
Mô hình VLA: Khi Robot học cách nhìn, hiểu và hành động
Bài viết này khám phá cơ chế hoạt động và nền tảng toán học của các mô hình Visual-Language-Action (VLA) - công nghệ cốt lõi giúp robot hình người hiểu và tương tác với thế giới thực. Chúng ta sẽ đi sâu vào kiến trúc neural, các chiến lược tạo hành động và quy trình huấn luyện từ dữ liệu mô phỏng đến thực tế.

Làm thế nào một robot có thể phân biệt được nho khô, ớt xanh và lọ muối? Quan trọng hơn, nó làm sao để biết cách gấp một chiếc áo thun một cách nhuần nhuyễn? Đó chính là phép màu của các mô hình Visual-Language-Action (VLA).
Bài viết này là bản tóm tắt ngắn gọn về các mô hình VLA hiện đại, được chắt lọc từ phân tích meta của các mô hình hàng đầu hiện nay cùng các khái niệm toán học liên quan. Để hiểu rõ về VLA, chúng ta cần nắm vững một số khái niệm nền tảng của việc điều khiển robot đa phương thức dựa trên dữ liệu (data-driven multimodal robotic control).
 Mô hình VLA kết nối thị giác và hành động
Mô hình VLA kết nối thị giác và hành động
Các giả thuyết hữu ích về trí tuệ nhân tạo
Trước khi đi sâu vào kỹ thuật, có hai giả thuyết quan trọng giúp chúng ta hiểu rõ hơn về cách các tác nhân (agents) tương tác với thế giới.
Học biểu diễn tiềm ẩn (Latent representation learning) có thể là nền tảng của trí tuệ Các mô hình ngôn ngữ lớn (LLM) hay các mô hình Transformer khác không thực sự học ngữ pháp của tiếng Anh hay bất kỳ ngôn ngữ nào. Thay vào đó, chúng học một biểu diễn (embedding): một bản đồ chiếu các token hoặc quan sát đã lượng tử hóa thành các biểu diễn có ý nghĩa ngữ nghĩa trong không gian tiềm ẩn N chiều. Các nhà nghiên cứu hàng đầu như Yann LeCun cũng lập luận rằng trí tuệ cấp độ con người đòi hỏi các "Mô hình thế giới" (World Models) hoạt động trong không gian tiềm ẩn thay vì không gian điểm ảnh, giúp robot có khả năng suy luận nhân quả.
Sự bắt chước là nền tảng cho sự di chuyển hiệu quả của robot Tại sao robot lại mất nhiều thời gian để học đi lại đúng cách? Thiếu các kiến thức tiên quyết (priors) từ chuyên gia. Việc thêm một thành phần "mất mát bắt chước" (imitation loss) vào hàm mục tiêu giúp robot di chuyển mượt mà hơn và tổng quát hóa tốt hơn sang các môi trường mới, so với việc chỉ dùng học tăng cường (reinforcement learning) thuần túy.
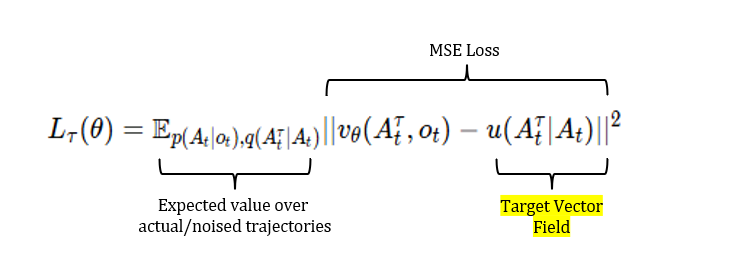 Robot học hỏi qua quan sát và hành động
Robot học hỏi qua quan sát và hành động
Vai trò của Điều khiển từ xa (Teleoperation)
Điều khiển từ xa (Teleoperation) đóng vai trò rõ ràng trong việc huấn luyện các robot hình người mới nhất. Thay vì để robot cố gắng tạo ra đầu ra điều khiển từ đầu (dẫn đến các chuyển động giật cục), chúng ta tăng cường tối ưu hóa chính sách với các mẫu từ tập dữ liệu mượt mà, đại diện cho quỹ đạo hành động chính xác do con người thực hiện qua teleoperation.
Điều này có nghĩa là khi robot học các biểu diễn nội bộ của quan sát thị giác, một chuyên gia có thể cung cấp dữ liệu điều khiển chính xác. Khi được nhắc "di chuyển vật A đến B", robot không chỉ học một chính sách ngẫu nhiên mạnh mẽ mà còn có thể sao chép các kiến thức tiên nghiệm về sự bắt chước.
Nền tảng toán học của VLA
Mặc dù VLA có vẻ phức tạp, tại cốt lõi của nó, mô hình VLA được giảm xuống thành một bài toán học chính sách có điều kiện đơn giản. Chúng ta muốn một hàm $f(x)$ - thường được ký hiệu dưới dạng chính sách $\pi_\theta$ - ánh xạ những gì robot "thấy" và "nghe" (bằng ngôn ngữ tự nhiên) thành những gì nó nên "làm".
Về mặt toán học, hãy xem xét một robot hoạt động trong Quy trình quyết định Markov có thể quan sát một phần (POMDP). Tại mỗi bước thời gian $t$:
- Robot nhận một quan sát $o_t$ (thường là hình ảnh RGB và trạng thái nội cảm như góc khớp).
- Robot nhận một lệnh ngôn ngữ $l$ (ví dụ: "nhắp chai coke và di chuyển sang trái").
- Robot phải tạo ra một hành động $a_t$ (thường là vector thay đổi của bộ tác nhân cuối và lệnh kẹp).
Nhiệm vụ của VLA là học một chính sách $\pi_\theta(a_t | o_t, l)$ tối đa hóa xác suất thành công của nhiệm vụ.
Không gian hành động và Chiến lược tạo hành động
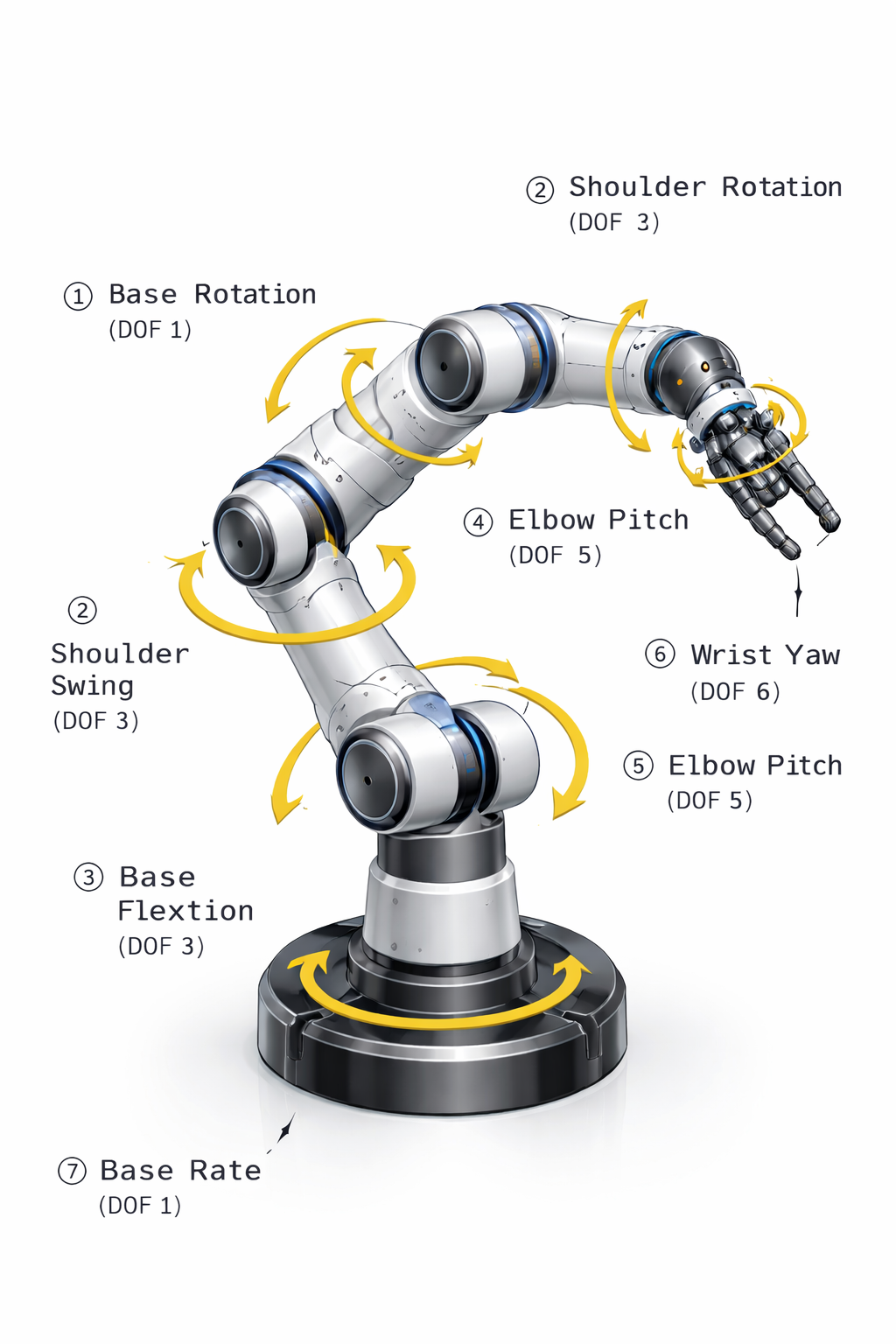
Một tay thao tác robot đơn lẻ thường có 7 bậc tự do (DoF) và 1 DoF cho bộ kẹp, tạo ra một không gian 8 chiều. Lệnh điều khiển được biểu diễn dưới dạng các vectơ liên tục. Để tạo ra các hành động này từ các biểu diễn nội bộ, các mô hình hiện đại sử dụng một trong ba chiến lược sau:
Chiến lược #1: Mã hóa hành động thành Token (Action Tokenization) Ý tưởng là lượng tử hóa mỗi chiều hành động thành $K$ khối đồng nhất (thường $K=256$). Mỗi chỉ số khối trở thành một token được thêm vào từ vựng của mô hình ngôn ngữ. Mô hình dự đoán chúng tự hồi quy (autoregressively), giống như việc huấn luyện GPT. Cách tiếp cận này được sử dụng hiệu quả trong RT-2 và OpenVLA. Tuy nhiên, đối với các nhiệm vụ điều khiển chính xác, việc lượng tử hóa để lại "lỗi lượng tử hóa" không thể phục hồi dễ dàng, dẫn đến các chính sách điều khiển giật cục.
Chiến lược #2: Đầu ra hành động dựa trên Diffusion Thay vì lượng tử hóa, ta giữ hành động liên tục và mô hình phân phối có điều kiện $p(a_t | o_t, l)$ bằng quy trình khử nhiễu diffusion. Phương pháp này tỏa sáng khi phân phối hành động là đa phương thức (ví dụ: có nhiều cách hợp lệ để cầm một vật thể). Mô hình diffusion học cách loại bỏ nhiễu từ một vectơ nhiễu ban đầu để tạo ra hành động liên tục và ngẫu nhiên.
Chiến lược #3: Khớp dòng chảy (Flow Matching) Đây là kế thừa của diffusion, cũng tìm thấy chỗ đứng trong điều khiển robot. Thay vì khử nhiễu ngẫu nhiên, mô hình khớp dòng chảy học một trường vận tốc, xác định cách di chuyển một mẫu từ nhiễu đến phân phối mục tiêu. Phương pháp này học được trường vectơ $V_\theta$ và sử dụng quy tắc tích hợp Euler để di chuyển tăng dần từ nhiễu đến các mẫu hành động liên tục sạch. Cách tiếp cận này nhanh hơn và chính xác hơn, được sử dụng trong các mô hình như $\pi0$.
 Kiến trúc Neural và quy trình huấn luyện
Kiến trúc Neural và quy trình huấn luyện
Kiến trúc Neural trong thực tế
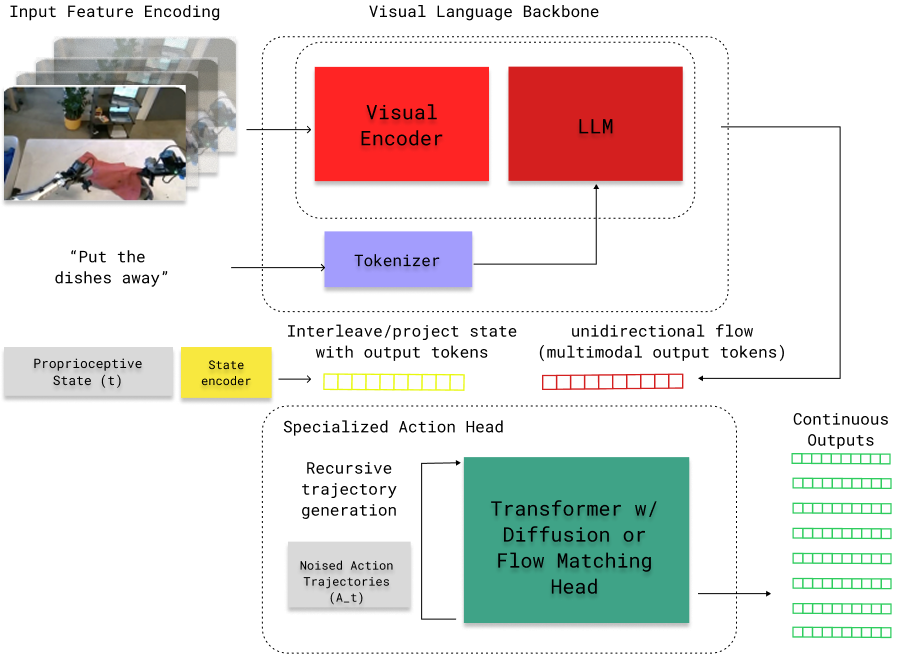
Kiến trúc tổng hợp này được rút ra từ các mô hình VLA hàng đầu như OpenVLA, NVIDIA GR00t, $\pi0.5$ và Figure Helix 02.
Mã hóa đầu vào
- Hình ảnh: Được xử lý bởi bộ mã hóa thị giác tiền huấn luyện (như SigLIP hoặc ViT), chuyển đổi điểm ảnh thành các token thị giác.
- Ngôn ngữ: Lệnh được token hóa (ví dụ: SentencePiece), tạo ra chuỗi các nhúng token. Trong một số trường hợp, các nhúng này chia sẻ không gian tiềm ẩn với các token thị giác.
Xương sống VLM Các token thị giác và ngôn ngữ được nối lại thành một chuỗi duy nhất và đưa qua xương sống mô hình ngôn ngữ tiền huấn luyện đóng vai trò là bộ suy luận đa phương thức. Mục đích chính là tạo ra các biểu diễn trung gian có ý nghĩa ngữ nghĩa.
Đầu ra hành động (Action Heads) Biểu diễn kết hợp được giải mã thành hành động thông qua một trong ba chiến lược đã nêu (tokenization, diffusion, hoặc flow matching). Các hành động này thường được dự đoán dưới dạng các khối hành động (action chunks) - một đường chân trời ngắn của các hành động tương lai - giúp robot thực hiện chuyển động mượt mà và nhất quán.
Cách VLA được huấn luyện
Các mô hình VLA hiện đại không học từ số 0. Chúng thừa hưởng hàng tỷ tham số kiến thức từ các thành phần tiền huấn luyện:
- Bộ mã hóa thị giác được huấn luyện trên các tập dữ liệu hình ảnh-văn bản quy mô internet.
- Xương sống mô hình ngôn ngữ được huấn luyện trên hàng nghìn tỷ token văn bản.
Giai đoạn 1: Tiền huấn luyện (Pretraining) VLA được huấn luyện trên các tập dữ liệu trình diễn robot quy mô lớn (ví dụ: Open X-Embodiment với hơn 1 triệu quỹ đạo robot). Mục tiêu là học ánh xạ nền tảng từ các quan sát đa phương thức sang các biểu diễn liên quan đến hành động có thể chuyển đổi qua các nhiệm vụ và môi trường khác nhau.
Giai đoạn 2: Huấn luyện sau (Post-training) Mục tiêu là chuyên biệt hóa mô hình tiền huấn luyện thành một chính sách cụ thể cho nhiệm vụ và kiểu robot (embodiment) có thể hoạt động trong môi trường thực tế. Giai đoạn này tinh chỉnh chính sách với các yêu cầu chính xác, bao gồm ánh xạ các quỹ đạo hành động dự đoán thành các lệnh khớp chính xác của nền tảng robot cụ thể.
Kết luận
Các mô hình Visual-Language-Action (VLA) rất quan trọng vì chúng thống nhất nhận thức, suy luận và điều khiển thành một hệ thống học duy nhất. Thay vì xây dựng các đường ống riêng biệt cho thị giác, lập kế hoạch và truyền động, VLA ánh xạ trực tiếp những gì robot thấy và nghe được thành những gì nó nên làm.
Đây có thể được coi là sự hiện thực hóa sớm của ý tưởng về "trí tuệ hiện thân" (embodied intelligence), nơi nhận thức, suy luận và tạo hành động được kết nối chặt chẽ với nhau và với môi trường vật lý.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026