
Nâng cấp ứng dụng với Generative AI trên AWS: Hành trình từ lý thuyết đến thực hành
Bài viết chia sẻ kinh nghiệm từ khóa học đầu tiên trong chuyên môn DevOps và AI trên AWS của Coursera. Tác giả khám phá cách sử dụng Amazon Bedrock để nâng cấp ứng dụng du lịch, xây dựng Knowledge Base và áp dụng kỹ thuật Prompt Engineering để tạo ra trải nghiệm người dùng động và cá nhân hóa.

Trong bối cảnh bùng nổ của Trí tuệ nhân tạo tạo sinh (Generative AI), việc tìm hiểu cách tích hợp công nghệ này vào quy trình DevOps thực tế đang trở nên cấp thiết hơn bao giờ hết. Gần đây, tôi đã quyết định nâng cao kỹ năng AWS của mình và tìm hiểu sâu hơn về việc tích hợp GenAI vào các hệ thống sản xuất một cách có trách nhiệm thông qua chuyên môn DevOps and AI on AWS Specialization trên Coursera.
Đây là bài viết đầu tiên trong chuỗi series ba phần, nơi tôi chia sẻ những kinh nghiệm học tập và thực hành từ khóa học đầu tiên mang tên "DevOps and AI on AWS: Upgrading Apps with Generative AI".
Nâng cấp ứng dụng TravelGuide với Generative AI
Khóa học tập trung vào một ứng dụng hướng dẫn du lịch (TravelGuide) được viết bằng Python, chạy trên instance EC2 và sử dụng DynamoDB để lưu trữ dữ liệu. Mục tiêu là nâng cấp ứng dụng này để cung cấp thông tin du lịch, lập lịch trình và cho phép người dùng để lại đánh giá.
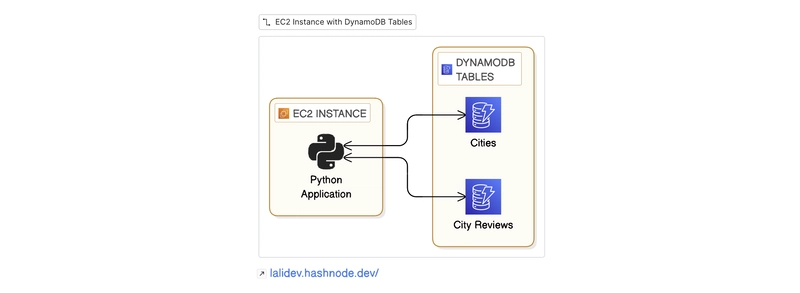 Giao diện ứng dụng TravelGuide
Giao diện ứng dụng TravelGuide
Tuy nhiên, ứng dụng gốc gặp phải những hạn chế lớn: nội dung cho từng thành phố phải được viết và biên tập thủ công, quá trình nghiên cứu và xây dựng lịch trình tốn nhiều thời gian. Hơn nữa, nội dung này là tĩnh, không thể cá nhân hóa theo sở thích của từng du khách (ví dụ: người thích quán bar sẽ có lịch trình khác với người yêu thích bảo tàng).
Để giải quyết vấn đề này, khóa học hướng dẫn việc sử dụng Amazon Bedrock – nền tảng hoàn toàn quản lý của AWS giúp xây dựng các ứng dụng AI tạo sinh quy mô lớn.
Các khái niệm cốt lõi: GenAI và LLM
Trước khi đi sâu vào thực hành, chúng ta cần làm rõ một số thuật ngữ:
- Generative AI (AI tạo sinh): Loại AI có khả năng tạo ra nội dung và ý tưởng mới, bao gồm hội thoại, câu chuyện, hình ảnh, video và âm nhạc.
- Large Language Model (LLM - Mô hình ngôn ngữ lớn): Các mô hình học sâu (deep learning) khổng lồ được huấn luyện trước trên lượng dữ liệu khổng lồ. Chúng sử dụng kiến trúc Transformer với bộ mã hóa và giải mã để hiểu mối quan hệ giữa các từ và cụm từ.
Amazon Bedrock và Cơ sở kiến thức (Knowledge Bases)
Amazon Bedrock cung cấp nhiều Foundation Models (FMs) từ các nhà cung cấp hàng đầu. Một trong những tính năng mạnh mẽ nhất của Bedrock là Knowledge Bases (Cơ sở kiến thức), cho phép tích hợp dữ liệu riêng tư của công ty để cung cấp câu trả lời chính xác và có liên quan hơn.
Vấn đề đặt ra là: Làm thế nào để sử dụng dữ liệu riêng tư mà không cần tinh chỉnh (fine-tune) lại mô hình? Câu trả lời nằm ở kỹ thuật RAG (Retrieval-Augmented Generation).
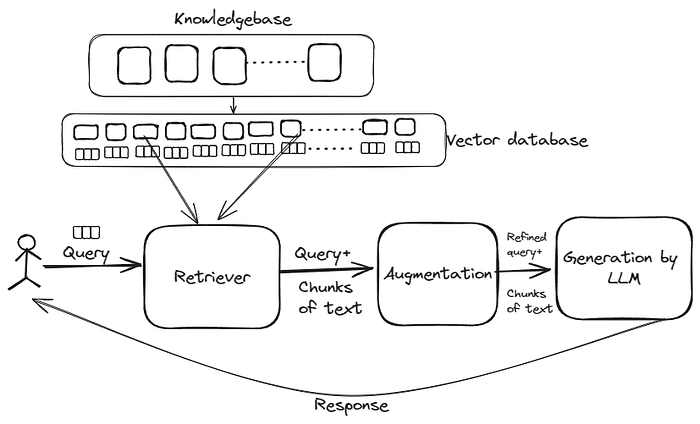 Sơ đồ hoạt động của RAG
Sơ đồ hoạt động của RAG
RAG hoạt động bằng cách truy xuất dữ liệu từ nguồn công ty để làm phong phú thêm câu lệnh (prompt). Amazon Bedrock Knowledge Bases sử dụng cơ sở dữ liệu vector (như Amazon OpenSearch Serverless) để lưu trữ dữ liệu dưới dạng embeddings (các biểu diễn số của văn bản). Khi người dùng đặt câu hỏi, hệ thống tìm kiếm sự tương đồng ngữ nghĩa, truy xuất các đoạn thông tin hữu ích nhất và sử dụng chúng làm ngữ cảnh bổ sung để mô hình tạo ra câu trả lời ngôn ngữ tự nhiên.
Tùy chỉnh mô hình vs. Knowledge Bases
Ngoài việc sử dụng Knowledge Bases, Amazon Bedrock cũng cho phép tùy chỉnh mô hình (Model Customization) để cải thiện hiệu suất cho các trường hợp sử dụng cụ thể thông qua các phương pháp như:
- Distillation (Chưng cất): Chuyển giao kiến thức từ mô hình lớn sang mô hình nhỏ hơn, nhanh hơn và tiết kiệm chi phí hơn.
- Supervised Fine-tuning (Tinh chỉnh có giám sát): Huấn luyện mô hình với dữ liệu được gán nhãn để cải thiện hiệu suất trên các tác vụ cụ thể.
- Continued Pre-training (Tiếp tục huấn luyện trước): Cung cấp dữ liệu không gán nhãn để làm quen mô hình với các loại đầu vào cụ thể, cải thiện kiến thức lĩnh vực.
Thực hành: Tạo Knowledge Base trên Amazon Bedrock
Trong phần thực hành (lab), tôi đã tạo một Knowledge Base và cấu hình nó cho ứng dụng. Quy trình khá trực quan trên giao diện console của AWS:
- Truy cập Amazon Bedrock và chọn Create Knowledge Base with vector store.
- Chọn nguồn dữ liệu (trong trường hợp này là Amazon S3) và tải lên dữ liệu cần thiết.
- Chọn vector store. Bedrock sẽ tự động tạo một cụm Amazon OpenSearch Serverless để lưu trữ các embeddings.
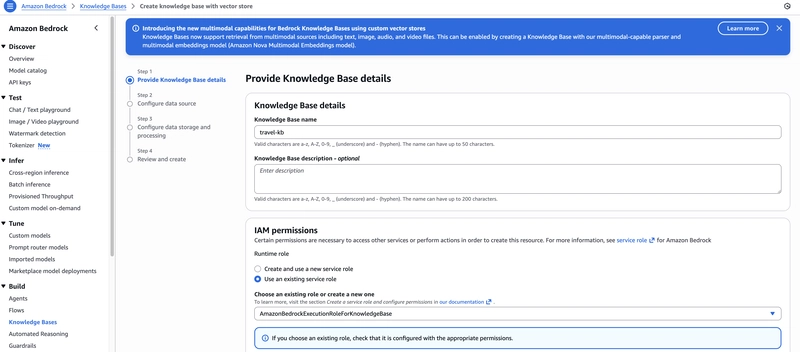 Tạo Knowledge Base trên Console
Tạo Knowledge Base trên Console
Sau khi tạo xong, bước quan trọng là sync (đồng bộ hóa) các nguồn dữ liệu để lập chỉ mục nội dung cho việc tìm kiếm. Bạn có thể kiểm tra mô hình bằng cách nhấn nút Test Knowledge Base, nhập câu lệnh và xem kết quả.
Có hai cách chính để sử dụng Knowledge Base:
- Sử dụng API Retrieve: Truy vấn thông tin trực tiếp mà không tạo thêm phản hồi.
- Sử dụng API RetrieveAndGenerate: Nhận câu lệnh làm đầu vào và tạo phản hồi dựa trên thông tin truy xuất được.
Bảo mật và kiểm soát AI với Guardrails
Khi triển khai AI, an toàn là ưu tiên hàng đầu. Amazon Bedrock Guardrails cung cấp các lớp bảo vệ và kiểm soát vượt ra ngoài thiết kế câu lệnh thông thường, bao gồm:
- Bộ lọc nội dung: Chặn các danh mục gây hại như thù ghét, sỉ nhục hoặc bạo lực.
- Nền tảng (Grounding): Ngưỡng độ tin cậy cho độ chính xác về mặt sự thật.
- Tính liên quan (Relevance): Kiểm tra xem phản hồi của mô hình có liên quan đến truy vấn của người dùng hay không.
Tích hợp AI qua API và Prompt Engineering
Để tích hợp vào ứng dụng, chúng ta sử dụng AWS SDK cho Python (Boto3). Dưới đây là ví dụ về cách gọi mô hình Amazon Titan Text thông qua Bedrock API:
import json
import logging
import boto3
from botocore.exceptions import ClientError
def generate_text(model_id, body):
"""
Tạo văn bản sử dụng Amazon Titan Text models.
"""
logger = logging.getLogger(__name__)
bedrock = boto3.client(service_name='bedrock-runtime')
response = bedrock.invoke_model(
body=body, modelId=model_id, accept="application/json", contentType="application/json"
)
response_body = json.loads(response.get("body").read())
return response_body
def main():
try:
model_id = 'amazon.titan-text-premier-v1:0'
prompt = """Meeting transcript: Miguel: Hi Brant, I want to discuss the workstream..."""
body = json.dumps({
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 3072,
"stopSequences": [],
"temperature": 0.7,
"topP": 0.9
}
})
response_body = generate_text(model_id, body)
print(f"Output text: {response_body['results'][0]['outputText']}")
except ClientError as err:
print(f"A client error occured: {err.response['Error']['Message']}")
if __name__ == "__main__":
main()
Cuối cùng, để tối ưu hóa kết quả từ LLM, kỹ thuật Prompt Engineering là vô cùng quan trọng. Một chiến lược hiệu quả là kỹ thuật CO-STAR:
- Context (Ngữ cảnh): Cung cấp bối cảnh nền tảng.
- Objective (Mục tiêu): Nêu rõ mục tiêu bạn muốn đạt được.
- Style (Phong cách): Xác định phong cách viết.
- Tone (Giọng điệu): Thiết lập giọng điệu phù hợp.
- Audience (Đối tượng): Chỉ định đối tượng người đọc.
- Response (Phản hồi): Mô tả định dạng phản hồi mong muốn.
Kết luận
Đây là phần kết thúc cho bài đầu tiên trong series ba phần về chuyên môn AI và AWS trên Coursera. Việc tìm hiểu Amazon Bedrock, Knowledge Bases và Prompt Engineering đã mở ra những khả năng mới trong việc nâng cấp các ứng dụng truyền thống. Tôi rất hào hứng với khóa học tiếp theo "DevOps and AI on AWS: CI/CD for Generative AI Applications" và hẹn gặp lại các bạn trong những bài viết sau!
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026