
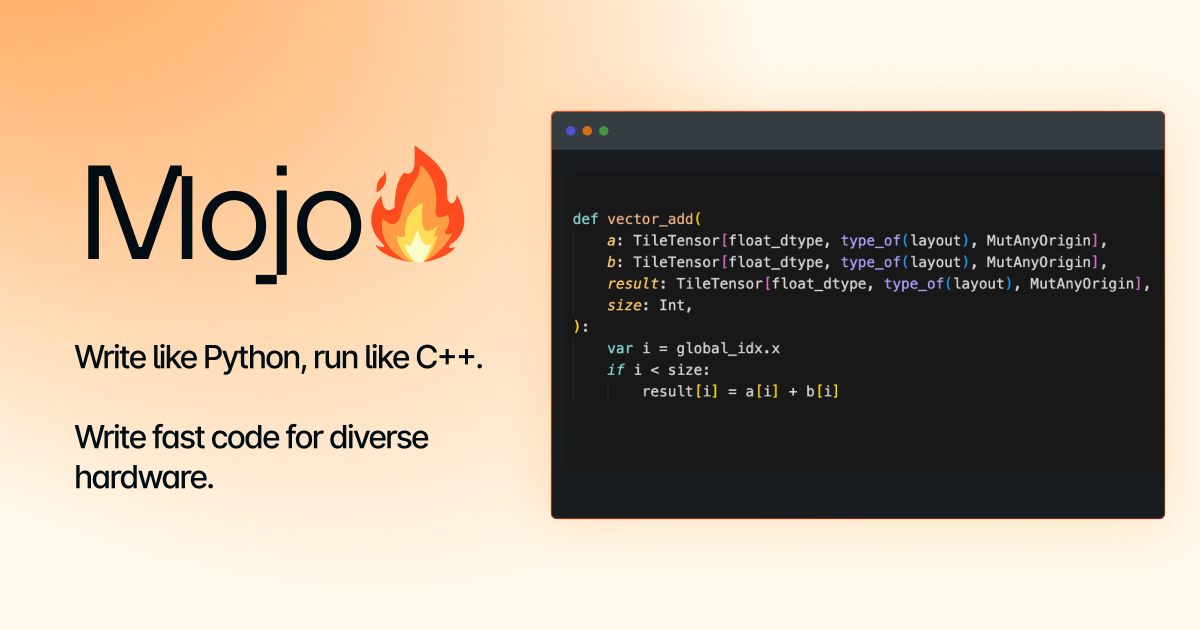
Mojo 1.0 Beta ra mắt: Siết chặt khoảng cách giữa Python và hiệu năng phần cứng
Mojo 1.0 Beta đã chính thức được phát hành, mang đến một ngôn ngữ lập trình mới kết hợp cú pháp dễ dùng của Python với hiệu năng và khả năng kiểm soát bộ nhớ của Rust. Ngôn ngữ này được thiết kế đặc biệt để tối ưu hóa cho các phần cứng AI đa dạng, cho phép lập trình viên viết mã tốc độ cao cho CPU và GPU mà không bị phụ thuộc vào nhà cung cấp.
 Mojo Logo
Mojo Logo
Ngôn ngữ lập trình Mojo đã đánh dấu cột mốc quan trọng với việc ra mắt phiên bản 1.0.0 Beta 1. Đây được xem là một bước tiến đột phá trong lĩnh vực phát triển phần mềm, đặc biệt là đối với cộng đồng AI và lập trình hệ thống, hứa hẹn giải quyết bài toán khó khăn lâu nay: cân bằng giữa năng suất của lập trình viên và hiệu suất thô của phần cứng.
Mojo được xây dựng với mục tiêu "viết mã nhanh cho phần cứng đa dạng, từ CPU đến GPU, mà không bị phụ thuộc vào nhà cung cấp (vendor lock-in)". Nó lấy cảm hứng từ những điểm mạnh nhất của các ngôn ngữ hiện đại: cú pháp trực quan của Python, an toàn bộ nhớ của Rust, và khả năng lập trình biên dịch (compile-time metaprogramming) mạnh mẽ của Zig.
Tại sao Mojo lại quan trọng?
 Mojo Dark Logo
Mojo Dark Logo
Trong bối cảnh AI đang bùng nổ, nhu cầu về hiệu năng tính toán ngày càng cao. Mojo ra đời để tận dụng tối đa phần cứng đa dạng đang vận hành các hệ thống AI hiện đại. Là một ngôn ngữ được biên dịch (compiled) và có kiểu tĩnh (statically-typed), Mojo lý tưởng cho việc lập trình tác tử (agentic programming) nơi tốc độ xử lý là yếu tố sống còn.
Điểm khác biệt lớn nhất của Mojo là triết lý "không còn phải chọn giữa năng suất và hiệu suất". Người dùng có thể bắt đầu với các mô hình lập trình đơn giản và quen thuộc, sau đó tăng thêm độ phức tạp khi cần thiết để tối ưu hóa hiệu năng.
Lập trình GPU trở nên dễ dàng hơn
Một trong những trở ngại lớn nhất khi lập trình hiệu năng cao là việc tối ưu hóa cho GPU. Mojo giúp việc này trở nên dễ tiếp cận với tất cả mọi người. Bạn không cần các thư viện riêng biệt của từng nhà sản xuất hay mã phải biên dịch riêng biệt. Với Mojo, bạn có thể viết các nhân GPU (GPU kernels) hiệu năng cao ngay trong chính ngôn ngữ mà bạn sử dụng cho CPU.
Tương thích hoàn toàn với Python
Mojo không yêu cầu các nhà phát triển bỏ qua toàn bộ mã nguồn cũ. Nó tương tác trực tiếp với Python, cho phép bạn loại bỏ các nút thắt hiệu năng trong mã hiện có mà không cần viết lại tất cả mọi thứ.
Bạn có thể bắt đầu chỉ với một hàm, rồi mở rộng quy mô để chuyển mã quan trọng về hiệu năng vào Mojo. Mã Mojo của bạn sẽ được nhập tự nhiên vào Python và đóng gói cùng nhau để phân phối. Ngược lại, bạn cũng có thể nhập các thư viện từ hệ sinh thái Python vào mã Mojo của mình.
Metaprogramming và tương lai mã nguồn mở
Hệ thống metaprogramming của Mojo sử dụng cùng một ngôn ngữ với mã thời gian chạy (run-time code), cung cấp một hệ thống trực quan để tối đa hóa hiệu năng. Bạn có thể xây dựng các tối ưu hóa cụ thể cho phần cứng thông qua biên dịch có điều kiện, đảm bảo an toàn bộ nhớ với đánh giá thời gian biên dịch, và loại bỏ các nhánh runtime tốn kém.
Hiện tại, thư viện chuẩn của Mojo đã mã nguồn mở hoàn toàn trên GitHub và nhóm phát triển chào đón các đóng góp. Dự kiến, trình biên dịch Mojo sẽ được mã nguồn mở vào năm 2026.
Vì ngôn ngữ vẫn còn rất trẻ, đội ngũ Mojo tin rằng một nhóm kỹ sư gắn kết với tầm nhìn chung sẽ di chuyển nhanh hơn là một nỗ lực do cộng đồng lái xe ở giai đoạn này. Tuy nhiên, họ cam kết mã nguồn mở toàn bộ Mojo trong tương lai.
"Mojo ra đời vào cuối năm 2022 và đã đi một chặng đường dài, nhưng vẫn còn rất nhiều việc phải làm," - đại diện Mojo chia sẻ.
Nếu bạn quan tâm đến việc học lập trình GPU hoặc muốn cải thiện hiệu năng cho các dự án AI của mình, Mojo 1.0 Beta là một nền tảng hứa hẹn đáng để khám phá ngay từ bây giờ.
Bài viết liên quan
Công nghệ
Open Terminal: Ứng dụng phong cách Bloomberg giúp dân đầu tư cá nhân tiếp cận dữ liệu tài chính chuyên sâu
04 tháng 6, 2026

Phần mềm
Triển khai mảng động trong C: Không cần Struct, không lưu trữ dung lượng
13 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026