
GitHub xây dựng AI Agent hỗ trợ khả năng tiếp cận: Bài học từ quá trình phát triển
GitHub đang thử nghiệm một tác nhân AI chuyên về khả năng tiếp cận nhằm hỗ trợ kỹ sư giải đáp thắc mắc và tự động khắc phục các vấn đề đơn giản. Đến nay, công cụ này đã xem xét hơn 3.500 pull request với tỷ lệ giải quyết đạt 68%. Bài viết chia sẻ chi tiết về kiến trúc, cách tối ưu hóa token và những bài học quan trọng trong quá trình phát triển.

Các tác nhân AI (AI agents) đang trở thành phương thức làm việc phổ biến với mã nguồn trong thời gian gần đây. Tại GitHub, chúng tôi đã áp dụng phương pháp tạo và chỉnh sửa mã dựa trên tác nhân cho nhiều sáng kiến khác nhau, bao gồm cả việc thử nghiệm một tác nhân nhằm hỗ trợ cam kết về khả năng tiếp cận (accessibility).
Hiện tại, GitHub đang triển khai thử nghiệm một tác nhân khả năng tiếp cận tổng hợp với hai mục tiêu chính:
Cung cấp cho các kỹ sư câu trả lời đáng tin cậy và kịp thời về các vấn đề liên quan đến khả năng tiếp cận ngay trong GitHub Copilot CLI và tích hợp Copilot trên VS Code. Phát hiện và tự động khắc phục các vấn đề khả năng tiếp cận đơn giản, khách quan trước khi chúng được đưa vào môi trường sản xuất.
Đối với mục tiêu thứ hai, tác nhân được cấu hình để tự động đánh giá các thay đổi sửa đổi mã nguồn front-end của chúng tôi.
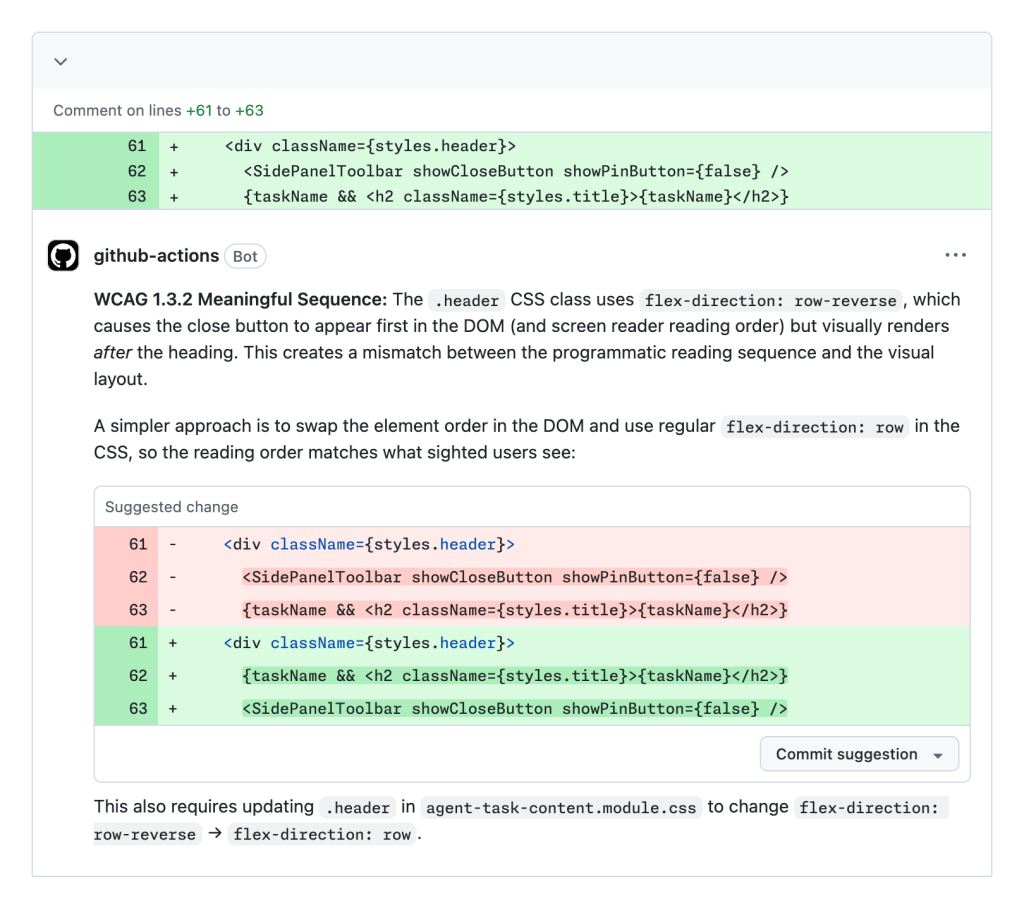 Tác nhân Accessibility trong hành động
Tác nhân Accessibility trong hành động
Tính đến nay, tác nhân đã xem xét 3.535 pull request và đạt tỷ lệ giải quyết thành công là 68%. Theo thứ tự xuất hiện, năm loại vấn đề phổ biến nhất tập trung vào:
Làm rõ cấu trúc và mối quan hệ để các công nghệ hỗ trợ có thể hiểu được. Cung cấp tên gọi rõ ràng, ngắn gọn cho các điều khiển tương tác. Đảm bảo người dùng nhận biết được các thông báo quan trọng. Đảm bảo có văn bản thay thế cho nội dung không phải văn bản. Di chuyển tiêu điểm bàn phím qua các trang và chế độ xem theo một thứ tự logic.
Mỗi loại vấn đề này đại diện cho những ma sát và rào cản được tự động loại bỏ, giúp những người sử dụng và phụ thuộc vào công nghệ hỗ trợ dễ dàng tiếp cận GitHub hơn.
Tư duy cốt lõi
Mô hình xã hội về khuyết tật dạy chúng ta rằng các rào cản tiếp cận — và hậu quả là sự khiếm khuyết — có thể được tạo ra do cách xây dựng môi trường. Tư duy tương tự cũng áp dụng cho các trải nghiệm kỹ thuật số.
Với tác nhân khả năng tiếp cận, chúng tôi không cố gắng "giải quyết" vấn đề accessibility một cách cô lập. Thay vào đó, chúng tôi cố gắng hỗ trợ nỗ lực của đồng nghiệp, giúp họ loại bỏ tốt hơn các rào cản có thể phát sinh do cách chúng tôi xây dựng giao diện người dùng của GitHub.
Tác nhân khả năng tiếp cận không phải là một "viên đạn bạc" có thể tự động giải quyết mọi tình huống giả định. Việc hiểu, tôn trọng và phổ biến tư duy này giúp xác định rõ phạm vi trách nhiệm của tác nhân. Điều này đã đẩy nhanh quá trình ra mắt thử nghiệm, dẫn đến sự ủng hộ nhiều hơn cho nỗ lực này.
Kho tàng từ dữ liệu cũ
Giống như bất kỳ lĩnh vực chuyên môn nào khác, các hướng dẫn mơ hồ trong tệp kỹ năng là không đủ. Việc yêu cầu một Mô hình Ngôn ngữ Lớn (LLM) "sử dụng các phương pháp hay nhất về khả năng tiếp cận" với một danh sách ví dụ ngắn gọn sẽ không hiệu quả.
Khi tạo mã, các LLM có xu hướng tạo ra các mẫu chống accessibility (antipatterns) đáng tiếc, bởi vì mọi mô hình LLM lớn hiện nay đều được đào tạo trên hàng thập kỷ mã nguồn thiếu khả năng tiếp cận.
Để chống lại điều này, tác nhân cần nội dung tốt hơn để tham khảo.
Do đó, tôi nhiệt thành khuyến nghị đầu tư vào việc ghi danh mục và khắc phục thủ công các vấn đề khả năng tiếp cận. Sau khi đạt được một số tiến bộ, dữ liệu này có thể được kết hợp vào tác nhân.
Các vấn đề và các pull request tương ứng cung cấp các ví dụ có ngữ cảnh cao cho LLM tham khảo, được viết bằng các quy ước được thiết lập bởi tổ chức triển khai nó. Bộ sưu tập các vấn đề và mã nguồn này là một trong những tài sản mạnh mẽ nhất mà tác nhân có thể tận dụng.
Hiệu quả tiêu thụ Token
Khả năng tiếp cận là một mối quan tâm mang tính toàn diện, giao thoa với mã hóa, thiết kế, biên tập văn bản và nhiều ngành kỷ thuật khác liên quan đến việc tạo giao diện người dùng.
Rất nhiều công việc liên quan đến accessibility cũng mang tính ngữ cảnh cao, nghĩa là một người thường cần bức tranh toàn cảnh về vấn đề trước khi có thể đưa ra lời khuyên phù hợp về việc cần làm.
Do hai yếu tố này, một tác nhân khả năng tiếp cận tổng quát có thể tiêu thụ một lượng lớn token khi thực hiện công việc. Điều này dẫn đến ba hậu quả tiêu cực:
Tăng lượng đầu ra không đáng tin cậy. Thời gian phản hồi chậm hơn. Tăng chi phí vận hành.
Rất quan trọng phải tỉ mỉ khi cấu trúc tác nhân. Dưới đây là cách chúng tôi đã thực hiện điều đó.
Sử dụng các tác nhân con (Sub-agents)
Tác nhân khả năng tiếp cận ban đầu là một tác nhân đơn khối (monolithic), nhưng nhanh chóng vượt qua các hạn chế của cách tiếp cận này. Do đó, chúng tôi đã phát triển nó để sử dụng kiến trúc tác nhân con.
Nhiều hướng dẫn khuyên nên tạo một bộ sưu tập lớn các tác nhân con, mỗi cái có trách nhiệm cụ thể riêng. Ở đây, các tác nhân con được thực thi song song, với tác nhân chính hòa giải đầu ra của chúng.
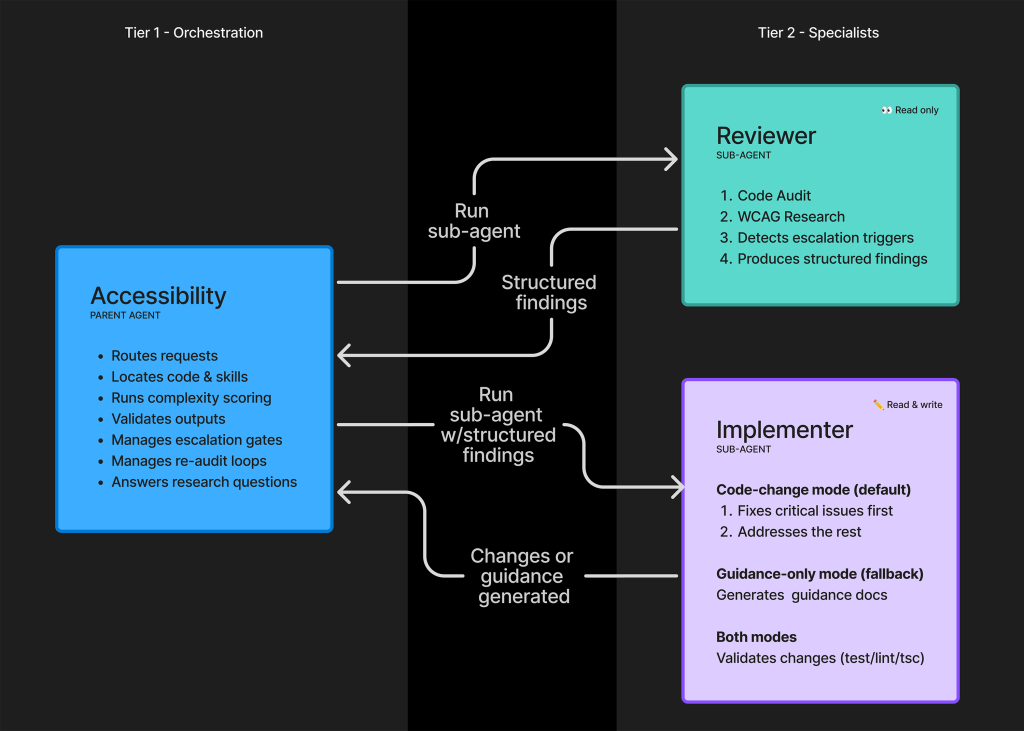
Ngạc nhiên thay, cách tiếp cận này đã phản tác dụng đối với tác nhân khả năng tiếp cận của chúng tôi. Thay vào đó, chúng tôi đã sử dụng hai tác nhân con chuyên biệt:
Tác nhân con đầu tiên đóng vai trò là người xem xét và nghiên cứu thụ động. Tác nhân con thứ hai đóng vai trò là người thực thi chủ động.
Hai tác nhân con được sandbox hóa và không thể trực tiếp truyền nội dung cho nhau. Thay vào đó, chúng tạo ra một đầu ra có cấu trúc theo mẫu. Đầu ra này sau đó được phục vụ cho tác nhân khả năng tiếp cận cha điều phối để tiêu thụ, xác thực và định tuyến.
 Quy trình làm việc với Sub-agents
Quy trình làm việc với Sub-agents
Có một vài lý do cho cách tiếp cận này:
Các điểm kiểm tra leo thang: Người xem xét kiểm tra các khu vực có thể cần sự can thiệp của con người. Điều này bao gồm nhiều lỗi WCAG mức độ nghiêm trọng cao, cũng như danh sách các mẫu được biết đến là khó để tạo khả năng tiếp cận. Hành vi dựa trên độ phức tạp: Tác nhân được hướng dẫn hoạt động ở chế độ hướng dẫn chuyên biệt nếu mã cơ bản được coi là quá phức tạp. Ở đây, tác nhân cha đóng vai trò trọng tài, trong khi tác nhân xem xét "không có ý kiến" và chỉ báo cáo các phát hiện theo hướng dẫn. Lọc: Người xem xét trình bày mọi thứ họ tìm thấy. Tác nhân cha sau đó sử dụng tài nguyên và kỹ năng để xác định điều gì liên quan đến yêu cầu. Việc người xem xét chuyển tất cả phát hiện cho người thực thi sẽ tốn kém và có thể khiến nó thực hiện các nhiệm vụ không liên quan và phản tác dụng. Khả năng truy xuất nguồn gốc: Giao tiếp trực tiếp giữa các tác nhân con sẽ loại bỏ khả năng tạo và xem xét nhật ký kiểm tra các quyết định của người dùng và tác nhân. Điều này rất quan trọng khi xét đến hướng dẫn của tác nhân xung quanh các mẫu phức tạp, cũng như tính chất ngữ cảnh cao của công việc accessibility.
Thực hiện lệnh theo thứ tự tuyến tính
Ngoài việc là một mối quan tâm mang tính toàn diện, công việc khả năng tiếp cận kỹ thuật số hiệu quả cũng đòi hỏi một cách tiếp cận có phương pháp và tỉ mỉ.
Mối lo ngại về việc sử dụng các tác nhân con để tăng tốc độ phản hồi của LLM được cân bằng bởi nhu cầu kết quả của nó phải chính xác. Chúng tôi nhận thấy rằng việc buộc tác nhân thực hiện các lệnh tác nhân con theo một thứ tự cố định là chìa khóa.
Chúng tôi đầu tiên thiết lập một tập hợp các giai đoạn được sắp xếp theo thứ tự của cha. Mỗi giai đoạn tự chứa các bước lệnh con được sắp xếp, đi kèm với các tài nguyên và kỹ năng liên quan.
Điều thú vị về thứ tự tuyến tính này là nó phản ánh cách tôi cá nhân sẽ tiếp cận việc thực hiện các nhiệm vụ kiểm tra, khắc phục và báo cáo.
Sử dụng lược đồ mẫu để truyền nội dung tác nhân con
Toàn bộ hoạt động của các tác nhân con sandbox hóa được xây dựng xung quanh các tệp lược đồ mẫu. Các tệp này tạo ra sự nhất quán rất quan trọng để giữ cho tác nhân tập trung và đi đúng hướng.
Hai lược đồ mẫu bao gồm:
Lược đồ mẫu người xem xét: Tập trung vào việc cần kiểm tra gì và cách tìm thông tin áp dụng cho nó. Lược đồ mẫu người thực thi: Tập trung vào việc cần sửa gì và cách sửa nó.
Nếu không có các tệp lược đồ, các tác nhân sẽ đều cố gắng giao tiếp tùy ý với nhau. Điều này sẽ tạo ra chi phí token tăng lên, ảo giác không mong muốn, các thay đổi mã không cần thiết và hành vi khó hoặc không thể kiểm tra được cho mục đích kiểm tra tác nhân.
Thừa nhận các hạn chế
Một khía cạnh quan trọng khác của việc tạo tác nhân khả năng tiếp cận là hiểu rõ các khu vực mà tác nhân có thể thiếu sót.
Vì tác nhân không phải là giải pháp "chìa khóa trao tay" cho khả năng tiếp cận, chúng tôi muốn tránh các tình huống mà đầu ra sai sót của tác nhân có thể không được kiểm tra kỹ lưỡng bởi con người sử dụng nó. Điều này đặc biệt đúng khi người đó không rành về các cân nhắc và thực hành khả năng tiếp cận kỹ thuật số.
Dưới đây là những gì chúng tôi đã làm để phù hợp với các hạn chế của tác nhân:
Đánh giá độ phức tạp của mã
Chúng tôi muốn tránh các tình huống mà chúng tôi sẽ cần thực hiện công việc tốn kém và tốn thời gian để xem xét lại một giải pháp không có khả năng tiếp cận mà tác nhân "nghĩ" là có khả năng tiếp cận.
Để hỗ trợ giải quyết vấn đề này, tác nhân khả năng tiếp cận sử dụng một tập lệnh shell nhỏ để phân tích mã mà nó được thiết lập để làm việc. Tập lệnh này rất đơn giản, sử dụng một tập hợp nhỏ các heuristic cơ bản để đánh giá độ phức tạp tương đối và chắt lọc nó thành một điểm số.
Điểm số này sau đó được tác nhân tiêu thụ. Nếu điểm số vượt qua ngưỡng được đặt, tác nhân được hướng dẫn không thực hiện thay đổi mã. Thay vào đó, nó sẽ thông báo cho người dùng rằng họ nên liên hệ với đội ngũ khả năng tiếp cận để tham vấn về những gì họ đang cố gắng làm.
Xác định các mẫu rủi ro cao
Đó là một điều tinh tế để hiểu, nhưng hãy biết rằng hoàn toàn có thể có mã vượt qua các kiểm tra khả năng tiếp cận tự động, nhưng lại không thể sử dụng về mặt chức năng.
Là một phần bổ sung cho độ phức tạp của mã, tác nhân khả năng tiếp cận được hướng dẫn tránh cố gắng tạo mã cho các mẫu mà đội ngũ khả năng tiếp cận đã xác định là rủi ro cao. Điều này bao gồm, nhưng không giới hạn: kéo và thả (drag and drop), thông báo dạng toast (toasts), trình soạn thảo văn bản phong phú, chế độ xem cây (tree views) và lưới dữ liệu (data grids).
Các mẫu này đòi hỏi sự chú ý và chi tiết tập trung cao và hiện nằm ngoài khả năng của một LLM để tạo ra theo cách thực sự hoạt động với công nghệ hỗ trợ.
Việc không cấm các mẫu rủi ro cao và môi trường mã có độ phức tạp cao sẽ dẫn đến các yêu cầu không cần thiết về thời gian của mọi người để giải quyết lại, và cũng đại diện cho rủi ro danh tiếng cho đội ngũ khả năng tiếp cận. Chúng tôi tránh điều này bằng cách tắt khả năng của LLMs đi xuống con đường này.
Giảm thiên lệch hành động
Tôi rất ngại nhân hóa LLMs, nhưng một phẩm chất mà tất cả chúng dường như chia sẻ là khao khát tạo ra nội dung một cách tuyệt vọng. Đối với Copilot, điều đó thường có nghĩa là tạo mã.
Chúng tôi đã phải tạo ra các hướng dẫn chống gian lận để ngăn LLM tạo ra những cách lén lút để vượt qua các hướng dẫn của nó là không tạo mã khi cần chuyên môn của con người. Điều này ngăn nó vi phạm các hướng dẫn can thiệp của chính nó.
Biết rằng các vấn đề có thể xác định bằng chương trình không bao gồm mọi thứ
Các chỉ số thành công của tác nhân nằm trong một bối cảnh lớn hơn.
Trong tổng số 55 Tiêu chí Thành công Cấp A và AA của WCAG, chỉ có 35 tiêu chí có thể được phát hiện thông qua các trình kiểm tra mã tự động xác định. Điều này có nghĩa là khoảng 36% Tiêu chí Thành công Cấp A và AA không thể được phát hiện tự động.
Hoạt động của tác nhân được hỗ trợ bởi LLM đang tiến bộ vào khoảng trống 36% này, nhưng nó không phải là một khoa học chính xác tuyệt đối. Do đó, việc xác định thủ công các rào cản khả năng tiếp cận sớm hơn trong quá trình thiết kế và tạo mẫu nguyên hình — khu vực mà phần lớn các vấn đề accessibility bắt nguồn — trở nên quan trọng.
Tư duy này cũng được phản ánh trong logic leo thang của tác nhân, ở đó các thành viên của Đội ngũ Khả năng tiếp cận có thể làm việc cùng với các nhà thiết kế để giúp xem xét các cách tiếp cận thay thế và lên ý tưởng các giải pháp đạt được mục tiêu kinh doanh mà không làm giảm khả năng tiếp cận.
Sự can thiệp và hỗ trợ này được thực hiện để ngăn chặn các vấn đề tiềm ẩn ở hạ nguồn — và các thiết kế lại tốn kém và tốn thời gian — bị ngăn chặn trước khi chúng có cơ hội bắt đầu.
Đánh giá thủ công đầu ra của tác nhân và điều chỉnh những thứ không hoạt động như mong đợi
Chúng tôi định kỳ thực hiện xem xét thủ công đầu ra của tác nhân để xác định độ chính xác và hiệu quả của nó. Ngoài ra, chúng tôi có các công cụ để bắt lấy tâm lý của người xem xét pull request. Cả hai đều đóng vai trò là các tín hiệu mạnh mẽ cho các khu vực mà tác nhân cần hướng dẫn tốt hơn, cũng như các tài nguyên và kỹ năng mới.
Học hỏi một cách công khai
Tóm lại, chúng tôi đã học được rằng tác nhân:
Được sử dụng để hỗ trợ và tăng cường các nỗ lực khả năng tiếp cận hiện có, không phải để thay thế chúng. Hiệu quả hơn nhiều khi được đào tạo trên các vấn đề khả năng tiếp cận đã được kiểm tra và khắc phục thủ công cho trải nghiệm cụ thể của bạn. Hiệu quả hơn nhiều về việc tiêu thụ token khi sử dụng các tác nhân con. Chính xác và hiệu quả hơn khi thực hiện các lệnh theo cách có phương pháp, tuyến tính. Nhất quán hơn khi được đặt để sử dụng các mẫu được định dạng sẵn để truyền thông tin. Được thiết lập để hiểu các hạn chế của nó và định hướng mọi người đến các hệ thống hỗ trợ thay thế. Được cải thiện khi đầu ra của nó được xem xét định kỳ để xác định các khu vực cần hướng dẫn tốt hơn.
Hành trình này cũng chưa kết thúc. Tác nhân khả năng tiếp cận tiếp tục được lặp lại với hy vọng giúp đảm bảo GitHub là một nền tảng có khả năng tiếp cận và bao trùm cho tất cả các nhà phát triển.
Chúng tôi hy vọng rằng cuối cùng chúng tôi có thể mã nguồn mở tác nhân như một phần trong cam kết giúp cải thiện khả năng tiếp cận của phần mềm mã nguồn mở ở quy mô lớn. Cho đến lúc đó, chúng tôi hy vọng rằng việc chia sẻ những bài học này với nỗ lực trên sẽ giúp các đội khác có một tài liệu để tham khảo cho các nỗ lực khả năng tiếp cận của chính họ.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026