
Nút thắt tiếp theo của AI không phải là Mô hình, mà là Hệ thống Inference
Các hệ thống AI doanh nghiệp đang bước sang giai đoạn mới, nơi thiết kế inference (suy luận) quan trọng không kém khả năng của chính mô hình. Thay vì đổ lỗi cho mô hình khi gặp sự cố, các kỹ sư cần tập trung tối ưu hóa tầng truy xuất, quản lý bộ nhớ và phân bổ tài nguyên để nâng cao hiệu suất thực tế.

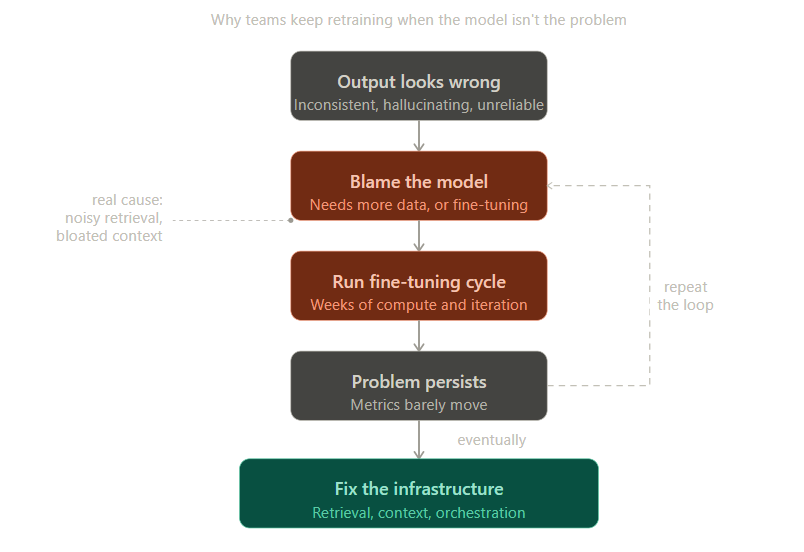
Hãy nói về một hiện tượng tôi thường xuyên bắt gặp khi làm việc với các nhóm phát triển AI tại các doanh nghiệp: họ hầu như luôn đổ lỗi cho mô hình khi có sự cố xảy ra. Điều này dễ hiểu, nhưng thường là sai lầm và dẫn đến những chi phí tốn kém không cần thiết.
Kịch bản thường thấy diễn ra như sau. Các kết quả đầu ra không ổn định; khi ai đó đưa ra vấn đề này, phản ứng đầu tiên là đổ lỗi cho mô hình. Người ta cho rằng cần thêm dữ liệu huấn luyện, một quá trình tinh chỉnh (fine-tuning) khác, hoặc chuyển sang một mô hình cơ bản khác. Sau nhiều tuần làm việc, vấn đề vẫn nguyên trạng hoặc chỉ cải thiện rất ít. Vấn đề thực sự, thường nằm ở tầng truy xuất (retrieval layer), cửa sổ ngữ cảnh (context window) hoặc cách các tác vụ được định tuyến, chưa bao giờ được xem xét kỹ lưỡng.
Tôi đã chứng kiến điều này quá nhiều lần đến mức thấy cần phải viết về nó.
Fine-tuning hữu ích nhưng đang bị lạm dụng
Trong nhiều trường hợp, việc thực hiện một vài điều chỉnh vẫn mang lại giá trị. Nếu cần thích ứng với lĩnh vực chuyên môn, căn chỉnh giọng điệu hoặc hiệu chuẩn an toàn, fine-tuning nên là một phần của quy trình làm việc. Tôi không nói rằng bạn không nên sử dụng nó.
Vấn đề là nó trở thành câu trả lời mặc định cho mọi vấn đề, ngay cả khi không phải là công cụ phù hợp. Một phần là vì nó tạo cảm giác đang làm việc hiệu quả. Bạn bắt đầu một công việc fine-tuning, rõ ràng có điều gì đó đang diễn ra, và có sự khác biệt giữa trước và sau. Nó tạo vẻ bề ngoài rằng bạn đang giải quyết vấn đề, trong khi thực tế thì không.
Một ví dụ điển hình là hệ thống phân tích hợp đồng mà tôi đã quan sát một nhóm đang gỡ lỗi. Các kết quả đầu ra không đáng tin cậy đối với các tài liệu phức tạp, và ý tưởng ban đầu là mô hình thiếu khả năng lập luận pháp lý. Vì vậy, họ đã chạy nhiều lần tinh chỉnh. Vấn đề không hề biến mất. Cuối cùng, có người nhận ra rằng tầng truy xuất đang thực hiện cùng một thao tác lấy dữ liệu nhiều lần và thêm chúng vào cửa sổ ngữ cảnh. Mô hình đang cố gắng xử lý một lượng lớn văn bản giá trị thấp bị lặp đi lặp lại. Họ đã điều chỉnh thứ hạng truy xuất và áp dụng nén ngữ cảnh, hệ thống mới hoạt động tốt hơn nhiều.
Mô hình gốc chưa bao giờ được thay đổi. Và đây là một tình huống khá phổ biến.
 So sánh giữa Fine-tuning và Vòng lặp Inference
So sánh giữa Fine-tuning và Vòng lặp Inference
Điều gì đang diễn ra tại thời điểm Inference
Trong một thời gian dài, inference chỉ đơn giản là bước bạn sử dụng mô hình. Tất cả các quyết định thú vị đều xảy ra trong quá trình huấn luyện. Nhưng điều đó đang thay đổi.
Một lý do là một số mô hình bắt đầu phân bổ nhiều tài nguyên tính toán hơn cho quá trình tạo ra (generation) thay vì "nướng" chúng vào quy trình huấn luyện. Yếu tố khác là các nghiên cứu đã chứng minh rằng các hành vi như tự kiểm tra hoặc viết lại câu trả lời có thể được học hỏi thông qua học tăng cường (reinforcement learning). Cả hai yếu tố này đều chỉ ra rằng bản thân inference là một nơi có thể cải thiện hiệu suất.
Những gì tôi thấy hiện nay là các đội ngũ kỹ thuật bắt đầu coi inference là thứ có thể thiết kế xung quanh, thay vì chỉ là một bước cố định phải chấp nhận. Tác vụ này cần độ sâu lập luận bao nhiêu? Bộ nhớ được quản lý như thế nào? Truy xuất được ưu tiên ra sao? Những câu hỏi này đang trở thành những vấn đề thực sự cần giải quyết thay vì các thiết lập mặc định được bỏ qua.
Vấn đề phân bổ tài nguyên
Điều thường bị đánh giá thấp là hầu hết các hệ thống AI sử dụng cách tiếp cận đồng nhất cho tất cả các truy vấn. Một câu hỏi đơn giản về trạng thái tài khoản sẽ trải qua cùng quy trình với một quy trình tuân thủ nhiều bước, đòi hỏi thông tin phải được đối chiếu từ nhiều tài liệu mâu thuẫn. Cùng chi phí, cùng quy trình, cùng tài nguyên tính toán.
Điều này dường như không hợp lý lắm khi bạn suy nghĩ kỹ. Trong tất cả các ứng dụng kỹ thuật khác, tài nguyên sẽ được phân bổ dựa trên khối lượng công việc cần thiết. Một số nhóm bắt đầu làm điều này với AI, chuyển các inference nhẹ sang khối lượng công việc nhẹ hơn và định tuyến tài nguyên tính toán mạnh hơn cho các tác vụ thực sự cần thiết. Kinh tế học trở nên tốt hơn, và chất lượng của các việc khó khăn cũng cải thiện, vì bạn không còn thiếu hụt tài nguyên cho chúng.
Các hệ thống này có nhiều lớp hơn bạn nghĩ
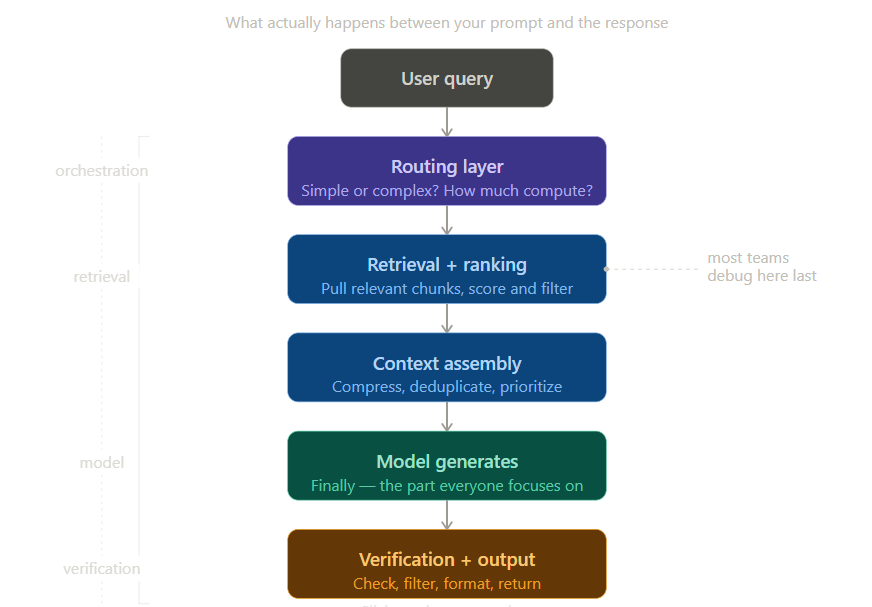
Khi nhìn vào bên trong một hệ thống AI sản xuất hiện nay, thường nó không chỉ là một mô hình trả lời câu hỏi. Nó thường đi kèm với một bước truy xuất, một bước xếp hạng, có thể là bước xác minh và bước tóm tắt; nhiều bước hoạt động song song để tạo ra kết quả đầu ra cuối cùng. Không chỉ là khả năng của mô hình cơ bản, mà còn là cách tất cả các mảnh ghép này khớp với nhau để tạo ra đầu ra.
Nếu bộ xếp hạng truy xuất không được hiệu chuẩn đúng, nó sẽ tạo ra các đầu ra tương tự như lỗi của mô hình. Một cửa sổ ngữ cảnh có thể phát triển vô kiểm soát sẽ tinh tế ảnh hưởng đến chất lượng lập luận, nhưng không có gì rõ ràng bị lỗi. Đây là các vấn đề về hệ thống, không phải vấn đề của mô hình, và chúng cần được giải quyết bằng tư duy hệ thống.
Một ví dụ về tư duy loại này trong thực tế là "speculative decoding" (giải mã suy đoán). Khái niệm là một mô hình nhỏ hơn tạo ra các ứng viên đầu ra, và một mô hình lớn hơn xác minh chúng. Nó bắt đầu như một tối ưu hóa độ trễ, nhưng thực chất nó là một ví dụ về việc phân phối lập luận trên nhiều thành phần thay vì mong đợi một mô hình làm mọi thứ. Hai nhóm sử dụng cùng một mô hình cơ bản nhưng các kiến trúc inference khác nhau có thể kết thúc với các kết quả khá khác nhau trong sản xuất.
 Pipeline Inference AI trong môi trường Production
Pipeline Inference AI trong môi trường Production
Bộ nhớ đang trở thành vấn đề thực sự
Các cửa sổ ngữ cảnh lớn hơn đã hữu ích, nhưng vượt qua một điểm nhất định, ngữ cảnh nhiều hơn không cải thiện lập luận; nó làm giảm chất lượng. Truy xuất trở nên ồn ào hơn, mô hình theo dõi kém hiệu quả hơn và chi phí inference tăng lên. Các nhóm vận hành AI ở quy mô lớn đang dành thời gian thực cho những thứ như "paged attention" và nén ngữ cảnh, những thứ không thú vị để nói về nhưng lại rất quan trọng về mặt vận hành.
Ý tưởng là có đúng ngữ cảnh, nhưng không quá nhiều, và được quản lý tốt.
Tóm lại
Việc lựa chọn mô hình không còn quan trọng như trước đây. Các mô hình nền tảng có năng lực hiện có sẵn từ nhiều nhà cung cấp, và khoảng cách về năng lực đã thu hẹp cho hầu hết các trường hợp sử dụng. Điều thực sự quyết định việc một triển khai có thành công hay không là cơ sở hạ tầng xung quanh mô hình, cách truy xuất được tinh chỉnh, cách tính toán được phân bổ và cách hệ thống xử lý các trường hợp ngoại lệ theo thời gian.
Các nhóm sẽ ở vị thế tốt trong vài năm tới là những nhóm coi kiến trúc inference là thứ đáng để kỹ thuật hóa cẩn thận, thay vì giả định rằng một mô hình "đủ tốt" sẽ giải quyết mọi thứ khác. Theo kinh nghiệm của tôi, thường thì nó không giải quyết được.


