
LLMs không còn là một "hộp đen" bí ẩn như bạn từng nghĩ
Nghiên cứu mới của Anthropic đã phá vỡ định kiến về các mô hình ngôn ngữ lớn (LLM) là những "hộp đen" không thể giải mã. Thông qua kỹ thuật giải thích cơ chế, chúng ta giờ đây có thể nhìn sâu vào bên trong để hiểu cách mô hình thực hiện suy luận đa bước và xử lý thông tin.
LLMs không còn là một "hộp đen" bí ẩn như bạn từng nghĩ
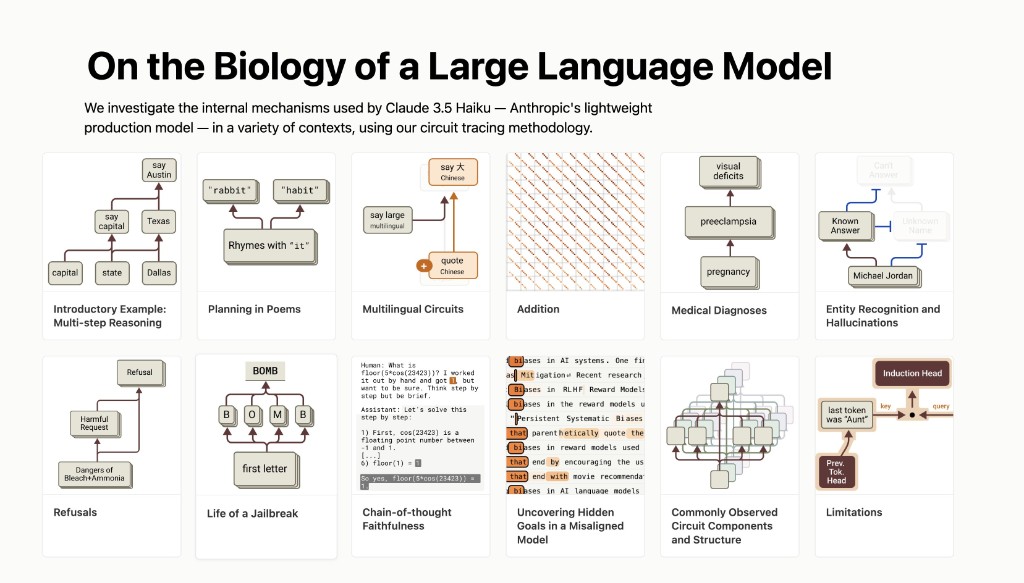
Trong nhiều năm, giới công nghệ thường mô tả các Mô hình Ngôn ngữ Lớn (LLM) như những "hộp đen" (black box) — chúng ta biết đầu vào và đầu ra, nhưng cơ chế hoạt động bên trong vẫn là một ẩn số. Tuy nhiên, nghiên cứu mới nhất của Anthropic với tiêu đề "On the Biology of a Large Language Model" (2025) đã chứng minh điều ngược lại. Nhờ sự tiến bộ của lĩnh vực "giải thích cơ chế" (mechanistic interpretability), chúng ta đang bắt đầu giải mã được những gì diễn ra trong "bộ não" của AI.
LLM thực sự đang "nghĩ" gì?
Việc hiểu được một LLM đang suy nghĩ gì là vô cùng giá trị. Nó không chỉ giúp chúng ta điều khiển hành vi của mô hình mà còn phát hiện những ý định nguy hiểm tiềm ẩn. Tuy nhiên, việc này khó khăn hơn nhiều so với việc chỉ quan sát sự kích hoạt của từng neuron riêng lẻ.
Vấn đề nằm ở hiện tượng siêu vị trí (superposition): Một neuron duy nhất có thể tham gia vào nhiều khái niệm không liên quan, và một khái niệm cụ thể lại bị phân tán trên hàng loạt neuron khác nhau. Bạn không thể chỉ đọc ý nghĩa từ một đơn vị duy nhất; chúng ta cần các phương pháp tiếp cận sáng tạo hơn.
 Kỹ thuật thay thế mô hình để tìm ra các đặc điểm thưa
Kỹ thuật thay thế mô hình để tìm ra các đặc điểm thưa
Kỹ thuật truy vết mạch (Circuit Tracing)
Một trong những phương pháp đột phá là kỹ thuật truy vết mạch. Anthropic đã huấn luyện một mô hình "thay thế" để xác định các khái niệm rời rạc, sau đó giám sát cách các khái niệm này tương tác trong quá trình xử lý dữ liệu (forward pass).
Kỹ thuật này huấn luyện mô hình thay thế để tái tạo lại đầu ra của các lớp MLP trong mô hình gốc một cách thưa (sparse). Kết quả là quá trình phân tích này đã giải mã các đặc điểm của mô hình gốc thành các khái niệm cấp cao mà con người có thể dễ dàng nhận diện, chẳng hạn như "Texas" hay "Thế vận hội".
Khi đã có các đặc điểm dễ hiểu này, các nhà nghiên cứu có thể nhóm chúng thành các cụm có liên quan nhân quả bằng cách truy vết sự tương tác của chúng. Điều này giúp xây dựng một "sơ đồ đấu dây" của quá trình tính toán bên trong AI.
Mô hình thực sự suy luận theo nhiều bước
Khi áp dụng vào thực tế, chúng ta có thể quan sát thấy các mô hình thực hiện suy luận đa bước thực sự thông qua các khái niệm trung gian. Thậm chí, mô hình còn có khả năng "nghĩ trước" về các từ vần kết hợp khi lên kế hoạch viết một bài thơ.
Ví dụ, khi bạn hỏi: "Thủ phủ của bang chứa thành phố Dallas là gì?", quá trình diễn ra bên trong sẽ theo trình tự sau:
- Đặc điểm về "Dallas" được kích hoạt.
- Điều này khiến đặc điểm về "Texas" sáng lên.
- Sau đó, đặc điểm về "Austin" (thủ phủ của Texas) được kích hoạt.
Rõ ràng, đây là quá trình truy vết các mối quan hệ ngữ nghĩa giữa các khái niệm cấp cao. Qua đó, mô hình đang thực hiện một loại suy luận mang tính biểu tượng (pseudo-symbolic inference), tương tự như cách con người tư duy logic.
 Quá trình suy luận đa bước từ Dallas đến Austin
Quá trình suy luận đa bước từ Dallas đến Austin
Không chỉ riêng LLM
Hiện tượng này không giới hạn ở các mô hình ngôn ngữ. Các hệ thống dựa trên MCTS như AlphaZero cũng hội tụ về các khái niệm mà con người nhận biết được.
DeepMind đã chỉ ra vào năm 2022 rằng AlphaZero đã tự học được các biểu diễn trung gian tương đồng với các khái niệm cờ vua của con người như "chiếu tướng" (check) hoặc "chốt quân" (pinning) — hoàn toàn tự động mà không cần kiến thức cờ vua từ con người.
Hiểu sâu hơn để tạo ra thuật toán tốt hơn
Việc phân tích quá trình suy luận ngầm định của mô hình có thể giúp chúng ta thiết kế các thuật toán học tốt hơn.
Ví dụ điển hình là Claude 3.5 Haiku. Mô hình này đã tự học một thuật toán để cộng các số nguyên nhỏ không hoàn toàn giống với cách tính nhẩm của con người. Nó chia bài toán thành nhiều đường song song — tính toán độ lớn sơ bộ cùng với các chữ số chính xác — sau đó kết hợp lại, dựa vào các đặc điểm "bảng tra cứu" đã ghi nhớ.
Câu hỏi tự nhiên được đặt ra là: Liệu chúng ta có thể xác định được điều này và sau đó "hướng dẫn" mô hình hướng tới một thuật toán tốt hơn hay không?
Mô hình có một "tiềm thức"
Đáng chú ý là chính mô hình đó không nhất thiết phải có sự nhận thức siêu nhận thức (metacognitive insight) về quy trình tư duy bên dưới mà kỹ thuật truy vết mạch phát hiện ra. Nếu bạn yêu cầu nó giải thích cách nó cộng hai số, nó sẽ tường thuật một quy trình gọn gàng theo kiểu con người — chứ không phải là thuật toán thực sự mà nó đã chạy.
Dù tốt hay xấu, mô hình có một mức độ "tiềm thức" nhất định. Và chính điều đó cho phép chúng ta nhìn sâu vào bên trong.
Tại sao điều này quan trọng?
Giải thích cơ chế là một lĩnh vực nghiên cứu phát triển nhanh chóng và đầy thú vị. Trái ngược với những gì các giáo sư ML có thể nói một thập kỷ trước, ở một khía cạnh nào đó, đây là lúc chúng ta có được cái nhìn sâu sắc nhất từ một mô hình.
Những hàm ý của việc này là rất lớn — từ việc xác định hành vi sai lệch của mô hình, điều khiển hướng đi, cho đến việc thiết kế các thuật toán học tốt hơn trong tương lai.
Bài viết liên quan

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026

Công nghệ
Enhanced Games: Khi thể thao gặp gỡ xu hướng Biohacking và công nghệ sống thọ
22 tháng 5, 2026