
Năm cách tinh chỉnh Chronos-2: Tối ưu hóa mô hình nền tảng chuỗi thời gian
Bài viết này khám phá năm phương pháp tinh chỉnh (fine-tune) Chronos-2, một mô hình nền tảng chuỗi thời gian, nhằm vượt qua các giới hạn của khả năng dự báo zero-shot. Thông qua một nghiên cứu thực tế về dự báo nhu cầu điện của tòa nhà, tác giả chứng minh cách các kỹ thuật như LoRA và tích hợp biến ngoại sinh giúp cải thiện đáng kể độ chính xác.

Trong phần đầu của loạt bài này, chúng tôi đã giới thiệu về Chronos-2, một mô hình nền tảng (foundation model) dành cho chuỗi thời gian. Chúng ta đã thực hành qua một nghiên cứu tình huống thực tế và thấy được khả năng của Chronos-2 ngay khi sử dụng "nguyên bản" mà không cần huấn luyện thêm.
Tuy nhiên, như đã đề cập ở phần kết của phần 1, khả năng zero-shot (không cần huấn luyện trước) không phải lúc nào cũng đủ lý tưởng. Trong các trường hợp dữ liệu của bạn khác biệt so với dữ liệu huấn luyện ban đầu, mô hình liên tục mắc lỗi hệ thống, hoặc bạn có lượng lớn dữ liệu lịch sử phong phú, thì fine-tuning (tinh chỉnh) chính là bước tiếp theo tất yếu.
Bài viết này sẽ tiếp tục nghiên cứu tình huống về dự báo nhu cầu điện tiêu thụ của tòa nhà từ phần 1, đồng thời hướng dẫn qua năm kịch bản tinh chỉnh Chronos-2 khác nhau.
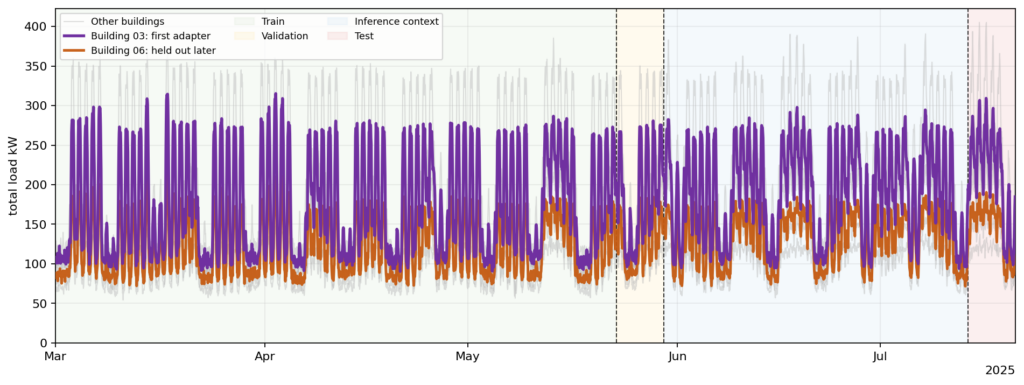 Tổng quan dữ liệu tinh chỉnh
Tổng quan dữ liệu tinh chỉnh
Tóm tắt nghiên cứu tình huống
Chúng ta nhanh chóng xem lại thiết lập từ phần 1. Bộ dữ liệu tổng hợp bao gồm 8 tòa nhà thương mại ghi lại nhu cầu điện theo giờ. Nhiệm vụ là dự báo tổng tải điện một tuần trước, tức là 168 giờ.
Điểm mới ở phần 2 là chúng ta mô phỏng một khoảng thời gian dài hơn để có đủ dữ liệu tinh chỉnh. Dữ liệu được chia thành bốn cửa sổ liên tục:
- Huấn luyện (Train): 12 tuần.
- Kiểm định (Validation): 1 tuần.
- Ngữ cảnh suy luận (Inference context): 45 ngày.
- Kiểm tra (Test): 1 tuần.
Quá trình tinh chỉnh chỉ nhìn thấy dữ liệu trong tập Train & Validation, đảm bảo không có sự rò rỉ dữ liệu (data leakage).
Tìm hiểu về Fine-tuning và LoRA
Trước khi đi sâu vào thực hành, chúng ta cần hiểu rõ khái niệm tinh chỉnh và công nghệ cụ thể được sử dụng: LoRA (Low-Rank Adaptation).
Fine-tuning là gì?
Fine-tuning nghĩa là chúng ta tiếp tục huấn luyện một mô hình đã được huấn luyện trước (pretrained) trên dữ liệu riêng của mình. Đối với Chronos-2, một mô hình Transformer với 120 triệu tham số, fine-tuning giúp điều chỉnh hành vi của mô hình sao cho phù hợp hơn với dữ liệu cụ thể.
Tuy nhiên, cập nhật toàn bộ 120 triệu tham số là tốn kém về tính toán và lưu trữ, đồng thời dễ dẫn đến quá khớp (overfitting) nếu dữ liệu không đủ lớn. Đây là lúc LoRA phát huy tác dụng.
LoRA hoạt động như thế nào?
Thay vì cập nhật toàn bộ ma trận trọng số, LoRA đóng băng (freeze) mô hình gốc và chỉ học một tập hợp nhỏ các tham số bổ sung để sửa đổi hành vi của nó một chút. Cụ thể, thay vì học một ma trận cập nhật đầy đủ ΔW kích thước lớn, LoRA biểu diễn nó dưới dạng tích của hai ma trận nhỏ hơn nhiều (A và B).
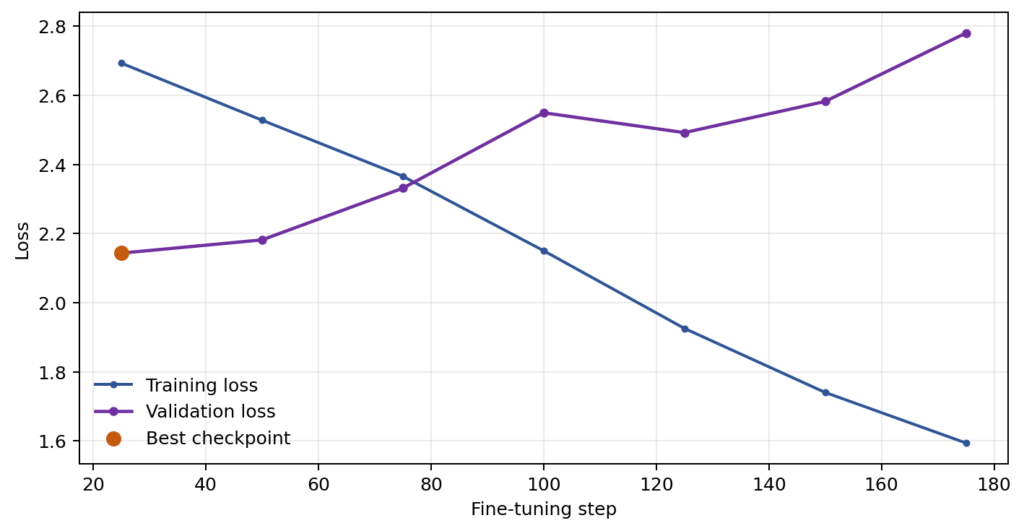 Đồ thị mất mát khi huấn luyện
Đồ thị mất mát khi huấn luyện
Phương pháp này giúp giảm đáng kể việc sử dụng bộ nhớ GPU, kích thước checkpoint và giảm rủi ro quá khớp. Đối với Chronos-2, cấu hình LoRA sẽ thích ứng các lớp chú ý (attention layers) và lớp nhúng bản vá đầu ra (output patch embedding).
Năm kịch bản tinh chỉnh Chronos-2
Dưới đây là năm phương pháp tinh chỉnh được áp dụng cho bộ dữ liệu tòa nhà, sử dụng cùng một mô hình cơ bản và cấu hình LoRA, chỉ khác nhau về dữ liệu đầu vào.
1. Tinh chỉnh cho một tòa nhà đơn lẻ (Single-building adaptation)
Đây là thiết lập đơn giản nhất: chỉ quan tâm đến một tòa nhà (ví dụ: Building 03) và tinh chỉnh mô hình dựa trên dữ liệu lịch sử của riêng tòa nhà đó.
Kết quả cho thấy WAPE (Sai số phần trăm tuyệt đối có trọng số) giảm từ 8.3% (zero-shot) xuống còn 7.6%. Mặc dù có cải thiện, nhưng mức tăng trưởng còn khiêm tốn.
2. Tinh chỉnh danh mục đầu tư (Portfolio fine-tuning)
Thay vì tinh chỉnh riêng lẻ, chúng ta gộp lịch sử của cả 8 tòa nhà để huấn luyện một bộ điều hợp (adapter) dùng chung cho toàn bộ đội tàu (fleet).
Kết quả là tất cả 8 tòa nhà đều thấy sự cải thiện về độ chính xác. Điều này cho thấy các tòa nhà có các mô hình nhu cầu tương tự nhau và bộ điều hợp dùng chung đã học được các mẫu lặp lại chung.
3. Tinh chỉnh có biến ngoại sinh (Covariate-informed fine-tuning)
Cho đến nay, Chronos-2 chỉ nhìn thấy chuỗi mục tiêu (tải điện). Tuy nhiên, chúng ta cũng biết các yếu tố driving như nhiệt độ ngoài trời, tỷ lệ lấp đầy, bức xạ mặt trời và chỉ số cuối tuần.
Trong kịch bản này, chúng ta cung cấp cả biến ngoại sinh (covariates) cho mô hình trong quá trình tinh chỉnh. Kết quả rất ấn tượng: WAPE của Building 03 giảm từ 4.0% xuống còn 2.8% (giảm 30.7% tương đối).
Bài học thực tế ở đây là: đôi khi chiến thắng lớn nhất không chỉ là "fine-tuning", mà là tinh chỉnh mô hình với đúng thông tin.
4. Kết hợp Danh mục và Biến ngoại sinh
Đây là thiết lập phù hợp nhất với nhiều trường hợp sử dụng thực tế. Chúng ta tinh chỉnh trên cả 8 tòa nhà đồng thời cung cấp cả tải điện mục tiêu và các biến ngoại sinh đã biết.
Kết quả: WAPE cơ bản là 8.4%, sau khi tinh chỉnh giảm xuống còn 2.8% (giảm 66.8% tương đối). Đây là sự cải thiện mạnh mẽ nhất.
5. Chuyển giao giữ lại (Held-out transfer)
Câu hỏi đặt ra là: Nếu một tòa nhà mới vừa đi vào hoạt động gần đây, mô hình có thể thích ứng không?
Chúng ta giữ lại Building 06 trong quá trình tinh chỉnh (mô hình không thấy dữ liệu của tòa nhà này), chỉ huấn luyện trên 7 tòa nhà còn lại. Sau đó, áp dụng bộ điều hợp cho Building 06.
Kết quả: WAPE giảm từ 4.2% xuống còn 3.1%. Điều này chứng minh rằng bộ điều hợp có thể học từ các tòa nhà liên quan và cải thiện dự báo ngay cả trên các tài sản mới mà nó chưa từng thấy trong quá trình huấn luyện.
Kết luận
Sau khi đi qua năm kịch bản, mô hình rõ ràng cho thấy hiệu quả vượt trội khi kết hợp tinh chỉnh với các biến ngoại sinh (covariates). Việc cung cấp các tín hiệu tương lai đã biết cho mô hình mang lại lợi ích lớn hơn nhiều so với việc chỉ tinh chỉnh dựa trên chuỗi mục tiêu đơn thuần.
Ngoài ra, khả năng chuyển giao (transfer learning) của các bộ điều hợp được tinh chỉnh trên danh mục đầu tư mở ra cơ hội triển khai mô hình có khả năng mở rộng cao cho các tài sản mới.
Bạn có thể tìm thấy toàn bộ mã nguồn và sổ tay (notebook) chi tiết tại kho GitHub của dự án để áp dụng ngay vào dữ liệu của riêng mình.
Bài viết liên quan

Phần mềm
Apple ra mắt Siri AI: Trợ lý ảo thế hệ mới thông minh hơn và thấu hiểu bạn hơn
08 tháng 6, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
AI & ML
MFA chỉ là bước khởi đầu: Tại sao xác thực thành công vẫn không ngăn chặn được tin tặc?
21 tháng 5, 2026