
Giá trị p thực sự có ý nghĩa gì trong Khoa học Dữ liệu?
Nhiều người lầm tưởng giá trị p là xác suất kết quả ngẫu nhiên, nhưng thực tế nó đo lường mức độ "kỳ lạ" của dữ liệu dưới giả thuyết không có sự khác biệt. Hiểu đúng khái niệm này là chìa khóa để tránh ra quyết định sai lầm trong A/B testing và phân tích dữ liệu.

Hãy thành thật một chút: với tư cách là một nhà khoa học dữ liệu, bạn đã từng trải qua tình huống này (thậm chí là nhiều lần). Đang nói chuyện chuyên môn, bỗng nhiên ai đó chặn ngang và hỏi bạn: "Giá trị p (p-value) thực sự có ý nghĩa gì?". Tôi cũng khá chắc chắn rằng câu trả lời của bạn lúc mới bắt đầu hành trình khoa học dữ liệu sẽ khác so với vài tháng sau đó, và lại khác nữa sau vài năm kinh nghiệm.
Nhưng điều tôi tò mò lúc này là, lần đầu tiên bị hỏi câu đó, bạn có thể đưa ra một câu trả lời gãy gọn và tự tin không? Hay bạn đã nói kiểu như: "Nó là... xác suất kết quả là ngẫu nhiên?" (kh nhất thiết phải đúng từng từ).
Sự thật là, bạn không đơn độc. Rất nhiều người sử dụng giá trị p thường xuyên nhưng thực ra không hiểu ý nghĩa thực sự của nó. Và công bằng mà nói, các lớp thống kê hay toán học chưa bao giờ làm việc này trở nên dễ dàng. Họ nhấn mạnh tầm quan trọng của giá trị p, nhưng lại không giải thích rõ ý nghĩa tương ứng với tầm quan trọng đó.
 Mô tả trực quan về p-value
Mô tả trực quan về p-value
Những lầm tưởng phổ biến về p-value
Đây là cách đa số mọi người nghĩ về giá trị p: Có 5% khả năng kết quả của tôi là do ngẫu nhiên, có 95% khả năng giả thuyết của tôi là đúng, hoặc phổ biến nhất là "giá trị p càng thấp = kết quả càng chính xác/tốt hơn".
Tuy nhiên, vấn đề là tất cả những điều này đều sai. Không chỉ sai một chút, mà là sai về bản chất căn bản. Và lý do nằm ở một điểm tinh tế: chúng ta đang đặt sai câu hỏi. Chúng ta cần biết cách đặt câu hỏi đúng vì việc hiểu rõ giá trị p rất quan trọng trong nhiều lĩnh vực:
- Kiểm thử A/B trong công nghệ: Quyết định xem một tính năng mới có thực sự cải thiện tương tác người dùng hay kết quả chỉ là nhiễu ngẫu nhiên.
- Y học và thử nghiệm lâm sàng: Xác định xem một liệu pháp có tác dụng thực sự so với giả dược hay không.
- Kinh tế và khoa học xã hội: Kiểm tra mối quan hệ giữa các biến số, như thu nhập và giáo dục.
- Tâm lý học: Đánh giá xem các hành vi hoặc can thiệp quan sát được có ý nghĩa thống kê hay không.
- Phân tích Marketing: Đo lường xem các chiến dịch có thực sự tác động đến tỷ lệ chuyển đổi hay không.
Trong tất cả các trường hợp này, mục tiêu là giống nhau: để figuring out xem những gì chúng ta thấy là tín hiệu... hay chỉ là sự may mắn giả vờ là ý nghĩa.
Vậy Giá trị p là gì?
Đã đến lúc trả lời câu hỏi này. Cách đơn giản nhất để nghĩ về nó là:
Giá trị p đo lường dữ liệu của bạn có đáng ngạc nhiên đến mức nào nếu không có gì thực sự xảy ra.
Hoặc thậm chí còn đơn giản hơn:
"Nếu mọi thứ chỉ là ngẫu nhiên... thì thứ tôi vừa thấy kỳ lạ đến mức nào?"
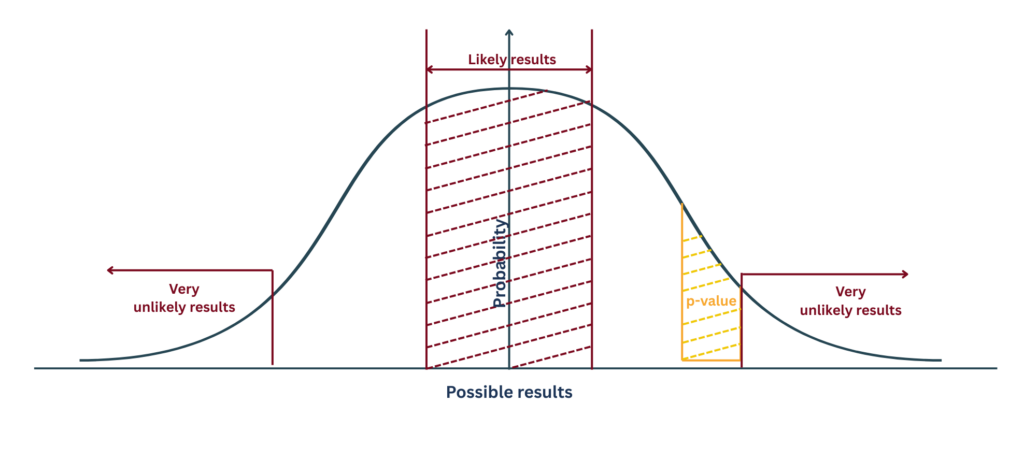
Hãy tưởng tượng dữ liệu của bạn nằm trên một phổ kết quả. Hầu hết thời gian, nếu không có gì xảy ra, kết quả của bạn sẽ dao động quanh vùng "không có sự khác biệt". Nhưng đôi khi, tính ngẫu nhiên tạo ra những kết quả kỳ lạ.
Nếu kết quả của bạn rơi xa ở phần đuôi của phổ phân phối, bạn sẽ tự hỏi:
"Tần suất tôi gặp phải một trường hợp cực đoan như thế này chỉ dựa vào may mắn là bao nhiêu?"
Xác suất đó chính là giá trị p của bạn.
Ví dụ về tiệm bánh
Hãy thử mô tả điều đó bằng một ví dụ cụ thể. Hãy tưởng tượng bạn điều hành một tiệm bánh nhỏ. Bạn đã tạo ra một công thức làm bánh quy mới và nghĩ rằng nó ngon hơn công thức cũ. Nhưng là một người làm kinh doanh thông minh, bạn cần dữ liệu để hỗ trợ giả thuyết đó. Vì vậy, bạn thực hiện một bài kiểm tra đơn giản:
- Cho 100 khách hàng nếm bánh quy cũ.
- Cho 100 khách hàng nếm bánh quy mới.
- Hỏi: "Bạn có thích cái này không?"
Kết quả bạn quan sát được:
- Bánh quy cũ: 52% thích.
- Bánh quy mới: 60% thích.
Tuyệt vời, cái mới có điểm đánh giá của khách hàng tốt hơn! Hay là vậy?
 Quy trình suy luận thống kê
Quy trình suy luận thống kê
Đây là where things get slightly tricky: "Liệu công thức bánh quy mới thực sự tốt hơn... hay tôi chỉ may mắn khi chọn được nhóm khách hàng này?". Giá trị p sẽ giúp chúng ta trả lời câu hỏi đó!
Bước 1: Giả định Không có gì xảy ra
Bạn bắt đầu với giả thuyết không (null hypothesis): "Không có sự khác biệt thực sự nào giữa hai loại bánh." Nói cách khác, cả hai bánh đều ngon như nhau, và bất kỳ sự khác biệt nào chúng ta thấy chỉ là sự biến thiên ngẫu nhiên.
Bước 2: Mô phỏng một "Thế giới Ngẫu nhiên"
Bây giờ hãy tưởng tượng việc lặp lại thí nghiệm này hàng nghìn lần: nếu hai loại bánh thực sự giống hệt nhau, đôi khi nhóm này sẽ thích chúng hơn, đôi khi là nhóm kia. Rốt cuộc, đó chính là cách mà sự ngẫu nhiên hoạt động.
Thay vì dùng công thức toán học, chúng ta đang làm điều gì đó rất trực giác: giả định cả hai bánh đều ngon như nhau, mô phỏng hàng nghìn thử nghiệm dưới giả định đó, rồi hỏi:
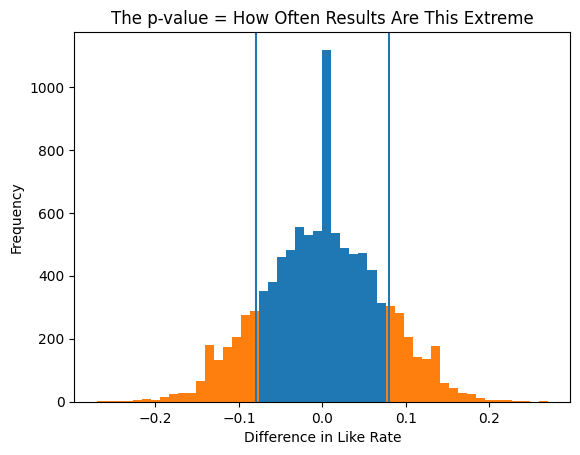
"Tần suất tôi thấy sự khác biệt lớn như 8% chỉ dựa vào may mắn là bao nhiêu?"
Theo code mô phỏng, giá trị p = 0.2.
Điều này có nghĩa là nếu hai loại bánh thực sự giống nhau, tôi sẽ thấy sự khác biệt lớn như vậy khoảng 20% thời gian. Tăng số lượng khách hàng được nếm thử sẽ thay đổi đáng kể giá trị p đó.
Hãy lưu ý rằng chúng ta không cần chứng minh bánh mới ngon hơn; thay vào đó, dựa trên dữ liệu, chúng ta kết luận rằng "Kết quả này sẽ khá kỳ lạ nếu không có gì đặc biệt xảy ra". Điều đó đủ để làm chúng ta bắt đầu nghi ngờ về giả thuyết không.
Điều thường bị bỏ sót
Đây là phần khiến mọi người vấp ngã (bao gồm cả tôi khi lần đầu học thống kê). Giá trị p trả lời câu hỏi này:
"Nếu giả thuyết không đúng, thì dữ liệu này có khả năng bao nhiêu?"
Nhưng điều chúng ta muốn biết là:
"Cứ dựa vào dữ liệu này, thì giả thuyết của tôi có khả năng đúng bao nhiêu?"
Hai câu hỏi này không giống nhau. Nó giống như việc hỏi: "Nếu trời mưa, thì khả năng tôi thấy đường ướt là bao nhiêu?" so với "Nếu tôi thấy đường ướt, thì khả năng trời đang mưa là bao nhiêu?".
Vì bộ não chúng ta hoạt động theo chiều ngược lại, khi thấy dữ liệu, chúng ta muốn suy ra sự thật. Nhưng giá trị p hoạt động ngược lại: Giả định một thế giới -> đánh giá xem dữ liệu của bạn kỳ lạ đến mức nào trong thế giới đó.
Vì vậy, thay vì nghĩ: "p = 0.03 nghĩa là có 3% khả năng tôi sai", chúng ta nên nghĩ: "Nếu không có gì thực sự xảy ra, tôi chỉ thấy một điều cực đoan như vậy 3% thời gian thôi".
Chỉ có vậy thôi! Không đề cập gì đến sự thật hay tính đúng đắn.
Tại sao việc hiểu giá trị p lại quan trọng?
Hiểu sai ý nghĩa của giá trị p dẫn đến các vấn đề thực sự khi bạn cố gắng hiểu hành vi của dữ liệu.
- Tự tin sai lầm: Mọi người nghĩ rằng "p < 0.05 -> nó là đúng". Điều đó không chính xác; nó chỉ có nghĩa là "không thể xảy ra dưới giả thuyết không".
- Phản ứng thái quá với tiếng ồn: Một giá trị p nhỏ vẫn có thể xảy ra do ngẫu nhiên, đặc biệt nếu bạn chạy nhiều bài kiểm tra.
- Bỏ qua quy mô hiệu ứng: Một kết quả có thể có ý nghĩa thống kê, nhưng không có ý nghĩa thực tế. Ví dụ, cải thiện 0.1% với p < 0.01 có thể về mặt kỹ thuật là "có ý nghĩa", nhưng thực tế thì vô dụng.
Hãy coi giá trị p như một "điểm độ kỳ lạ".
- Giá trị p cao -> "Trông này bình thường."
- Giá trị p thấp -> "Trông này kỳ lạ."
Và dữ liệu kỳ lạ khiến bạn đặt câu hỏi về các giả định của mình. Đó chính là tất cả những gì kiểm tra giả thuyết đang làm.
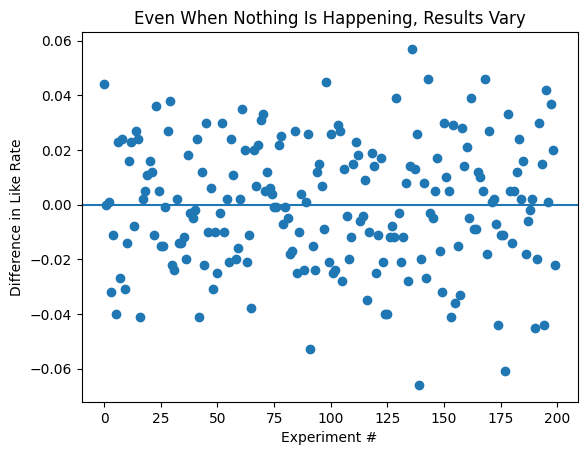
Tại sao 0.05 lại là con số ma thuật?
Tại một thời điểm nào đó, bạn chắc chắn đã thấy quy tắc này:
"Nếu p < 0.05, kết quả có ý nghĩa thống kê."
 Phân phối và ngưỡng p-value
Phân phối và ngưỡng p-value
Ngưỡng 0.05 trở nên phổ biến nhờ Ronald Fisher, một trong những nhân vật tiên phong của thống kê hiện đại. Ông đã đề xuất 5% như một mức cắt hợp lý khi các kết quả bắt đầu trông "hiếm gặp đủ" để đặt câu hỏi về giả định tính ngẫu nhiên.
Không phải vì nó tối ưu về mặt toán học hay đúng theo cách phổ quát, mà chỉ đơn giản là vì nó... thực tế. Theo thời gian, nó trở thành mặc định. p < 0.05 có nghĩa là nếu không có gì xảy ra, tôi sẽ thấy một điều cực đoan như vậy ít hơn 5% thời gian.
Việc chọn 0.05 là để cân bằng hai loại sai lầm:
- Dương tính giả (False positives): Nghĩ là có chuyện gì đó xảy ra trong khi thực ra không.
- Âm tính giả (False negatives): Bỏ lỡ một tác động thực sự.
Nếu bạn làm ngưỡng chặt hơn (ví dụ, 0.01), bạn giảm báo động giả, nhưng bỏ lỡ nhiều tác động thực sự. Mặt khác, nếu bạn nới lỏng nó (ví dụ, 0.10), bạn bắt được nhiều tác động thực sự, nhưng rủi ro gặp nhiều tiếng ồn hơn. Vì vậy, 0.05 nằm ở somewhere in the middle.
Bài học cốt lõi
Nếu bạn chỉ rút đi một điều từ bài viết này, hãy để nó là: giá trị p không cho bạn biết giả thuyết của bạn là đúng; nó cũng không cho bạn xác suất bạn sai! Nó cho bạn biết dữ liệu của bạn đáng ngạc nhiên đến mức nào dưới giả định là không có tác động nào cả.
Lý do hầu hết mọi người bị nhầm lẫn về giá trị p lúc đầu không phải vì giá trị phức tạp, mà vì chúng thường được giải thích ngược. Vì vậy, thay vì hỏi: "Tôi có vượt qua 0.05 không?", hãy hỏi: "Kết quả này kỳ lạ đến mức nào?".
Và để trả lời câu hỏi đó, bạn cần nghĩ về giá trị p như một phổ:
- 0.4 -> hoàn toàn bình thường.
- 0.1 -> hơi thú vị.
- 0.03 -> hơi ngạc nhiên.
- 0.001 -> rất ngạc nhiên.
Nó không phải là một công tắc nhị phân (bật/tắt); mà là một dải bằng chứng.
Một khi bạn chuyển tư duy từ "Điều này có đúng không?" sang "Điều này sẽ kỳ lạ đến mức nào nếu không có gì xảy ra?", mọi thứ sẽ bắt đầu khớp với nhau. Và quan trọng hơn, bạn sẽ bắt đầu đưa ra các quyết định tốt hơn với dữ liệu của mình.
Bài viết liên quan

Công nghệ
NASA yêu cầu phi hành gia trú ẩn trong tàu SpaceX Dragon do rò rỉ tại ISS
05 tháng 6, 2026

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026

Công nghệ
Tính năng Tìm kiếm Tệp trong Gemini API giờ đã hỗ trợ Đa phương thức: Xây dựng RAG hiệu quả và có thể kiểm chứng
10 tháng 5, 2026