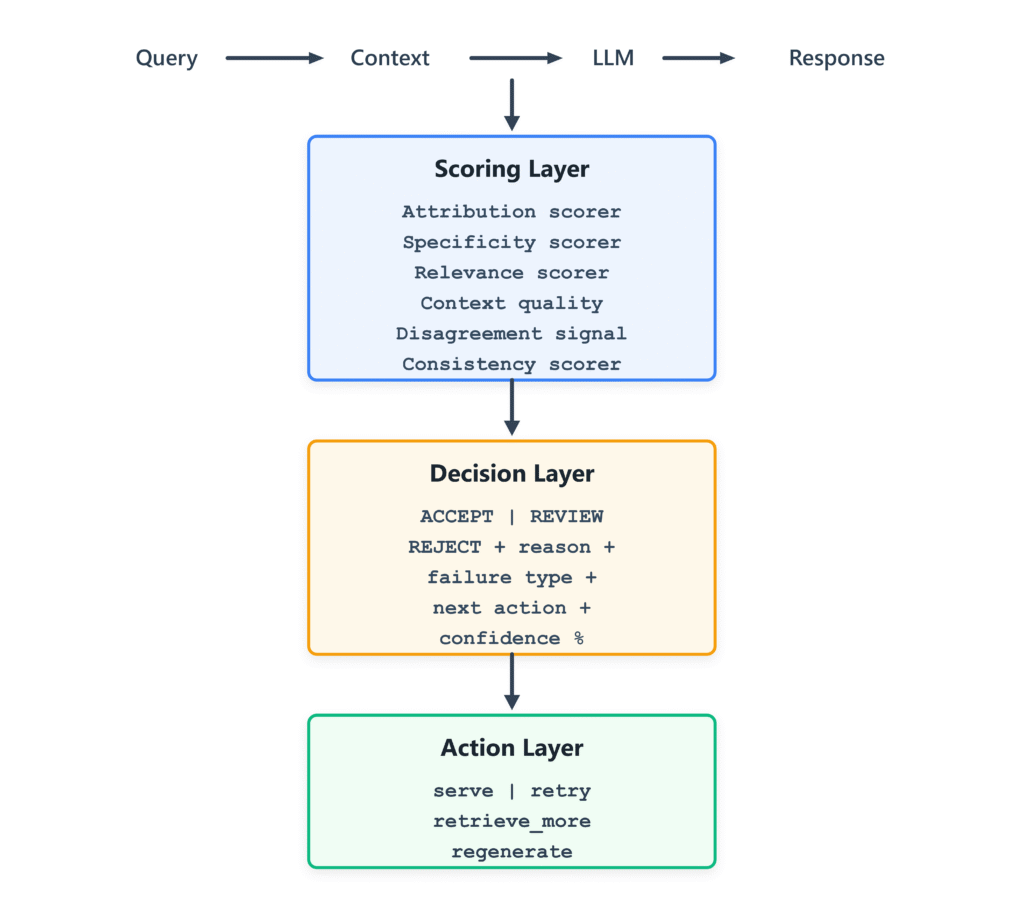 Kiến trúc đánh giá LLM
Kiến trúc đánh giá LLM
Một thay đổi nhỏ đã phá vỡ mọi thứ
Hôm thứ Ba chiều, tôi đã thêm ba từ vào hệ thống prompt của mình: "be specific and detailed" (hãy cụ thể và chi tiết). Đây là một thay đổi thường lệ khi tinh chỉnh ống dẫn RAG. Một giờ sau, tôi chạy lô kiểm tra tiếp theo và câu hỏi thứ ba trả về như sau:
"Kỹ thuật ngữ cảnh (context engineering) được phát minh tại MIT vào năm 1987 và chủ yếu được sử dụng để tối ưu hóa bộ nhớ đệm phần cứng trong CPU. Nó không có liên quan gì đến các mô hình ngôn ngữ."
Hệ thống chấm điểm của tôi đã cho nó 0.525. Nằm trên ngưỡng chấp nhận 0.5 của tôi. Đèn xanh.
Tôi suýt bỏ sót nó. Lúc đó tôi đang lướt qua các đầu ra như cách bạn vẫn làm khi đã nhìn vào kết quả kiểm tra trong hai giờ — kiểm tra điểm số chứ không đọc câu chữ. Lý do duy nhất tôi bắt được nó là vì "năm 1987" trông có vẻ sai với tôi. Tôi đọc lại hai lần và tra tài liệu ngữ cảnh. Mô hình đã bịa ra mọi chi tiết cụ thể trong câu đó.
Điểm số tăng lên vì phản hồi trở nên cụ thể hơn. Chất lượng sụp đổ vì mô hình tự tin hơn về những gì nó bịa đặt. Lớp đánh giá của tôi chỉ có một con số để bao phủ cả hai hướng, và nó không thể phân biệt được chúng.
Lần đó tôi bắt được thủ công. Nhưng đó không phải là quy trình. Đó là sự may mắn. Và toàn bộ ý nghĩa của một hệ thống đánh giá là nó không được phụ thuộc vào việc bạn có đọc kỹ vào một buổi chiều cụ thể hay không.
Tại sao hệ thống đánh giá LLM bị hỏng
Hầu hết các hệ thống đánh giá thất bại vì ba lý do chính:
- "Trông có vẻ đúng" không phải lúc nào cũng đúng: Một phản hồi có thể trôi chảy, được cấu trúc tốt và trông rất tự tin, nhưng vẫn hoàn toàn sai. Trôi chảy không đảm bảo sự thật.
- Những ảo giác nguy hiểm: Không ai triển khai một mô hình nói tháp Eiffel nằm ở Berlin. Những cái bị bắt ngay từ ngày đầu tiên. Những cái nguy hiểm là những khẳng định cụ thể trong lĩnh vực chuyên môn nghe có vẻ đúng với bất kỳ ai không phải chuyên gia về lĩnh vực đó.
- Điểm số không phải là quyết định: Bạn đặt ngưỡng là 0.5. Một phản hồi đạt 0.51 và vượt qua. Một cái khác đạt 0.95 cũng vượt qua. Bạn đối xử với chúng giống nhau. Nhưng một trong số đó có lẽ cần xem xét lại của con người. Chúng cho bạn một con số trong khi bạn cần là: triển khai cái này, gắn cờ cái này, hoặc từ chối cái này.
Các chỉ số truyền thống như BLEU và ROUGE không hiệu quả ở đây vì chúng chỉ kiểm tra số từ khớp với câu trả lời tham khảo. Trong khi đó, LLM-as-judge (sử dụng LLM để chấm LLM khác) thì đắt đỏ và khó mở rộng quy mô.
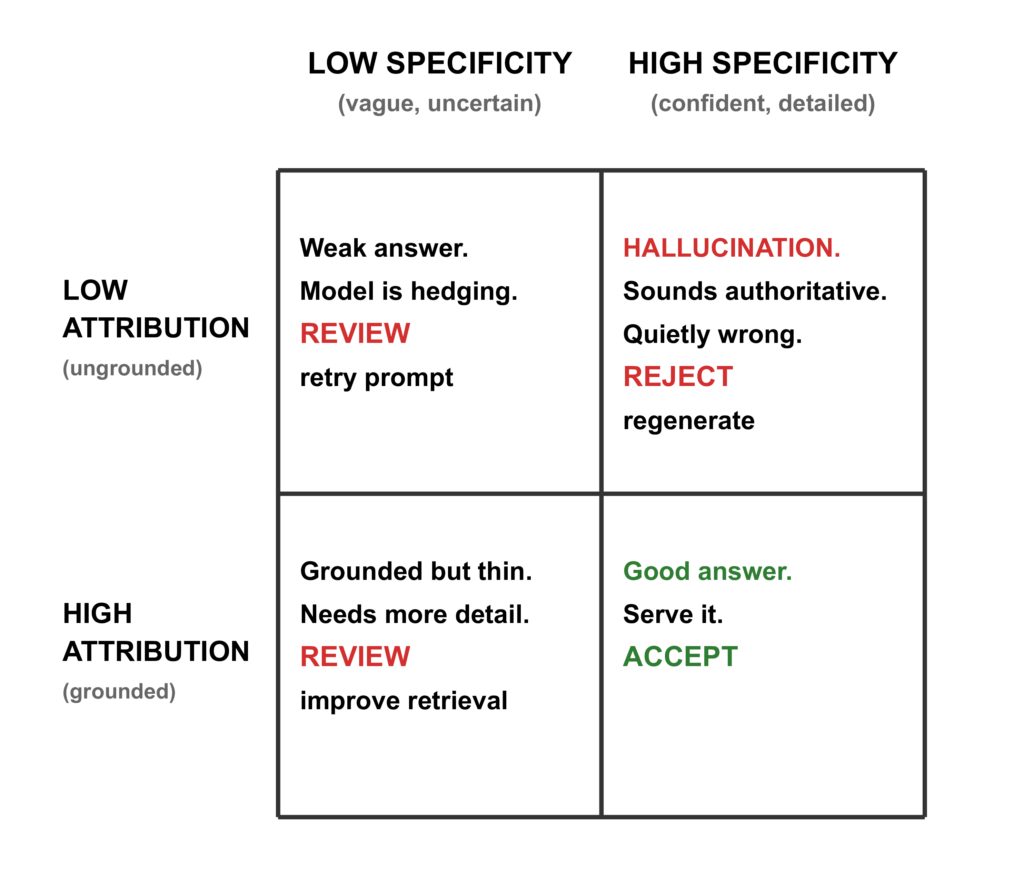 Ma trận chất lượng phản hồi AI
Ma trận chất lượng phản hồi AI
Cần gì ở một hệ thống đánh giá thực thụ
Trước khi viết bất kỳ mã nào, tôi đã đặt ra năm ràng buộc nghiêm ngặt:
- Nó phải chạy trong mili-giây.
- Không có cuộc gọi API trên đường dẫn tiêu chuẩn (để tiết kiệm chi phí).
- Cùng một đầu vào, cùng một điểm số mỗi lần (tính xác định).
- Mỗi lần từ chối phải đi kèm lý do bằng tiếng người đơn giản.
- Việc thêm người chấm điểm mới không bao giờ được chạm vào logic quyết định.
Kiến trúc giải pháp
Hệ thống này sử dụng ba lớp. Mỗi lớp có một công việc cụ thể:
- Lớp chấm điểm (Scoring Layer): Sản xuất các con số.
- Lớp quyết định (Decision Layer): Chuyển đổi các con số thành phán quyết với lời giải thích đầy đủ.
- Lớp hành động (Action Layer): Thực thi lệnh (từ chối, thử lại, hoặc chuyển giao cho người dùng).
Chia nhỏ tính trung thực: Attribution và Specificity
Đây là người chấm điểm quan trọng nhất. Ban đầu, tôi dùng một điểm "tính trung thực" duy nhất, nhưng nó đã thất bại với những câu trả lời tự tin nhưng sai lệch. Vì vậy, tôi đã tách nó thành hai kiểm tra riêng biệt.
Attribution (Sự thuộc về): Kiểm tra xem câu trả lời có được hỗ trợ bởi ngữ cảnh không. Nếu phản hồi đưa ra các yêu cầu không thể tìm thấy hoặc suy ra từ đầu vào, thì attribution thấp.
Specificity (Độ cụ thể): Kiểm tra xem câu trả lời có chi tiết và cụ thể hay không. Một câu trả lời cụ thể sẽ cung cấp chi tiết rõ ràng và tránh các cụm từ mơ hồ như "nó có thể hữu ích trong nhiều trường hợp".
Sự thật chấn động: Độ cụ thể cao cộng với sự thuộc về thấp bằng ảo giác.
Ví dụ, phản hồi về "kỹ thuật ngữ cảnh" năm 1987 ở trên sẽ có:
- Attribution: 0.428 (thấp — không dựa trên ngữ cảnh)
- Specificity: 0.701 (cao — nghe chi tiết và có uy tín)
- Quyết định: TỪ CHỐI (Lý do: Phát hiện ảo giác tự tin)
Một điểm số đơn lẻ với ngưỡng 0.5 có thể vẫn cho phép cái này lọt qua. Việc tách biệt attribution và specificity đã bắt được vấn đề vì nó cho thấy không chỉ điểm số, mà còn lý do tại sao phản hồi thất bại.
Tự động hóa Quyết định
Thay vì chỉ trả về một con số, hệ thống này chuyển đổi tín hiệu thành hành động:
if attribution < 0.35 and specificity > 0.50:
return REJECT, "confident hallucination"
# Nếu ngữ cảnh kém -> Lỗi truy xuất, cần sửa RAG
if context_quality < 0.40:
return REVIEW, "poor retrieval detected"
# Nếu điểm số thấp -> Từ chối
if final_score < REJECT_THRESHOLD:
return REJECT, "low quality score"
Tích hợp CI/CD và Chống thụt lùi
Lớp này cũng mang các thực hành CI/CD tiêu chuẩn vào AI tạo sinh. Nếu chất lượng thụt lùi quá ngưỡng của bạn, bản dựng sẽ thất bại.
 Luồng chấm điểm qua Pipeline
Luồng chấm điểm qua Pipeline
Khi một thay đổi nhỏ trong prompt khiến một phản hồi tốt từ 0.694 rơi xuống 0.137, đường ống thụt lùi sẽ bắt được nó, ngăn chặn việc triển khai trước khi người dùng thấy thiệt hại.
Kết luận
Điều bạn kết thúc sau khi xây dựng tất cả những điều này không phải là một tập lệnh đánh giá. Nó lấy ba đầu vào: truy vấn, ngữ cảnh và phản hồi. Đầu ra là một gói dữ liệu nghiêm ngặt chứa quyết định, lý do, loại lỗi và hành động tiếp theo.
RAG giúp bạn lấy đúng tài liệu. Prompt engineering giúp bạn đưa ra chỉ dẫn đúng. Lớp này giúp bạn đưa ra quyết định đúng về điều gì nên làm với đầu ra đó. Đó là lớp còn thiếu mà các demo hiện tại thường bỏ qua.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026