
Giảm chi phí API và tối ưu hóa Token trong GitHub Agentic Workflows
Các quy trình làm việc tác nhân (Agentic Workflows) chạy trên mỗi pull request có thể âm thầm gây tốn kém chi phí API. Bài viết này chia sẻ cách GitHub đã đo lường, phát hiện điểm lãng phí và xây dựng các tác nhân tự động để tối ưu hóa việc sử dụng token, giúp tiết kiệm đáng kể chi phí vận hành.

GitHub Agentic Workflows hoạt động giống như một đội ngũ vệ sinh đường phố, dọn dẹp những lộn xộn nhỏ trong kho lưu trữ mã nguồn (repo) của bạn. Những đội ngũ này giúp cải thiện đáng kể sự sạch sẽ và chất lượng của repo, nhưng giống như mọi công việc dựa trên tác nhân AI, chi phí luôn là mối lo ngại ngày càng tăng đối với các nhà phát triển. Vì các tác vụ CI như agentic workflows được lên lịch và kích hoạt tự động, chi phí có thể tích lũy mà không để lại dấu hiệu rõ ràng.
May mắn thay, việc làm cho các quy trình tự động hóa hiệu quả hơn dễ dàng hơn nhiều so với các phiên làm việc tương tác trên máy tính để bàn. Công việc trong phiên của nhà phát triển có thể khó dự đoán, nhưng công việc của agentic workflows được quy định hoàn toàn trong YAML và lặp lại ở mỗi lần thực thi.
Vì chúng tôi duy trì và sử dụng GitHub Agentic Workflows trong các kho lưu trữ của chính mình, chúng tôi cũng quan tâm đến hiệu quả sử dụng token giống như người dùng. Đó là lý do vào tháng 4 năm 2026, chúng tôi bắt đầu tối ưu hóa có hệ thống việc sử dụng token cho nhiều quy trình mà chúng tôi dựa vào mỗi ngày. Bài viết này mô tả những gì chúng tôi đã đo lường, các tối ưu hóa chúng tôi áp dụng và kết quả sơ bộ của chúng tôi.
Ghi nhật ký việc sử dụng Token
Chúng tôi dựa vào hàng trăm agentic workflows trong các repo để bảo trì và CI. Tất cả các quy trình này chạy dưới dạng GitHub Actions với các giới hạn tốc độ API thực. Chúng tôi đang chế tạo máy bay trong khi bay và đốt nhiên liệu trên đường đi.
Trước khi có thể tối ưu hóa mức tiêu thụ token, chúng tôi cần biết token được tiêu thụ như thế nào. Thách thức đầu tiên chúng tôi gặp phải là mỗi khung tác nhân (Claude CLI, Copilot CLI, Codex CLI) lại phát ra nhật ký ở định dạng khác nhau và dữ liệu sử dụng có thể không đầy đủ cho các lần chạy trong quá khứ. May mắn thay, kiến trúc bảo mật của agentic-workflows sử dụng một proxy API để ngăn các tác nhân truy cập trực tiếp vào thông tin xác thực. Proxy này đã cung cấp cho chúng tôi một cách để ghi lại việc sử dụng token trên tất cả các lần chạy ở một định dạng chuẩn hóa duy nhất, bất kể khung tác nhân nào.
 Biểu đồ minh họa việc sử dụng token
Biểu đồ minh họa việc sử dụng token
Giờ đây, mọi quy trình đều xuất ra một tạo phẩm token-usage.jsonl với một bản ghi cho mỗi lệnh gọi API chứa các thông tin như input tokens, output tokens, cache-read tokens, cache-write tokens, model, provider và dấu thời gian. Kết hợp dữ liệu này với phần còn lại của nhật ký của quy trình đã mang lại cái nhìn lịch sử về cách token thường được chi tiêu và cho phép chúng tôi tối ưu hóa cho các lần chạy trong tương lai.
Các quy trình tối ưu hóa chính nó
Với dữ liệu token trong tay, chúng tôi đã xây dựng hai quy trình tối ưu hóa hàng ngày.
Một Daily Token Usage Auditor (Kiểm toán viên sử dụng Token hàng ngày) sẽ đọc các tạo phẩm sử dụng token từ các lần chạy quy trình gần đây, tổng hợp mức tiêu thụ theo quy trình và đăng một báo cáo có cấu trúc. Nhiệm vụ của nó là gắn cờ bất kỳ quy trình nào có mức sử dụng gần đây tăng đáng kể, làm nổi bật các quy trình tốn kém nhất và ghi chú các lần chạy bất thường (ví dụ: một quy trình thường hoàn thành trong 4 lượt LLM nhưng lại mất đến 18 lượt).
Khi Auditor gắn cờ một quy trình, một Daily Token Optimizer (Trình tối ưu hóa Token hàng ngày) sẽ xem xét mã nguồn và nhật ký gần đây của quy trình đó để tạo một vấn đề trên GitHub (GitHub issue) mô tả các sự không hiệu quả cụ thể và đề xuất các tối ưu hóa cụ thể. Optimizer đã tìm thấy nhiều sự không hiệu quả mà nếu không có nó chúng tôi đã bỏ lỡ.
Tất nhiên, cả Auditor và Optimizer đều là các agentic workflows, và việc sử dụng token của chúng cũng xuất hiện trong các báo cáo hàng ngày để tạo ra một vòng luân phiên nhỏ tích cực.
Loại bỏ các công cụ MCP không sử dụng
Dựa trên kết quả ban đầu của Auditor và Optimizer, sự không hiệu quả phổ biến nhất là đăng ký công cụ MCP (Model Context Protocol) không được sử dụng.
Vì các API LLM là không trạng thái (stateless), thời gian chạy tác nhân thường bao gồm tên hàm công cụ MCP và lược đồ JSON với mỗi yêu cầu. Trong thực tế, điều này có nghĩa là toàn bộ bộ công cụ có thể trở thành một phần của ngữ cảnh của mọi lệnh gọi. Đối với một máy chủ GitHub MCP với 40 công cụ, điều này có thể thêm 10–15 KB lược đồ cho mỗi lượt. Nếu tác nhân chỉ sử dụng hai công cụ, 38 công cụ còn lại là chi phí dư thừa được thêm vào mọi yêu cầu.
Các tác giả quy trình tự nhiên bắt đầu với một bộ công cụ đầy đủ vì đó là con đường ít kháng cự nhất, và tác nhân có thể tự tìm ra những công cụ nào nó cần. Nhưng theo thời gian, hầu hết các quy trình dựa vào một bộ công cụ hẹp và ổn định. Optimizer xác định mô hình này bằng cách đối chiếu tệp kê khai công cụ với các lệnh gọi công cụ thực tế và đề xuất cắt bỏ các công cụ không sử dụng khỏi cấu hình.
Trong các quy trình kiểm tra khói (smoke-test) của chúng tôi, việc loại bỏ các công cụ không sử dụng khỏi cấu hình MCP đã giảm kích thước ngữ cảnh mỗi lệnh gọi xuống 8–12 KB, tiết kiệm hàng nghìn token cho mỗi lần chạy mà không làm thay đổi hành vi.
Thay thế GitHub MCP bằng GitHub CLI
Loại bỏ các công cụ MCP không sử dụng là một chiến thắng tương đối đơn giản. Một cơ hội cấu trúc lớn hơn là thay thế các lệnh gọi GitHub MCP cho các thao tác tìm nạp dữ liệu như lấy diff pull request, nội dung tệp và nhận xét xét duyệt bằng các lệnh gọi đến GitHub CLI.
Thay đổi này làm được nhiều hơn là giảm chi phí dư thừa của các công cụ không sử dụng vì một lệnh gọi công cụ MCP là một bước suy luận (reasoning step) ngoài việc tìm nạp dữ liệu. Tác nhân phải quyết định gọi công cụ, xây dựng các đối số của nó và nhận đầu ra của nó như một phần của ngữ cảnh. Đó là một lượt gọi API LLM khứ hồi hoàn chỉnh, tiêu thụ token cho lược đồ JSON sử dụng công cụ, khối đối số và phản hồi. Ngược lại, việc gọi gh pr diff là một yêu cầu HTTP xác định đến API REST của GitHub mà không có sự tham gia của LLM.
Chúng tôi đã sử dụng hai chiến lược cho việc chuyển đổi này:
- Tải xuống dữ liệu trước tác nhân (Pre-agentic data downloads): Đối với dữ liệu mà tác nhân luôn cần như diff pull request hoặc danh sách các tệp đã thay đổi, chúng tôi thêm các bước thiết lập trong quy trình chạy các lệnh gh trước khi tác nhân bắt đầu và ghi kết quả vào các tệp không gian làm việc. Tác nhân đọc các tệp đó thay vì thực hiện các lệnh gọi MCP. Điều này loại bỏ chi phí gọi công cụ và cho phép tác nhân tận dụng việc đào tạo rộng rãi về bash scripting để xử lý dữ liệu hiệu quả.
- Thay thế proxy CLI trong tác nhân (In-agent CLI proxy substitution): Việc tải trước không thể thực hiện được trong các trường hợp tác nhân xác định những gì cần tìm nạp tại thời điểm chạy. Trong những trường hợp này, chúng tôi dựa vào một proxy HTTP minh bạch nhẹ định tuyến lưu lượng truy cập CLI đến máy chủ API của GitHub mà không lộ mã thông báo xác thực cho tác nhân. Tác nhân chạy
gh pr view –jsonvà nhận lại dữ liệu có cấu trúc, giống như người dùng làm từ thiết bị đầu cuối. Điều này làm giảm việc sử dụng token mà không làm ảnh hưởng đến yêu cầu bảo mật "zero-secrets" của chúng tôi.
Cùng nhau, các kỹ thuật này di chuyển phần lớn việc tìm nạp dữ liệu GitHub ra khỏi vòng lặp suy luận LLM.
Đo lường mức tăng hiệu quả không dễ dàng
Khi chúng tôi bắt đầu tối ưu hóa các quy trình của mình, chúng tôi gặp phải một vấn đề tinh tế hơn: làm sao bạn biết liệu một thay đổi đã làm cho mọi thứ hiệu quả hơn, hay chỉ làm cho quy trình làm ít công việc hơn (và có thể tệ hơn)?
Có ba yếu tố gây nhiễu:
- Không phải mọi token đều được tạo ra như nhau: Chạy cùng một quy trình trên Claude Haiku so với Claude Sonnet tạo ra số lượng token tương tự nhưng chi phí rất khác nhau. Haiku rẻ hơn khoảng 4 lần mỗi token so với Sonnet, vì vậy một quy trình chuyển đổi mô hình có vẻ không thay đổi về số lượng token thô nhưng đại diện cho sự giảm chi phí đáng kể. Để giải thích điều này, chúng tôi sử dụng chỉ số Token hiệu dụng (ET) áp dụng các hệ số nhân mô hình cho mỗi loại token.
- Khối lượng công việc là một kho lưu trữ trực tiếp: Theo như chúng tôi biết, không có điểm chuẩn agentic-workflow nào mà chúng tôi có thể sử dụng để tối ưu hóa việc sử dụng token. Chúng tôi cố gắng chuẩn hóa điều này bằng cách theo dõi số lượng lệnh gọi API LLM cùng với số lượng token; số lượt LLM mỗi lần chạy không đổi và số token mỗi lượt giảm cho thấy sự cải thiện hiệu quả thực sự.
- Chất lượng có thay đổi không? Việc hiểu chất lượng đầu ra là cân nhắc khó nhất. Một mô hình nhẹ hơn chạy một quy trình bị hạn chế hơn có thể tạo ra đầu ra chất lượng thấp hơn.
Kết quả ban đầu
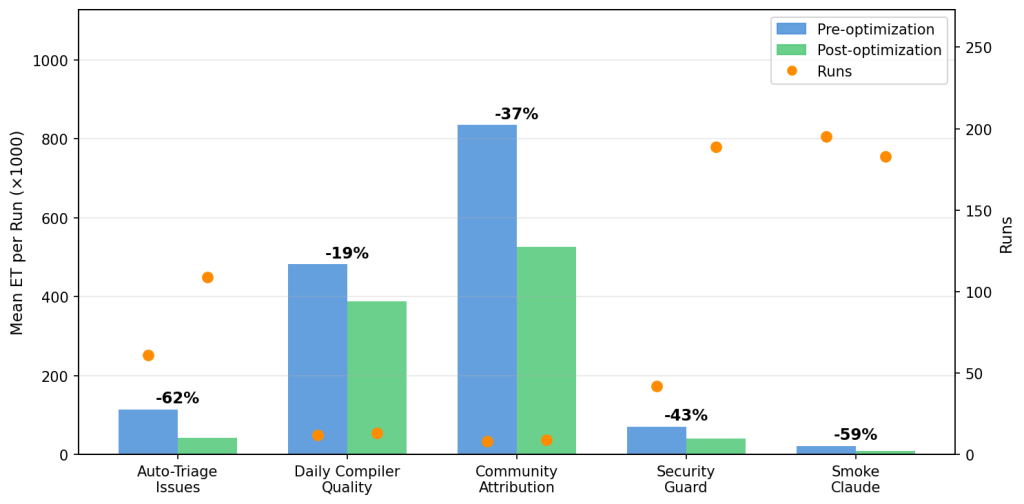
Sau khi triển khai trình kiểm toán và trình tối ưu hóa trên hơn một chục quy trình sản xuất, chúng tôi đã tải xuống các tạo phẩm sử dụng token cho các lần chạy trước và sau khi mỗi quy trình được tối ưu hóa và tính toán ET cho mỗi lần chạy.
- Auto-Triage Issues cho thấy sự giảm bền vững rõ ràng là 62% trên 109 lần chạy sau khi sửa.
- Daily Compiler Quality cho thấy sự cải thiện 19% trên 12 lần chạy sau khi sửa.
- Daily Community Attribution cho thấy sự cải thiện 37% trên 8 lần chạy sau khi sửa.
- Trong repo gh-aw-firewall, Security Guard và Smoke Claude có nhiều lần chạy sau khi sửa nhất và cho thấy sự cải thiện lần lượt là 43% và 59%.
Tần suất chạy quan trọng không kém mức tiết kiệm mỗi lần chạy. Ví dụ, Auto-Triage Issues kích hoạt trên mọi vấn đề mới (trung bình 6,8 lần chạy mỗi ngày) nên 62% tiết kiệm cộng gộp rất nhanh.
Bài học rút ra
Dựa trên những kết quả này, chúng tôi làm nổi bật ba mô hình:
- Nhiều lượt tác nhân là thu thập dữ liệu xác định: Auto-Triage Issues cho thấy sự cải thiện mạnh mẽ nhất vì tối ưu hóa đã loại bỏ sự không hiệu quả cấu trúc: nhiều lượt tác nhân được dành cho các thao tác đọc không yêu cầu suy luận. Di chuyển các thao tác đọc đó thành các bước CLI trước tác nhân đã loại bỏ chúng hoàn toàn khỏi vòng lặp suy luận LLM. Lời gọi LLM rẻ nhất là lời gọi bạn không thực hiện.
- Các công cụ không sử dụng rất tốn kém: Việc loại bỏ một công cụ duy nhất không cần thiết có thể tiết kiệm hàng nghìn token.
- Một quy định sai cấu hình duy nhất có thể gây ra các vòng lặp vượt khỏi tầm kiểm soát: Một quy trình bị chặn do cấu hình sai một dòng đã khiến tác nhân rơi vào vòng lặp dự phòng 64 lượt. Việc sửa lỗi cho phép các mẫu bash đã loại bỏ vòng lặp đó.
Tiếp theo là gì?
Các công cụ chúng tôi sử dụng để tối ưu hóa các quy trình của mình, bao gồm khả năng quan sát cấp API, các quy trình kiểm toán tự động, cắt bỏ công cụ MCP và thay thế CLI, đều có sẵn ngay hôm nay trong khung GitHub Agentic Workflows. Bước tiếp theo là chuyển từ tối ưu hóa cấp quy trình sang tối ưu hóa cấp hệ thống.
Nếu bạn đang chạy các agentic workflows trong CI và tự hỏi liệu mình có đang chi tiêu nhiều hơn cần thiết hay không, bước đầu tiên cũng giống như chúng tôi: thêm proxy API, bật ghi nhật ký và để dữ liệu cho bạn biết nơi cần nhìn.
Nếu bạn muốn thêm các quy trình được đề cập ở đây, bạn có thể简单地 thả chúng vào repo của mình bằng cách sử dụng CLI gh-aw:
gh extensions install github/gh-aw
gh aw add githubnext/agentic-ops/copilot-token-audit githubnext/agentic-ops/copilot-token-optimizer
Chạy chúng song song với CI hiện có sẽ cung cấp cho bạn khả năng hiển thị ngay lập tức về việc sử dụng và giúp tối ưu hóa liên tục các quy trình của bạn theo thời gian.
Bài viết liên quan
Công nghệ
Open Terminal: Ứng dụng phong cách Bloomberg giúp dân đầu tư cá nhân tiếp cận dữ liệu tài chính chuyên sâu
04 tháng 6, 2026

Phần mềm
Triển khai mảng động trong C: Không cần Struct, không lưu trữ dung lượng
13 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026