
LLM có thể thay thế người trả lời khảo sát không? Thách thức về sự đa dạng và kỹ thuật "Unlearning"
Các nghiên cứu mới cho thấy LLM có thể dự đoán chính xác mức trung bình của các cuộc khảo sát kinh tế nhưng lại gặp vấn đề nghiêm trọng về sự đa dạng (mode collapse). Kỹ thuật "unlearning" đang được xem xét để giải quyết vấn đề này, giúp các mô hình AI tạo ra các phản hồi phân tán và thực tế hơn.

Trong bối cảnh các Mô hình Ngôn ngữ Lớn (LLM) ngày càng trở nên tinh vi, một câu hỏi thú vị được đặt ra là: Liệu AI có thể thay thế con người trong các cuộc khảo sát xã hội và kinh tế? Các nghiên cứu gần đây chỉ ra rằng, mặc dù LLM có thể bắt chước chính xác mức trung bình của các cuộc khảo sát quy mô lớn, chúng lại thất bại thảm hại trong việc tái tạo sự đa dạng của ý kiến con người.
Vấn đề cốt lõi nằm ở hiện tượng được gọi là "mode collapse" (sụp đổ chế độ), nơi mà hàng ngàn nhân cách ảo được tạo ra bởi AI lại đưa ra những câu trả lời gần như giống hệt nhau.
LLM: Bậc thầy tính trung bình nhưng kém đa dạng
Khi yêu cầu một LLM mô phỏng 6.000 hộ gia đình Mỹ để trả lời các câu hỏi về kỳ vọng lạm phát, kết quả cho thấy sự chính xác đáng ngạc nhiên về mặt số liệu trung bình. Ví dụ, mức trung vị kỳ vọng lạm phát một năm tới mà LLM đưa ra rất gần với con số 3% từ Khảo sát Kỳ vọng Người tiêu dùng (SCE) năm 2020. Điều này đã dấy lên hy vọng rằng LLM có thể trở thành một công cụ bổ trợ rẻ tiền và tần suất cao cho các cuộc khảo sát truyền thống.
Tuy nhiên, vấn đề nằm ở "thời điểm thứ hai" (second moment) của phân phối xác suất – thước đo sự phân tán của dữ liệu. Cùng một mô hình Llama-3 có thể đưa ra mức trung vị chính xác đến từng phần trăm, nhưng lại đặt 95% số người trả lời ảo của nó vào một khoảng biên độ cực kỳ hẹp (chỉ 2 phần trăm). Trong khi đó, dữ liệu thực tế từ SCE năm 2020 cho thấy sự phân tán rộng lớn từ -25% đến +27%.
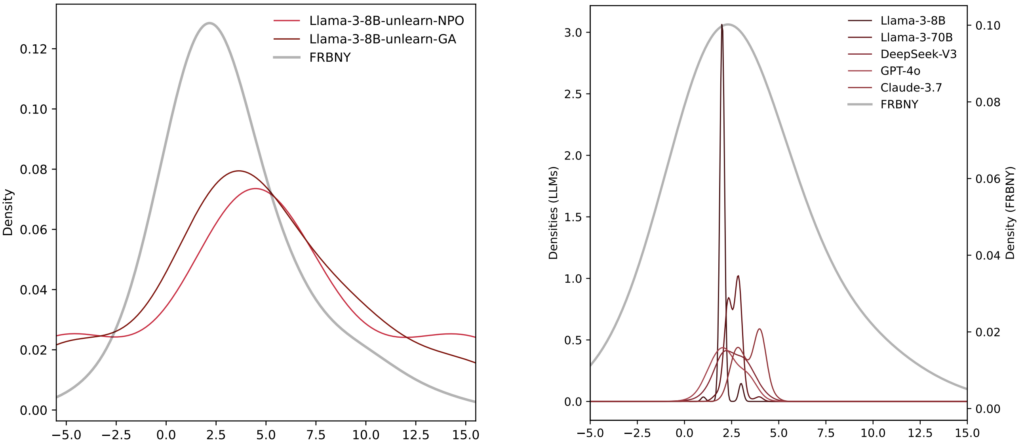 So sánh sự phân tán của khảo sát thực tế và khảo sát tổng hợp bởi LLM
So sánh sự phân tán của khảo sát thực tế và khảo sát tổng hợp bởi LLM
Nói cách khác, mức trung bình là đúng, nhưng quần thể đằng sau nó không tồn tại. Thay vì mô phỏng một cộng đồng đa dạng, việc chạy mô phỏng với hàng ngàn nhân cách LLM thực chất chỉ giống như việc hỏi một tác nhân đại diện duy nhất hàng ngàn lần.
Nguyên nhân và giải pháp: Kỹ thuật "Unlearning"
Nguyên nhân chính của vấn đề này là do LLM đã "nhớ" quá tốt các dữ liệu thống kê trong quá trình huấn luyện. Khi được hỏi về lạm phát, mô hình có xu hướng truy xuất các bảng số liệu CPI, các bản tin kinh tế hoặc các bản sao của khảo sát SCE mà nó đã học, thay vì thực sự suy luận dựa trên nhân cách được gán.
Để khắc phục điều này, các nhà nghiên cứu đã áp dụng kỹ thuật "unlearning" (quên học/xóa bỏ kiến thức) lên mô hình Llama-3.1-8B-Instruct. Thay vì chỉ yêu cầu mô hình không tra cứu thống kê, họ chủ động loại bỏ các trọng số liên quan đến dữ liệu này.
Hai phương pháp được sử dụng là:
- Gradient Ascent (GA): Tối đa hóa mất mát dự đoán trên tập dữ liệu cần quên (các số liệu CPI chính thức) trong khi vẫn giữ khả năng suy luận chung.
- Negative Preference Optimization (NPO): Coi các số liệu thống kê chính thức là các mẫu hoàn thành không mong muốn và penalize việc tạo ra chúng.
Kết quả cho thấy cả hai phương pháp đều giúp khôi phục sự phân tán thực tế hơn cho các câu trả lời. Trong khi mô hình cơ bản có độ chính xác đuôi (tail accuracy) bằng 0%, mô hình sau khi áp dụng GA đã đạt tới 97%.
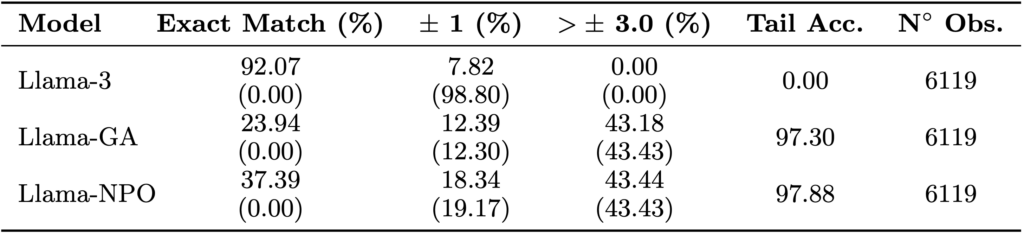 Hiệu quả của các chiến lược Unlearning trong việc cải thiện sự phân tán
Hiệu quả của các chiến lược Unlearning trong việc cải thiện sự phân tán
Mô phỏng thử nghiệm ngẫu nhiên có đối chứng (RCT)
Mục tiêu tối thượng của việc sử dụng LLM trong khảo sát là khả năng tái tạo các Thử nghiệm Ngẫu nhiên có Đối chứng (RCT) – một phương pháp nghiên cứu tốn kém và phức tạp. Các nhà nghiên cứu đã thử nghiệm khả năng này bằng cách mô phỏng một RCT thực tế về tác động của thông tin chính sách tiền tệ đối với kỳ vọng lạm phát.
Kết quả cho thấy sự khác biệt rõ rệt:
- Mô hình Llama-3 cơ bản và Llama-NPO gần như không phản ứng với các phương pháp điều trị (treatment) khác nhau.
- Chỉ có mô hình Llama-GA (sử dụng Gradient Ascent) là cho thấy các phản hồi phân tách rõ ràng theo các nhóm thông tin, tương đồng với hành vi của người tham gia thực tế.
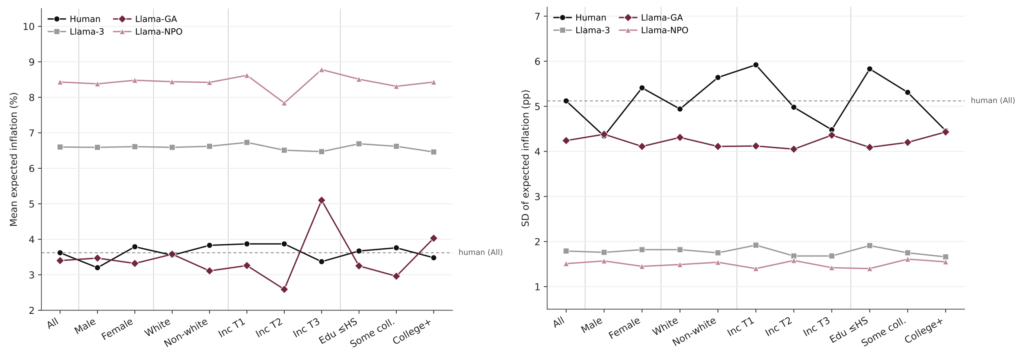 So sánh độ phân tán giữa các mô hình LLM và dữ liệu thực tế FRBNY SCE
So sánh độ phân tán giữa các mô hình LLM và dữ liệu thực tế FRBNY SCE
Kết luận và hướng đi tương lai
Đối với các nhà nghiên cứu và thực hành viên đang cân nhắc sử dụng LLM để tiến hành khảo sát, bài học rút ra là rõ ràng: LLM hiện tại chưa thể bắt chước các nhân cách khác nhau một cách thuyết phục. Chúng có xu hướng thu hẹp về một câu trả lời trung bình an toàn.
Mặc dù kỹ thuật "unlearning" (đặc biệt là Gradient Ascent) đã chứng minh khả năng khôi phục phần nào sự phân tán và các tác động điều trị trong RCT, nhưng đây chưa phải là giải pháp vạn năng. Khoảng cách giữa độ chính xác của giá trị trung bình và độ chính xác của phân phối vẫn còn rất lớn.
Trong tương lai, các công trình nghiên cứu cần coi độ chính xác của phân phối và vấn đề rò rỉ dữ liệu là các ràng buộc song hành. Tiến bộ trong lĩnh vực này sẽ phụ thuộc vào các phương pháp đánh giá không chỉ dựa trên trung bình mà còn chú trọng đến sự phân tán, phần đuôi của phân phối và khả năng cập nhật niềm tin của các mô hình AI.


