
DeepSeek mHC: Cuộc cách mạng hóa kiến trúc kết nối dư thừa đã cũ kỹ trong AI
DeepSeek-AI đã đề xuất kiến trúc mHC mới nhằm giải quyết các hạn chế của kết nối dư thừa truyền thống và sự bất ổn định của Hyper-Connections. Bằng cách kết hợp toán học ma trận kép ngẫu nhiên và tối ưu hóa phần cứng chuyên sâu, mHC mở rộng khả năng biểu diễn của mô hình mà không làm mất ổn định quá trình huấn luyện.
Trong suốt một thập kỷ qua, lĩnh vực học sâu (deep learning) đã tăng trưởng vượt bậc, từ công nghệ phần cứng đến sự sáng tạo trong các kiến trúc mô hình. Tuy nhiên, nếu nhìn sâu hơn, kiến trúc nền tảng vẫn giữ nguyên ở những khía cạnh then chốt. Chúng ta đã chứng kiến sự chuyển dịch lớn từ mạng tích chập (CNN) sang các kiến trúc Transformer quyền năng hiện nay, nhưng cách thức các mạng này định tuyến thông tin từ lớp này sang lớp khác thì hầu như không thay đổi.
Gần đây, các nhà nghiên cứu tại DeepSeek-AI đã công bố một bài báo có tên "mHC: Manifold-Constrained Hyper-Connections", đề xuất một thiết kế lại hoàn toàn hệ thống định tuyến này. Để hiểu rõ sự đột phá của giải pháp mới, hãy cùng xem xét sự tiến hóa của lan truyền tín hiệu và tại sao các phương pháp hiện tại đang gặp giới hạn.
 Minh họa về Kết nối Dư thừa (Residual Connection)
Minh họa về Kết nối Dư thừa (Residual Connection)
Xương sống của AI: Kết nối Dư thừa Chuẩn
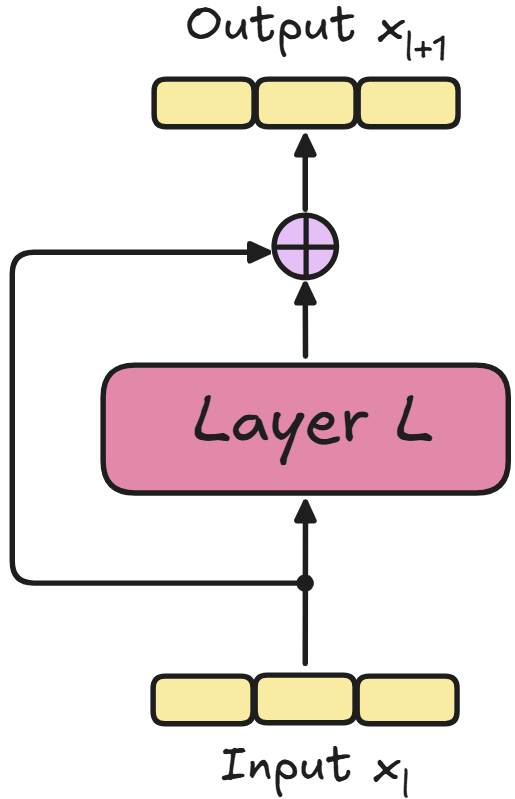
Để hiểu vấn đề, chúng ta cần quay về năm 2015 với sự ra đời của ResNets và Kết nối Dư thừa (Residual Connection). Đây được coi là một trong những lựa chọn thiết kế kiến trúc quan trọng nhất, hiện diện trong hầu hết mọi mô hình AI.
Về mặt toán học, kết nối dư thừa hoạt động theo nguyên tắc đầu ra của một lớp là tổng của đầu ra của lớp đó và đầu vào ban đầu: $x_{l+1} = x_l + F(x_l)$. Thành phần quan trọng ở đây là hạng mục $x_l$, được gọi là ánh xạ đồng nhất (identity mapping). Nó đóng vai trò như một con đường không bị gián đoạn để tín hiệu gradient lưu thông qua toàn bộ mạng. Chính tính chất này giúp ngăn chặn việc gradient biến mất hoặc bùng nổ, cho phép chúng ta huấn luyện thành công các mô hình với hàng trăm lớp.
Vấn đề của Kết nối Dư thừa và Siêu kết nối (Hyper-Connections)
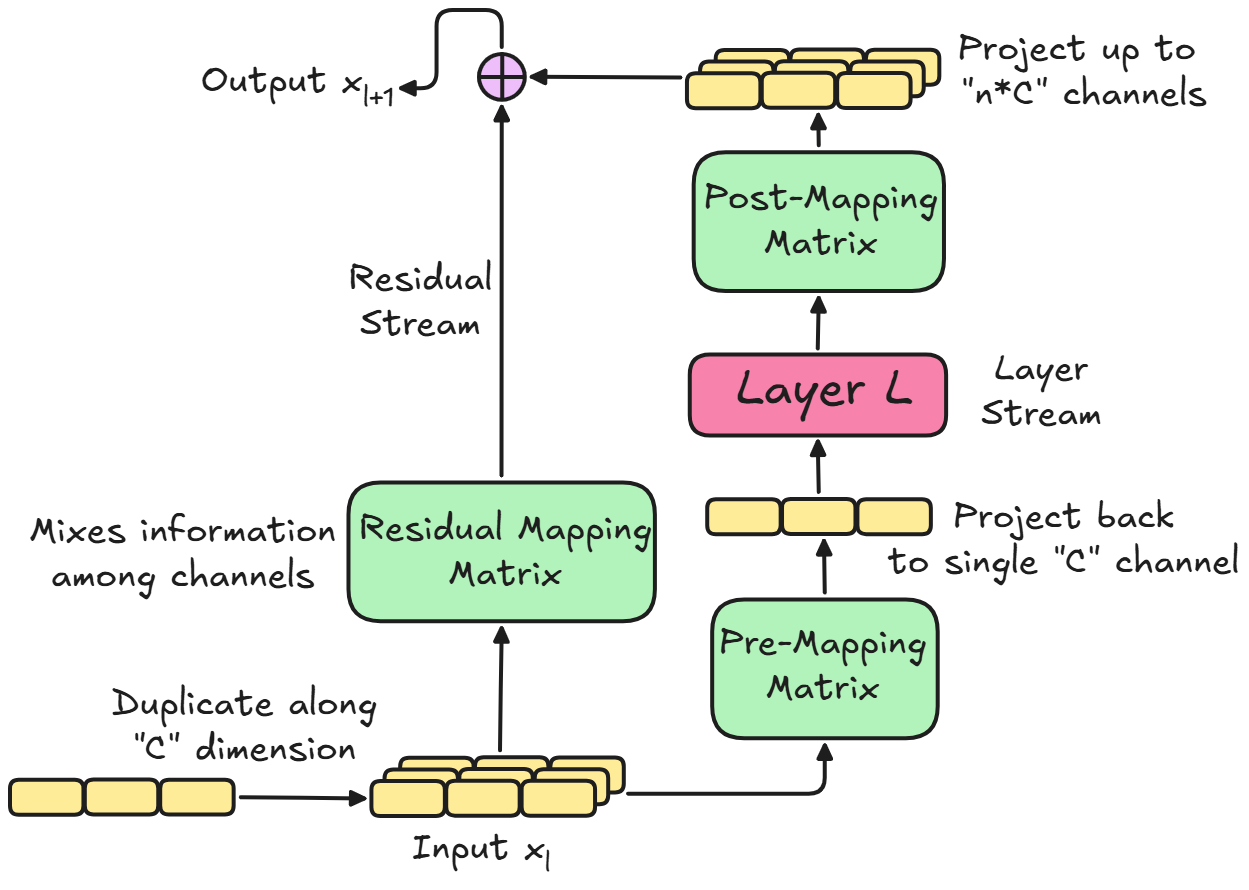
Khi các mô hình ngày càng khổng lồ, cách tiếp cận đơn giản này đang bộc lộ hạn chế. Trong một mô hình Transformer chuẩn, luồng dư thừa có chiều rộng cố định (gọi là C). Mọi ngữ cảnh, bộ nhớ và biểu diễn đặc trưng đều phải chen chúc vào vector C chiều này. Theo thời gian, khi các lớp mạng làm cho thông tin trở nên trừu tượng hơn, hạng mục $x_l$ trở thành "nút thắt cổ chai" thông tin.
Để giải quyết, các nhà nghiên cứu từ ByteDance đã giới thiệu Hyper-Connections (HC). Thay vì một luồng mỏng, HC mở rộng nó ra thành $n$ luồng song song, tạo ra tổng chiều rộng là $n \times C$. Mặc dù HC tăng cường khả năng biểu diễn, nhưng nó lại mang đến hai nhược điểm chí mạng khi mở rộng quy mô:
- Bất ổn định Toán học: Ma trận ánh xạ dư thừa trong HC phá vỡ tính chất ánh xạ đồng nhất, dẫn đến việc tín hiệu có thể bị khuếch đại theo cấp số nhân. DeepSeek phát hiện tín hiệu có thể bị phóng đại tới 3.000 lần, gây ra gradient thất thường.
- Nút thắt Phần cứng: Việc mở rộng luồng dữ liệu buộc phần cứng bộ nhớ phải đọc và ghi lượng dữ liệu khổng lồ tại mỗi bước, làm giảm hiệu suất huấn luyện và tăng đáng kể footprint của GPU.
Giải pháp: Manifold-Constrained Hyper-Connections (mHC)
Để giải quyết hai vấn đề lớn trên, đội ngũ DeepSeek đã đề xuất khung mHC (Manifold-Constrained Hyper-Connections). Giải pháp bao gồm hai phần: sửa lỗi toán học và tối ưu hóa hệ thống phần cứng.
Sửa lỗi Toán học: Đa diện Birkhoff
Sự đột phá về toán học nằm ở việc ép buộc ma trận ánh xạ dư thừa hoạt động trong một không gian toán học cụ thể gọi là đa diện Birkhoff. Nói một cách đơn giản, họ biến ma trận đó thành một ma trận kép ngẫu nhiên (doubly stochastic matrix).
Đây là loại ma trận mà tất cả các số đều không âm, và tổng của mỗi hàng bằng 1, cũng như tổng của mỗi cột bằng 1.
 Minh họa ma trận kép ngẫu nhiên
Minh họa ma trận kép ngẫu nhiên
Việc này mang lại ba lợi ích to lớn:
- Bảo toàn Chuẩn (Norm Preservation): Chuẩn phổ của ma trận này luôn bằng 1, nghĩa là nó không thể mở rộng hay làm giảm gradient, ngăn chặn vấn đề tín hiệu bùng nổ.
- Đóng gói Phối hợp (Compositional Closure): Khi nhân các ma trận này với nhau, kết quả vẫn là một ma trận kép ngẫu nhiên, đảm bảo sự ổn định qua hàng trăm lớp.
- Trộn hoàn hảo: Ma trận hoạt động như sự kết hợp của nhiều cách trộn thông tin khác nhau mà không làm tăng "năng lượng" của tín hiệu.
Để thực hiện điều này trong quá trình huấn luyện, họ sử dụng thuật toán Sinkhorn-Knopp để chuyển đổi ma trận thường thành ma trận kép ngẫu nhiên.
Sửa lỗi Phần cứng: Kỹ thuật Hệ thống Chuyên sâu
Việc chạy các luồng rộng và tính toán lặp lại Sinkhorn-Knopp là ác mộng với bộ nhớ GPU. DeepSeek đã áp dụng các tối ưu hóa hạ tầng mạnh mẽ:
- Hợp nhất Nhân (Kernel Fusion): Sử dụng framework TileLang để viết các nhân GPU tùy chỉnh, kết hợp phép nhân ma trận, chuẩn hóa và lặp Sinkhorn-Knopp thành một thao tác duy nhất, giảm thiểu truy cập bộ nhớ.
- Tính toán Lại Có chọn lọc: Họ loại bỏ dữ liệu trung gian sau khi chuyển tiếp và chỉ tính toán lại phần mHC nhẹ nhàng trong quá trình ngược (backward pass), giúp tiết kiệm bộ nhớ VRAM.
- Giao tiếp Chồng chéo: Trong hệ thống huấn luyện phân tán, họ ẩn độ trễ của việc truyền dữ liệu luồng rộng bằng cách chạy nó song song với các phép tính tốn kém của lớp attention.
Nhờ đó, mHC chỉ thêm khoảng 6,7% thời gian cho quá trình huấn luyện so với mô hình cơ sở.
Kết quả: Hiệu suất và Ổn định
Để kiểm chứng, DeepSeek đã huấn luyện các mô hình ngôn ngữ dựa trên kiến trúc DeepSeek-V3 với quy mô lên tới 27 tỷ tham số.
 Biểu đồ kết quả huấn luyện và hiệu suất
Biểu đồ kết quả huấn luyện và hiệu suất
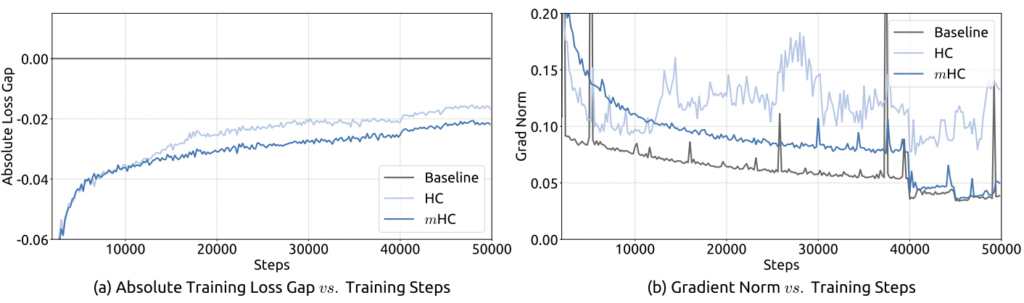
Khôi phục Ổn định Huấn luyện
Mô hình HC tiêu chuẩn bắt đầu mất ổn định gradient nghiêm trọng sau khoảng 12.000 bước. Ngược lại, mHC duy trì gradient mượt mà và đạt được mức mất mát (loss) huấn luyện thấp hơn đáng kể so với HC gốc.
Nâng cao Hiệu suất Downstream
Mô hình 27B sử dụng mHC cho thấy cải thiện hiệu suất nhất quán trên các benchmark như MATH, MMLU và các nhiệm vụ lý luận (BBH, DROP), vượt trội so với cả kết nối dư thừa chuẩn và HC không bị ràng buộc.
Tín hiệu Ổn định
Trong khi HC có thể khuếch đại tín hiệu lên gấp 3.000, mHC đã giới hạn mức tăng tín hiệu ở mức khoảng 1,6 trong suốt mô hình, chứng minh tính ổn định vượt trội của ma trận kép ngẫu nhiên.
Những đánh đổi và Thách thức
Mặc dù ấn tượng, mHC không phải không có nhược điểm:
- Chi phí thời gian 6,7%: Với các mô hình khổng lồ, mức tăng 6,7% thời gian huấn luyện tương đương với chi phí tài chính rất lớn.
- Độ phức tạp Kỹ thuật Cao: Việc triển khai mHC đòi hỏi phải viết nhân GPU tùy chỉnh và quản lý bộ nhớ thủ công, tạo ra rào cản lớn cho các nhóm nghiên cứu nhỏ không có kỹ sư hạ tầng chuyên biệt.
- Sự xấp xỉ Toán học: Thuật toán Sinkhorn-Knopp bị giới hạn ở 20 vòng lặp để đảm bảo tốc độ, khiến ma trận không hoàn hảo về mặt toán học. Điều này có thể gây ra vấn đề tiềm tàng với các mô hình lớn hơn 500 tỷ tham số trong tương lai.
Kết luận
Bài báo về mHC là một đầu tư nghiên cứu đáng kể từ DeepSeek, cho thấy rằng việc đẩy mạnh ranh giới của các mô hình nền tảng đòi hỏi sự kết hợp giữa toán học thuần túy và kỹ thuật hệ thống phần cứng.
Kết nối dư thừa chuẩn đã phục vụ AI tốt trong một thập kỷ, nhưng kỷ nguyên của các mô hình nghìn tỷ tham số đòi hỏi các con đường thông tin rộng hơn và phong phú hơn. DeepSeek đã chứng minh một cách khả thi để đạt được điều này. Mặc dù việc áp dụng rộng rãi có thể sẽ chậm do độ phức tạp kỹ thuật, nhưng rõ ràng các phòng lab AI lớn sẽ bắt đầu thử nghiệm mHC trong kiến trúc thế hệ tiếp theo của họ.
Bài viết liên quan

Phần mềm
Nvidia chính thức khai tử ứng dụng GeForce Control Panel sau 20 năm gắn bó
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026

Phần cứng
Cerebras khẳng định chip của họ chạy mô hình AI nghìn tham số nhanh hơn gấp 7 lần so với đám mây GPU
20 tháng 5, 2026