
Mô hình Bradley-Terry: Khi sự lựa chọn đối đầu trở nên chính xác hơn điểm số tuyệt đối
Mô hình Bradley-Terry là một phương pháp thống kê mạnh mẽ giúp chuyển đổi các dữ liệu so sánh cặp thành bảng xếp hạng xác suất. Bài viết này sẽ đi sâu vào cơ chế hoạt động, lợi ích so với việc chấm điểm thủ công, và các ứng dụng thực tế trong đánh giá AI như Chatbot Arena.
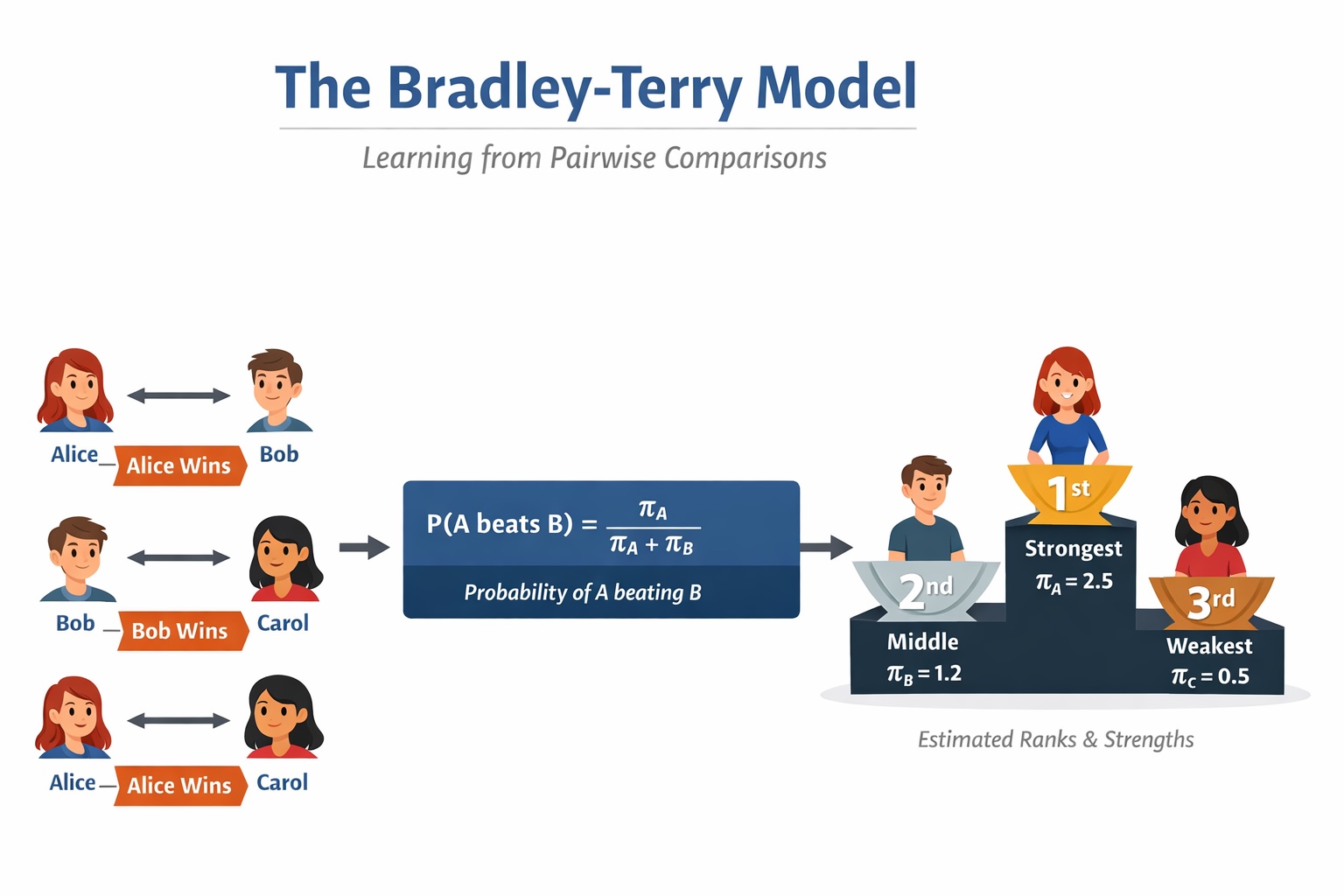
Trong lĩnh vực học máy và khoa học dữ liệu, chúng ta thường giả định rằng dữ liệu đầu vào là các nhãn tuyệt đối. Ví dụ, một tài liệu được nhận một điểm số cụ thể, hoặc một sản phẩm được đánh giá trên thang điểm cố định. Tuy nhiên, trong thực tế, phán đoán của con người thường xuất hiện dưới dạng so sánh và địa phương hơn. Con người có thể lưỡng lự khi đưa ra một điểm số chất lượng tuyệt đối như 7.4/10, nhưng lại thường dễ dàng nói rằng câu trả lời A tốt hơn câu trả lời B.
Đây chính là bối cảnh mà Mô hình Bradley-Terry trở nên đặc biệt hữu ích. Thay vì yêu cầu các đánh giá tuyệt đối khó đạt được, mô hình này cung cấp một cách tiếp cận toán học sạch sẽ để học hỏi từ các sự ưu tiên cặp (pairwise preferences). Nó bắt đầu từ các kết quả đối đầu đơn giản và sử dụng chúng để suy ra một thứ tự tiềm ẩn giữa các mục, từ đó tạo ra một bảng xếp hạng xác suất mạch lạc.
Ý tưởng cốt lõi: Mỗi mục đều có một sức mạnh tiềm ẩn
Mô hình bắt đầu với một giả định đơn giản: Mỗi mục $i$ được liên kết với một tham số sức mạnh tiềm ẩn dương, ký hiệu là $\pi_i > 0$. Khi mục $i$ được so sánh với mục $j$, xác suất để $i$ được ưu tiên hơn $j$ được định nghĩa là:
$$P(i \succ j) = \frac{\pi_i}{\pi_i + \pi_j}$$
Dạng thức này rất hấp dẫn vì nó vừa đơn giản vừa dễ hiểu. Nếu hai mục có sức mạnh bằng nhau, mỗi mục có xác suất thắng là 1/2. Nếu $\pi_i$ lớn hơn nhiều so với $\pi_j$, thì $i$ có khả năng thắng cao hơn. Mô hình Bradley-Terry chuyển hóa các sức mạnh tương đối tiềm ẩn thành các xác suất quan sát được.
Một cách viết khác thường thuận tiện hơn là biểu diễn sức mạnh dương dưới dạng lũy thừa của một điểm số thực: $\pi_i = \exp(\beta_i)$. Khi đó, xác suất trở thành:
$$P(i \succ j) = \frac{\exp(\beta_i)}{\exp(\beta_i) + \exp(\beta_j)} = \sigma(\beta_i - \beta_j)$$
Trong đó $\sigma$ là hàm logistic. Điều này cho thấy một thực tế quan trọng: Xác suất $i$ thắng $j$ chỉ phụ thuộc vào hiệu số $\beta_i - \beta_j$. Điều này liên kết mật thiết mô hình Bradley-Terry với hồi quy logistic (logistic regression).
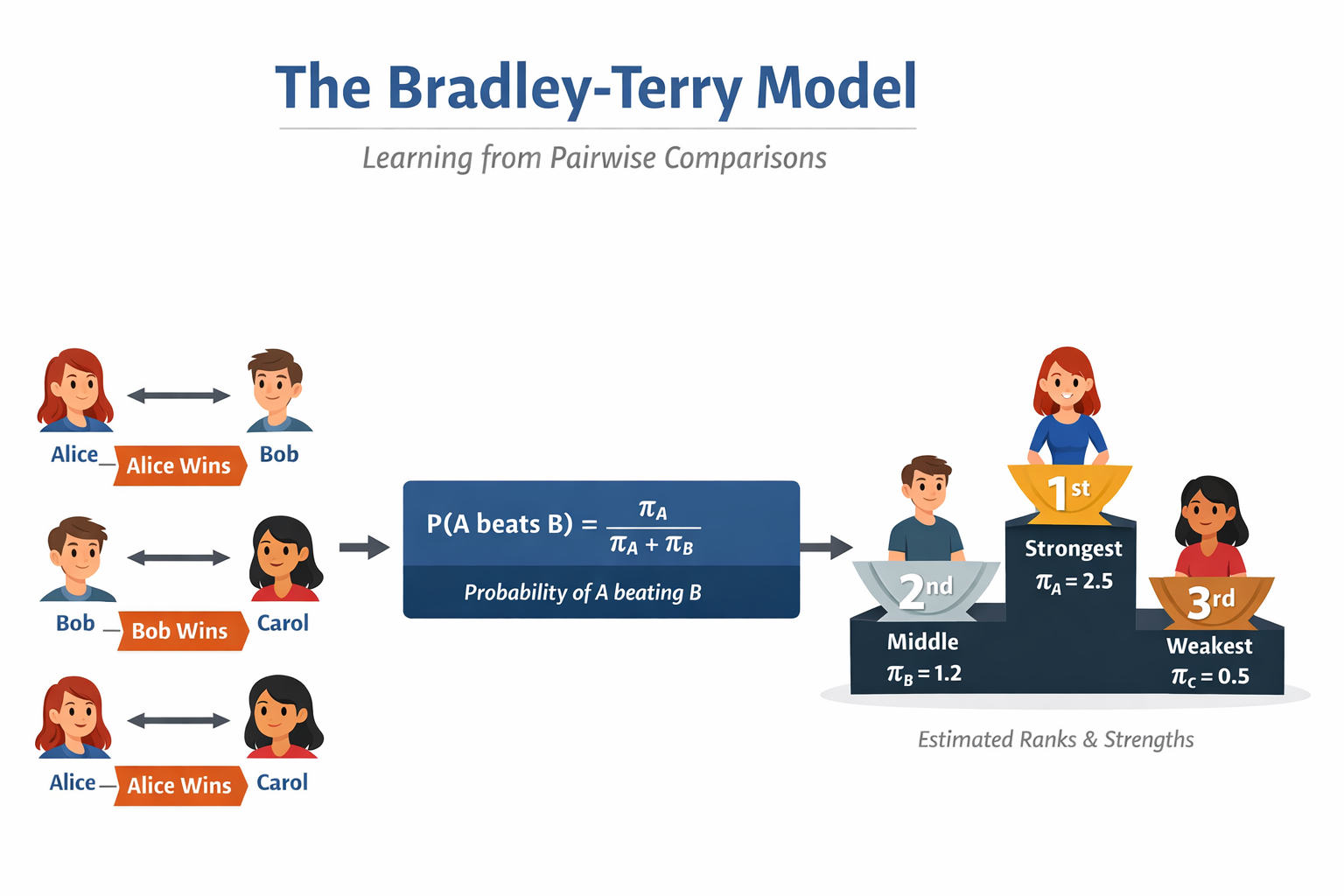 Mô hình Bradley-Terry học các sức mạnh tiềm ẩn từ các so sánh cặp
Mô hình Bradley-Terry học các sức mạnh tiềm ẩn từ các so sánh cặp
Tại sao so sánh cặp thường tốt hơn điểm số trực tiếp
Một trong những ưu điểm thực tế chính của bối cảnh Bradley-Terry là các phán đoán cặp thường dễ dàng hơn cho con người so với các đánh giá tuyệt đối. Về mặt nhận thức, việc hỏi "câu trả lời A có tốt hơn B không?" là một so sánh địa phương. Trong khi đó, việc hỏi "câu trả lời A có xứng đáng 7.8/10 điểm không?" đòi hỏi một tiêu chuẩn nội bộ, hiệu chuẩn với các ví dụ trước đó và sự hiểu biết ổn định về ý nghĩa của thang điểm số.
Sự khác biệt này rất quan trọng vì nhiễu trong giám sát không phải lúc nào cũng giống nhau. Các điểm số trực tiếp thường gặp vấn đề về sự không nhất quán của thang đo. Một người đánh giá có thể sử dụng toàn bộ phạm vi từ 1 đến 10, trong khi người khác nén hầu hết các phán đoán vào khoảng từ 6 đến 8. Các so sánh cặp tránh được nhiều khó khăn này bằng cách không yêu cầu người đánh giá neo giá trị vào một khung số học toàn cầu.
Khớp mô hình từ dữ liệu
Giả sử rằng các so sánh được lặp lại nhiều lần trên một tập hợp các mục lớn. Đối với mỗi cặp có thứ tự $(i, j)$, hãy ký hiệu $w_{ij}$ là số lần mục $i$ thắng mục $j$. Mô hình Bradley-Terry khớp các tham số bằng cách chọn các giá trị sức mạnh làm cho dữ liệu so sánh quan sát được có khả năng xảy ra nhất (Maximum Likelihood Estimation).
Về mặt trực quan, quá trình tối ưu hóa điều chỉnh sức mạnh tiềm ẩn sao cho xác suất dự đoán của mô hình phù hợp với kết quả so sánh thực nghiệm. Nếu một mục thắng thường xuyên hơn mức mô hình dự đoán, sức mạnh của nó sẽ tăng lên. Ngược lại, nếu nó thua thường xuyên hơn dự đoán, sức mạnh sẽ giảm.
Quá trình học tập tiếp tục bằng cách liên tục sửa chữa các sự khác biệt này cho đến khi kết quả mong đợi của mô hình được đưa vào sự phù hợp càng gần càng tốt với dữ liệu quan sát.
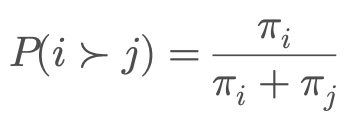 Quá trình tối ưu hóa điều chỉnh sức mạnh tiềm ẩn
Quá trình tối ưu hóa điều chỉnh sức mạnh tiềm ẩn
Mở rộng theo ngữ cảnh: Khi sức mạnh phụ thuộc vào bối cảnh
Mô hình Bradley-Terry chuẩn gán một sức mạnh tiềm ẩn duy nhất cho mỗi mục. Tuy nhiên, trong thực tế, sức mạnh của một mục thường phụ thuộc vào hoàn cảnh của sự so sánh. Một mô hình ngôn ngữ có thể hoạt động tốt trong lập trình nhưng kém trong viết văn sáng tạo.
Mô hình Bradley-Terry theo ngữ cảnh (Contextual Bradley-Terry) giải quyết vấn đề này bằng cách cho phép sức mạnh tiềm ẩn thay đổi như một hàm của các hiệp biến quan sát được. Thay vì một tham số cố định $\beta_i$, chúng ta viết:
$$\beta_i = w^T x_i$$
Trong đó $x_i$ là vector đặc trưng liên quan đến mục $i$ trong bối cảnh so sánh hiện tại, và $w$ là vector hệ số được chia sẻ. Điều này biến mô hình thành một bài toán hồi quy logistic trên sự khác biệt của các vector đặc trưng.
Ứng dụng thực tế: Chatbot Arena
Ứng dụng đương đại nổi bật nhất của mô hình Bradley-Terry theo ngữ cảnh là LMSYS Chatbot Arena. Đây là một nền tảng đánh giá các mô hình ngôn ngữ lớn (LLM) thông qua sự đóng góp của cộng đồng. Người dùng gửi câu hỏi, nhận phản hồi từ hai mô hình ẩn danh và chỉ ra phản hồi nào họ ưu tiên.
Thách thức mà Arena gặp phải là việc xếp hạng ngây thơ coi tất cả các so sánh đều cung cấp thông tin như nhau. Trong thực tế, các câu hỏi dễ tạo ra kết quả khó phân biệt, trong khi các câu hỏi khó mới làm lộ ra sự khác biệt về chất lượng. Arena giải quyết điều này bằng cách kết hợp các hiệp biến cấp độ câu hỏi (độ khó, chủ đề) vào khuôn khổ Bradley-Terry, cho phép ước định xếp hạng cụ thể theo ngữ cảnh cho từng mô hình.
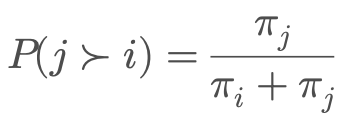 Ứng dụng Bradley-Terry trong đánh giá mô hình ngôn ngữ
Ứng dụng Bradley-Terry trong đánh giá mô hình ngôn ngữ
Xử lý người đánh giá ồn ào: CrowdBT
Mô hình Bradley-Terry giả định rằng mọi so sánh quan sát được đều là một lần rút ra đáng tin cậy từ phân phối xác suất của mô hình. Tuy nhiên, trong các bối cảnh crowdsourcing, chất lượng các phán đoán cá nhân thay đổi rất lớn.
Mô hình CrowdBT giải quyết vấn đề này bằng cách ước tính đồng thời cả sức mạnh của mục và độ tin cậy của người đánh giá. Ý tưởng chính là giới thiệu một tham số độ tin cậy $\rho_k \in [0, 1]$ cho mỗi người đánh giá. Xác suất so sánh được mô hình hóa như một hỗn hợp: với xác suất $\rho_k$, người đánh giá quan sát kết quả thật và báo cáo đúng; với xác suất $1 - \rho_k$, họ đưa ra câu trả lời ngẫu nhiên.
Thuật toán EM (Expectation-Maximization) được sử dụng để tối ưu hóa. Kết quả là một tập hợp các sức mạnh mục đã được khử nhiễu bằng cách giảm trọng số của những người đánh giá không đáng tin cậy, cùng với các điểm độ tin cậy có thể dùng để kiểm soát chất lượng.
Kết luận
Mô hình Bradley-Terry chuẩn cung cấp một khuôn khổ sạch sẽ để học hỏi từ các so sánh cặp. Các mở rộng như Bradley-Terry theo ngữ cảnh và CrowdBT biến nó từ một công cụ xếp hạng đơn giản thành một khuôn khổ phong phú, có khả năng xử lý các phức tạp của đánh giá so sánh trong thế giới thực. Đối với các kỹ sư dữ liệu và nhà phát triển AI, việc hiểu rõ mô hình này là chìa khóa để xây dựng các hệ thống đánh giá hiệu quả dựa trên phản hồi của con người.
Bài viết liên quan

Công nghệ
Ngay sau khi phát hành trái phiếu, Amazon vay thêm 17,5 tỷ USD từ ngân hàng để thúc đẩy chi tiêu AI
10 tháng 6, 2026

Công nghệ
Startup Battlefield 200: Cổng đăng ký chính thức đóng cửa trong 3 ngày tới
05 tháng 6, 2026

Công nghệ
Sự trở lại của Xbox: Chiến lược mới, thay đổi nhân sự và tương lai Project Helix
07 tháng 5, 2026