
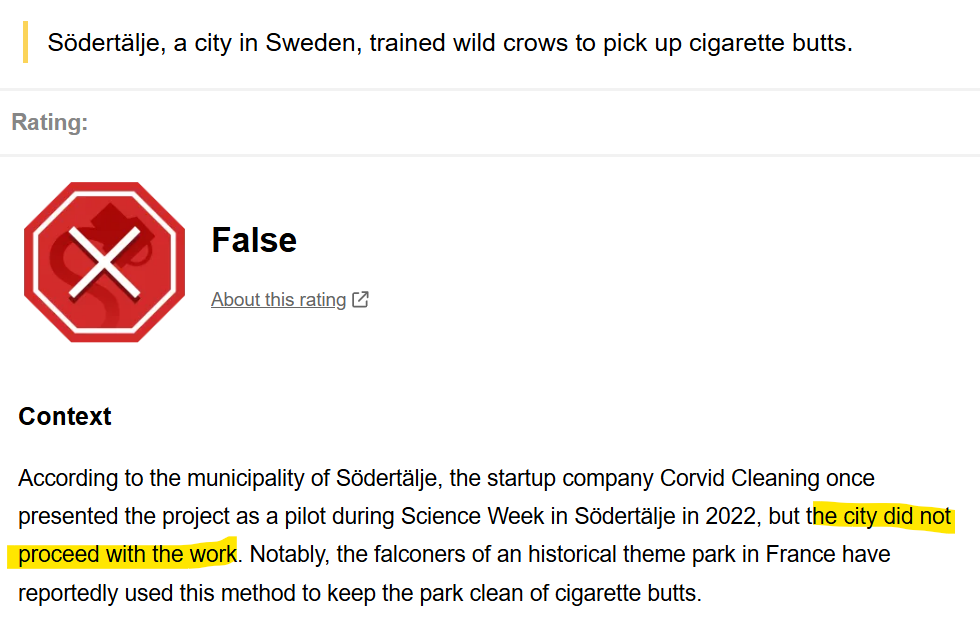
Hãy Kiểm Tra Nguồn Tin Của Mình Đi, Mọi Người Ơi!
Bài viết phản ánh tình trạng báo chí công nghệ hiện nay khi nhiều tác giả dựa quá nhiều vào AI mà không kiểm chứng, dẫn đến việc lan truyền thông tin sai lệch và số liệu giả mạo. Tác giả lấy ví dụ về câu chuyện quạ dọn rác ở Thụy Điển và việc bịa đặt số liệu trong nghiên cứu SmartBear/Cisco để cảnh báo về "ảo giác" của AI và tầm quan trọng của việc xác minh nguồn tin.

Xin lỗi, đây là một bài viết mang tính "trút bầu tâm sự". Có lẽ bạn đã đoán được điều đó ngay từ tiêu đề rồi.
Giọt nước làm tràn ly là một tiêu đề tôi vừa bắt gặp: "Thụy Điển xây dựng những cỗ máy thông minh nơi những con quạ đổi rác lấy thức ăn, biến những loài chim thông minh thành những người dọn dẹp thành phố bất ngờ."
Một bức ảnh rõ ràng do AI tạo ra (một con quạ ba chân là manh mối rõ ràng nhất) đã không giúp tăng thêm độ tin cậy, nhưng chính tiêu đề đó đã thúc đẩy tôi thực hiện một tìm kiếm. Tuy nhiên, "tìm kiếm" ở đây là một từ quá lớn, vì tôi chỉ cần thực hiện đúng một truy vấn.
Thực tế không phải Thụy Điển xây dựng, mà là một startup tại Thụy Điển. Không phải "xây dựng", mà là chạy một dự án thí điểm duy nhất. Và dự án đó không hề biến quạ thành người dọn dẹp thành phố vì nó đã bị bỏ hoang mà không có bất kỳ bước tiến nào sau đó. Bạn có thể kiểm tra thông tin này tại đây.
Tuy nhiên, nó chắc chắn hoạt động như một món đồ "hấp dẫn thị giác" nếu bạn muốn dán ánh mắt của người đọc vào bài đăng LinkedIn được tạo bởi AI nhằm mục đích bán hàng (tôi không biết chính xác là bán cái gì; tôi có xu hướng ngừng đọc ngay khi nhìn thấy đồ họa do AI tạo ra).
 Hình ảnh minh họa về dự án quạ dọn rác giả mạo
Hình ảnh minh họa về dự án quạ dọn rác giả mạo
Liên kết không còn đồng nghĩa với độ tin cậy
Câu chuyện về những con quạ dọn dẹp, dù có thể hài hước đến mức nào, cũng không thôi thúc tôi viết bài này. Thực ra, việc các tài liệu tham khảo giả mạo đã là một vấn đề khiến tôi khó chịu từ lâu, nên đây chỉ là "một thêm trong số đó".
Đây là một trường hợp thú vị hơn. Gần đây, tôi đọc một câu chuyện về AI trong lập trình, đầy ắp dữ liệu để chứng minh các tuyên bố của tác giả. Một sự kiện cụ thể được nêu ra như sau:
"Nghiên cứu của SmartBear/Cisco đã thiết lập các con số mà mọi người đang phớt lờ: tỷ lệ phát hiện lỗi giảm từ 87% đối với các PR dưới 100 dòng code xuống còn 28% đối với các PR trên 1.000 dòng code."
Hay đấy. Đây là điều tôi đang nghiên cứu. Hãy xem xét nghiên cứu đó và xem tôi có thể học được gì từ dữ liệu này. Ối, liên kết không dẫn đến nghiên cứu, mà dẫn đến một bài viết khác. Nhưng bài viết đó lại có một liên kết của riêng nó. Liên kết đó lại dẫn đến một bài viết khác nữa thậm chí không còn nhắc đến nghiên cứu.
Nhân tiện, không một trang web nào trong chuỗi liên kết này đề cập đến các con số từ trích dẫn gốc. Tôi đặt cược rằng chúng được tạo bởi AI mà không có bất kỳ sự xác minh nào của con người.
Một con người có năng lực trung bình cũng sẽ nhận ra sự mâu thuẫn này. Và tác giả rõ ràng khao khát đạt đến trình độ chuyên gia cao hơn là chỉ "có năng lực trung bình".
Dữ liệu nguồn là "thủ phạm" chính gây ra ảo giác
May mắn thay, nghiên cứu của SmartBear/Cisco rất dễ tìm thấy trên Google, nên chuỗi liên kết rắc rối đó chỉ là một phiền toái nhỏ. Tuy nhiên, việc đọc bài báo là một trải nghiệm khai sáng.
Không có một chỗ nào trong nghiên cứu tuyên bố tỷ lệ phát hiện 87% hay 28% cho các kích thước Pull Request (PR) cụ thể. Trên toàn bộ mẫu dữ liệu, hầu như không có điểm dữ liệu nào có kích thước PR trên 1.000 dòng code. Cuối cùng, bài báo không đo lường trực tiếp tỷ lệ phát hiện lỗi làm một tham số phân tích (nó sử dụng mật độ lỗi và đưa ra một số kết luận về tỷ lệ phát hiện).
Nói cách khác, toàn bộ tuyên bố trong bài viết gốc có thể đã bị ảo giác (hallucinated).
 Hình ảnh minh họa việc kiểm tra sự thật
Hình ảnh minh họa việc kiểm tra sự thật
Nhờ vả cho tác giả, nghiên cứu của SmartBear/Cisco suy ra rằng các PR dài hơn có thể dẫn đến việc phát hiện lỗi kém hơn. Nhưng nó không đưa ra tuyên bố một cách rõ ràng hay trực tiếp.
"Tỷ lệ kiểm tra dưới 300 LOC/giờ (dòng code mỗi giờ) mang lại kết quả phát hiện lỗi tốt nhất. Tỷ lệ dưới 500 vẫn tốt; hãy kỳ vọng bỏ lỡ một tỷ lệ phần trăm đáng kể các lỗi nếu nhanh hơn thế."
Góc độ ở đây là số dòng code được xem xét mỗi giờ, không phải kích thước PR. Sự suy luận là các PR lớn tốn nhiều thời gian hơn, và có xu hướng rõ ràng là người xem sẽ tăng tốc độ quá trình khi nó tốn nhiều thời gian hơn. Tốc độ xem xét, lần lượt, có tương quan nghịch với mật độ lỗi.
Đó là một khoảng cách khá xa so với "tỷ lệ phát hiện lỗi giảm từ 87% xuống 28%".
AI thất bại ở những ranh giới
Đó là một ví dụ hoàn hảo về sự không đáng tin cậy của AI ở những lĩnh vực ngách. Không có một mẫu dữ liệu khổng lồ nào về "nghiên cứu SmartBear/Cisco" hay các nghiên cứu cho thấy động thái xem xét mã cụ thể. Đối với một Mô hình Ngôn ngữ Lớn (LLM), điều này đã đồng nghĩa với việc nằm ở vùng biên.
Nếu chúng ta để AI chạy tự động, nó chắc chắn sẽ mang lại kết quả. Trong trường hợp có thể xảy ra, khi LLM không tìm thấy câu trả lời phù hợp, nó sẽ bịa ra một cái gì đó. Nó sẽ vui vẻ tạo ra các con số. Chúng sẽ trông ổn. Cụ thể. Có lý. Với một chút may mắn, chúng thậm chí có thể (hơi nào) phù hợp với những gì nguồn thực sự nói. Nhưng nó có thực sự là những gì nghiên cứu báo cáo không?
Như chúng ta đều biết, "73,6% tất cả các số liệu thống kê đều bị bịa đặt." Tôi khuyên bạn nên thêm vào: "Kể từ khi AI được áp dụng rộng rãi, tỷ lệ đó đã tăng lên 86,9%."
Đáng buồn là, càng nhiều chúng ta thuê ngoài nghiên cứu dữ liệu cho AI, sự mỉa mai của tôi càng trở nên chính xác. Và mọi thứ sẽ chỉ tồi tệ hơn. Bài viết gốc với những con số bịa đặt sẽ sớm được một LLM khác sử dụng như một bài viết đáng tin cậy. Sau tất cả, nó trông giống như vậy. Độ dài của chuỗi liên kết sẽ tăng lên một, thêm vào nhiều nhiễu loạn tự củng cố hơn cho các truy vấn AI trong tương lai. Làm tốt lắm, mọi người!
Uy tín là đồng tiền của chúng ta
OK, tôi biết. Tôi không thể đảo ngược dòng chảy. Rác thải AI (AI slop) sẽ ở lại đây. Các thuật toán thưởng cho nó. Viết một bài như thế này tốn của tôi khoảng vài giờ. Nhiều hơn nếu tôi cần nghiên cứu các sự kiện nền. Thêm một chút thời gian để biên tập lại.
ChatGPT có thể đã làm điều đó giúp tôi trong vài phút. Trong khi tôi nhâm nhi ly cà phê và tận hưởng ánh nắng. Với vô số liên kết đi ra và một tấn dữ liệu tham khảo. Không mồ hôi. Và kết quả thì sao? Ngoại trừ một chút cảm xúc cá nhân, nó có thể trông tốt như của tôi.
Giá duy nhất phải trả là uy tín của tôi. Dữ liệu được kéo bởi LLM có thể bị hiểu sai (nếu tôi may mắn) hoặc hoàn toàn giả mạo (nếu tôi không may). Các liên kết tham khảo sẽ dẫn đến bất kỳ bài viết nào xếp hạng tốt nhất trong Tối ưu hóa Công cụ Tạo sinh (GEO - đây là SEO của năm 2026). Vô tình, những trang này có xu hướng rất tệ để đọc đối với con người. Kết quả cuối cùng sẽ là thứ mà tôi sẽ không muốn ký tên vào một cách có ý thức.
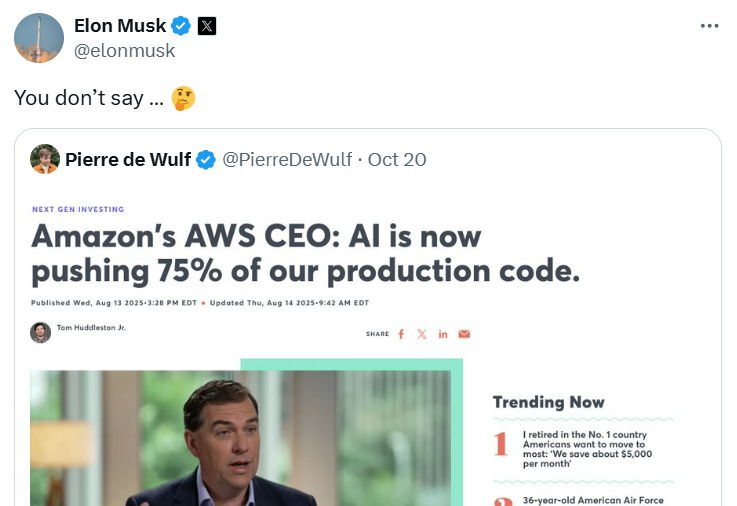
Về cơ bản, tôi sẽ trở thành phiên bản rẻ tiền, ẩn danh của Elon Musk, lan truyền một trò đùa có vẻ hài hước (nhưng cũng giả mạo) về sự cố lớn của AWS.
Tôi sẽ đánh đổi sự đáng tin cậy và uy tín của mình. Chính những công cụ này là yếu tố then chốt để điều hướng các mối quan hệ chuyên nghiệp trong kỷ nguyên AI.
 Hình ảnh minh họa phản ứng của Elon Musk
Hình ảnh minh họa phản ứng của Elon Musk
Hãy kiểm tra nguồn tin của bạn, mọi người!
Với khả năng chú ý ngày càng thu hẹp, chúng ta không muốn dành thời gian đọc bài báo nghiên cứu thực tế để chứng minh cho tuyên bố vội vàng của mình. Tôi hiểu điều đó. Tôi cũng tự trải qua nỗi đau đó.
5 năm trước, chúng ta cần khá chính xác với kỹ năng Google của mình để tìm một bài báo nghiên cứu phù hợp để chứng minh [chèn bất kỳ tuyên bố nào ở đây]. Bây giờ thì sao? Giải thích điều đó bằng tiếng Anh đơn giản cho ChatGPT hoặc Gemini, và voila! Đây là một liên kết mới nướng cho bạn.
Nó có thể là rác thải, nhưng làm sao bạn biết được? Đó là, trừ khi bạn làm bài tập về nhà của mình và tự đọc cái đó. Và sau đó áp dụng ít nhất một sự phán xét tối thiểu.
Ý tôi là, với tư cách là những người viết, chúng ta nhất thiết cũng là người đọc. Tạo ra dữ liệu giống như việc đi vệ sinh ngay trước cửa nhà mình. Tại sao bạn lại tin vào bất kỳ thứ gì bạn đọc nếu bạn để AI bịa ra rác thải trong "viết lách" của mình mà không có giám sát? Cuối cùng, tại sao bạn lại mong đợi ai đó quan tâm nhiều hơn bạn?
Vì vậy, hãy làm ơn kiểm tra nguồn tin của mình đi, mọi người!
Tôi thực sự đã đọc các nguồn mà tôi liên kết ở đây. Bao gồm cả nghiên cứu của SmartBear/Cisco. Tôi biết, lạ lắm phải không?


