
Netflix Tối Ưu Hóa Apache Druid: 84% Kết Quả Truy Vấn Được Phục Vụ Từ Cache
Netflix đã triển khai chiến lược bộ nhớ đệm nhận biết khoảng thời gian cho Apache Druid, giúp phục vụ 84% kết quả phân tích từ cache và giảm 33% tải truy vấn. Phương pháp này phân tách các truy vấn cửa sổ trượt thành các đoạn thời gian có thể tái sử dụng, chỉ tính toán lại dữ liệu mới nhất. Nhờ đó, Netflix giảm thiểu lượng dữ liệu quét, cải thiện độ trễ P90 và tối ưu hóa hiệu suất phân tích thời gian thực.
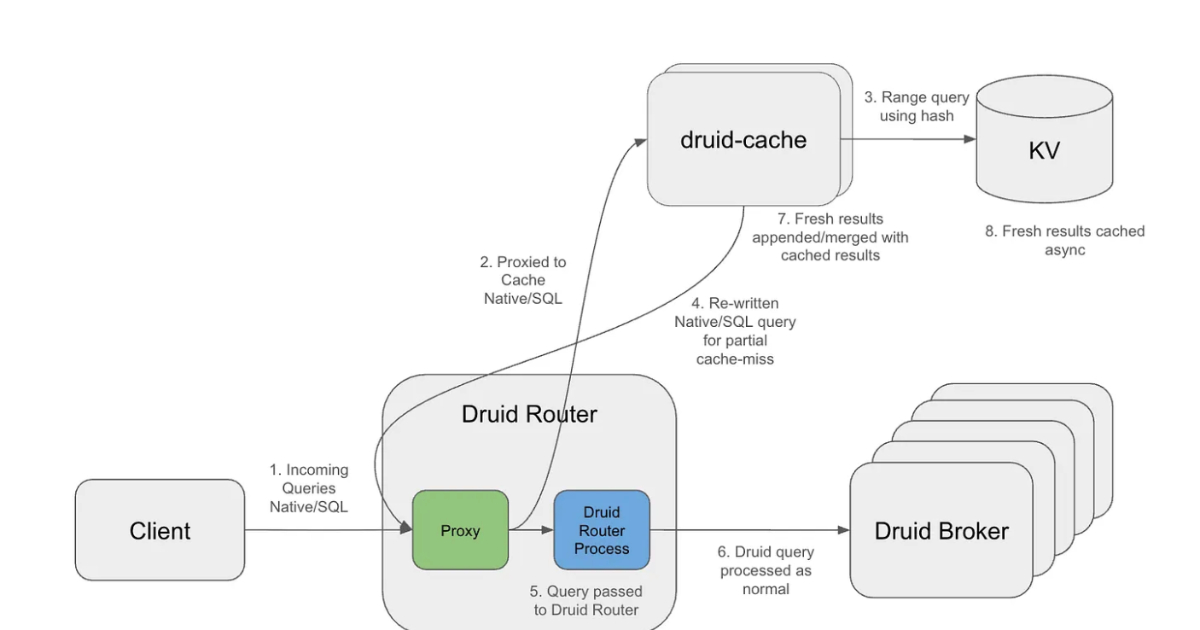
Netflix đã cải thiện đáng kể hiệu suất truy vấn trên Apache Druid bằng cách giới thiệu chiến lược bộ nhớ đệm nhận biết khoảng thời gian (interval-aware caching). Giải pháp mới này giúp phục vụ khoảng 84% kết quả phân tích từ bộ nhớ đệm và giảm tải truy vấn xuống hệ thống khoảng 33%.
Tại quy mô của Netflix, các hệ thống phân tích thời gian thực phải xử lý hàng nghìn tỷ hàng dữ liệu để cung cấp năng lượng cho các bảng điều khiển (dashboard) dùng theo dõi, thử nghiệm và ra quyết định vận hành. Những bảng điều khiển này thường xuyên thực hiện các truy vấn gần như giống hệt nhau, chẳng hạn như tỷ lệ lỗi hoặc các chỉ số tương tác, trên các cửa sổ thời gian trượt (rolling windows). Tuy nhiên, sự thay đổi nhỏ trong ranh giới thời gian khiến các hệ thống cache truyền thống coi chúng là các yêu cầu riêng biệt, dẫn đến việc sử dụng lại cache thấp và tính toán dư thừa trong Apache Druid.
/filters:no_upscale()/news/2026/05/netflix-druid-interval-cache/en/resources/1Screenshot 2026-04-24 at 9.46.21 PM-1777092444864.png)
Evan King, đồng sáng lập Hello Interview, đã mô tả thách thức này trong một bài đăng:
Các truy vấn lặp lại, chẳng hạn như lỗi trong 3 giờ qua, được các bộ nhớ đệm truyền thống coi là các yêu cầu riêng biệt, mặc dù hầu hết dữ liệu cơ bản vẫn không thay đổi.
Cách tiếp cận của Netflix là phân tách kết quả truy vấn thành các đoạn phân đoạn theo thời gian (time-aligned segments) để cho phép tái sử dụng trên các truy vấn cửa sổ trượt chồng chéo. Thay vì lưu trữ toàn bộ đầu ra của truy vấn, hệ thống lưu trữ các tổng hợp trung gian cho các khoảng thời gian cố định. Khi một truy vấn mới đến, các đoạn đã được cache sẽ được tái sử dụng cho các phần lịch sử ổn định của cửa sổ thời gian, trong khi chỉ có khoảng thời gian gần nhất được tính toán lại từ Druid và hợp nhất với kết quả đã cache.
Một động lực chính và kết quả của phương pháp này được Ben Sykes, kỹ sư tại Netflix, nhấn mạnh:
Giảm 33% số lượng truy vấn đến Druid và cải thiện 66% thời gian truy vấn P90.
/filters:no_upscale()/news/2026/05/netflix-druid-interval-cache/en/resources/1netflixapachedruid-1777092444864.jpeg) Kiến trúc luồng truy vấn
Kiến trúc luồng truy vấn
Với quy mô hơn 10 nghìn tỷ hàng trong Apache Druid, các truy vấn cửa sổ trượt lặp lại đã trở thành một nút thắt lớn. Lớp bộ nhớ đệm giải quyết vấn đề này bằng cách sử dụng các nhóm (buckets) căn chỉnh theo độ chi tiết với các chính sách TTL theo cấp số nhân, cho phép bộ nhớ đệm tồn tại lâu cho các khoảng thời gian lịch sử trong khi vẫn duy trì tính mới cho dữ liệu gần đây. Về mặt kiến trúc, lớp bộ nhớ đệm hoạt động như một proxy bên ngoài chặn các truy vấn đến, tách cấu trúc truy vấn khỏi các khoảng thời gian và tạo ra các khóa cache có thể tái sử dụng. Các đoạn được cache được lưu trữ trong một hệ thống khóa-giá trị phân tán, cho phép hết hạn độc lập và truy xuất hiệu quả.
Với thiết kế này, chỉ khoảng thời gian gần nhất yêu cầu tính toán lại, trong khi các đoạn lịch sử được tái sử dụng trên nhiều truy vấn chồng chéo. Kết quả là, các truy vấn đến Druid hoạt động trên các phạm vi thời gian giảm đáng kể, quét ít đoạn hơn và xử lý ít dữ liệu hơn. Trong một số khối lượng công việc, Netflix quan sát thấy sự giảm lên đến 14 lần về số byte kết quả và sự giảm đáng kể trong việc quét đoạn.
Hệ thống hiện đang được triển khai như một lớp thử nghiệm và tiếp tục phát triển. Các công việc trong tương lai bao gồm mở rộng hỗ trợ cho các truy vấn SQL được tạo mẫu (templated SQL queries) được sử dụng bởi các công cụ bảng điều khiển, giảm nhu cầu sử dụng các biểu thức truy vấn Druid gốc. Netflix cũng đang khám phá việc tích hợp chặt chẽ hơn bộ nhớ đệm nhận biết khoảng thời gian trực tiếp vào Apache Druid để loại bỏ nhu cầu về lớp proxy bên ngoài và cải thiện hiệu quả lập kế hoạch truy vấn.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026