
Pandas Không Hề Bị Lãng Quên: Tại Sao Nó Vẫn Là Công Cụ Hàng Đầu Để Xử Lý Dữ Liệu
Dù xuất hiện nhiều công cụ mới tối ưu cho dữ liệu lớn, Pandas vẫn là lựa chọn đáng tin cậy cho phần lớn các tác vụ khoa học dữ liệu thông thường. Bài viết sẽ minh họa khả năng làm sạch và xử lý dữ liệu linh hoạt của Pandas, đồng thời khẳng định tầm quan trọng của việc thành thạo thư viện này đối với bất kỳ ai làm việc trong lĩnh vực AI và dữ liệu.

Khi tôi bắt đầu học khoa học dữ liệu vào năm 2020, Pandas là một trong những công cụ phổ biến nhất. Mặc dù hiện nay có nhiều công cụ mới tập trung vào việc cải thiện những điểm yếu của Pandas khi xử lý các tập dữ liệu cực lớn, tôi vẫn sử dụng Pandas cho rất nhiều tác vụ làm sạch, xử lý và phân tích dữ liệu. Đúng là Pandas có thể gây khó khăn khi làm việc với hàng tỷ dòng dữ liệu, nhưng đối với mọi thứ ở quy mô nhỏ hơn, nó hoàn toàn đủ dùng và vượt trội.
Tôi thấy Pandas không chỉ được dùng cho Khám phá Dữ liệu Khai thác (EDA) hay trong các notebook, mà còn xuất hiện trong các hệ thống sản xuất thực tế.
Trong bài viết này, tôi sẽ đi qua một số thao tác làm sạch và xử lý dữ liệu để chứng minh khả năng mạnh mẽ của Pandas.
 Minh họa dữ liệu
Minh họa dữ liệu
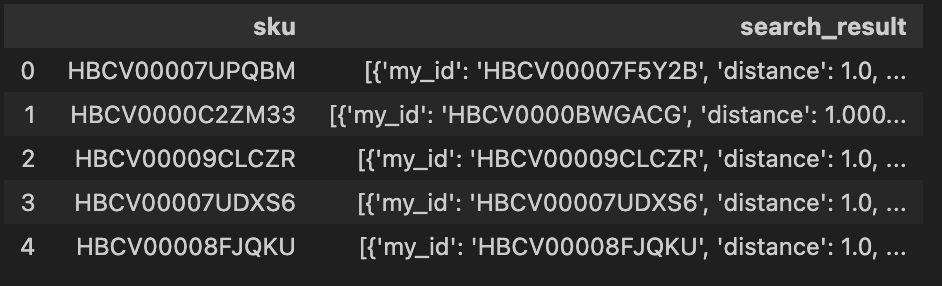
Hãy bắt đầu với tập dữ liệu chứa các mã SKU (đơn vị lưu kho) và phản hồi từ API tìm kiếm cho các SKU này.
import pandas as pd
search_results = pd.read_csv("search_results.csv")
search_results.head()
Kết quả tìm kiếm là một danh sách các từ điển (dictionary) và trông như sau:
search_results.loc[0, "search_result"]
# Output: "[{'my_id': 'HBCV00007F5Y2B', 'distance': 1.0, 'entity': {}}, ... và 5 thực thể còn lại]"
Như chúng ta thấy ở đầu ra, đây không phải là định dạng danh sách từ điển chuẩn xác vì có phần cuối cùng (“… and 5 entities remaining”). Hơn nữa, nó được lưu dưới dạng một chuỗi ký tự đơn lẻ.
Để sử dụng hiệu quả hơn, chúng ta cần chuyển đổi nó thành danh sách từ điển chuẩn. Dòng mã sau loại bỏ phần cuối bằng cách tách chuỗi tại dấu “…” và lấy phần tách đầu tiên.
search_results.loc[0, "search_result"].split("...")[0].strip()
Tuy nhiên, đầu ra vẫn là một chuỗi đơn. Chúng ta có thể sử dụng module ast tích hợp sẵn của Python để chuyển đổi nó thành danh sách:
import ast
res = ast.literal_eval(search_results.loc[0, "search_result"].split("...")[0].strip())
Bây giờ chúng ta đã có kết quả tìm kiếm dưới dạng danh sách từ điển chuẩn. Nhưng thao tác này mới chỉ áp dụng cho một dòng. Chúng ta cần áp dụng cùng một thao tác cho tất cả các SKU (tức là toàn bộ cột SKU).
Một lựa chọn là sử dụng vòng lặp for để duyệt qua tất cả các dòng. Tuy nhiên, đây không phải là cách tối ưu. Chúng ta nên ưu tiên các thao tác vector hóa (vectorized operations) khi có thể. Thao tác vector hóa về cơ bản có nghĩa là thực thi mã trên tất cả các dòng cùng một lúc.
Trên một dòng đơn, tôi dùng phương pháp tách chuỗi để loại bỏ phần cuối, nhưng nó không hoạt động tốt trong thao tác vector hóa. Một lựa chọn mạnh mẽ hơn là sử dụng biểu thức chính quy (regex).
search_results.loc[:, 'search_result'] = search_results['search_result'].str.replace(r"\.\.\..*", "", regex=True).str.strip()
Đoạn mã này chọn “…” và mọi thứ đi sau nó, sau đó thay thế bằng không gian rỗng. Nói cách khác, nó loại bỏ phần “… and 5 entities remaining”.
Bây giờ, tất cả các dòng trong cột kết quả tìm kiếm đều là danh sách từ điển chuẩn, dù vẫn được lưu dưới dạng chuỗi. Tôi có thể dễ dàng chuyển đổi chúng thành danh sách bằng module ast ở bước tiếp theo.
 Xử lý dữ liệu với Pandas
Xử lý dữ liệu với Pandas
Điều tôi quan tâm là các SKU được trả về trong kết quả tìm kiếm. Tôi sẽ tạo một cột mới bằng cách trích xuất các SKU từ các từ điển đó thông qua khóa “my_id”.
Có 3 phần trong thao tác này:
- Chuyển đổi chuỗi kết quả tìm kiếm thành danh sách bằng hàm
literal_eval. - Trích xuất SKU từ khóa
my_idcủa từ điển. - Thực hiện việc này trong một list comprehension để lấy SKU từ tất cả các từ điển trong danh sách.
Chúng ta có thể thực hiện tất cả các thao tác này bằng cách áp dụng một hàm lambda cho tất cả các dòng như sau:
search_results.loc[:, "result_skus"] = \
search_results["search_result"].apply(lambda x: [item['my_id'] for item in ast.literal_eval(x)])
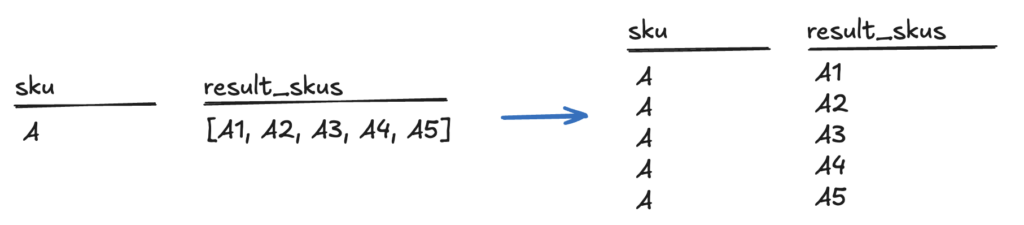
Mỗi dòng trong cột result_skus giờ chứa một danh sách 10 SKU. Giả sử tôi cần có 10 SKU này ở các dòng riêng biệt. Với mỗi dòng trong cột sku, sẽ có 10 dòng được tạo ra từ danh sách trong cột result_skus. Có một cách rất đơn giản để làm điều này trong Pandas, đó là hàm explode.
data = search_results[["sku", "result_skus"]].explode("result_skus", ignore_index=True)
Hàm explode sẽ "nổ" danh sách thành các dòng riêng lẻ.
Hãy xem xét trường hợp ngược lại. Chúng ta có một dataframe như ở trên nhưng muốn gom tất cả kết quả cho một sku về một dòng duy nhất.
Chúng ta có thể sử dụng hàm groupby để nhóm các dòng theo sku và sau đó áp dụng hàm list trên cột result_skus:
new_data = data.groupby("sku", as_index=False)["result_skus"].apply(list)
Điều này sẽ đưa chúng ta trở lại bước trước đó.
Sử dụng hàm explode, chúng ta đã tạo ra một dataframe với một dòng riêng cho mỗi sku trong cột result_skus. Vậy nếu chúng ta cần tách chúng sang các cột khác nhau thay vì các dòng thì sao?
Một lựa chọn là áp dụng hàm pd.Series cho cột result_skus và nối các cột kết quả vào dataframe gốc.
new_cols = new_data["result_skus"].apply(pd.Series)
new_data = pd.concat([new_data, new_cols], axis=1)
Các cột từ 0 đến 9 chứa 10 SKU trong cột result_skus. Tuy nhiên, đoạn mã sử dụng hàm apply này không phải là thao tác vector hóa.
Chúng ta có một lựa chọn khác, đó là vector hóa và nhanh hơn nhiều:
new_cols = pd.DataFrame(new_data["result_skus"].tolist())
new_data = pd.concat([new_data, new_cols], axis=1)
Đoạn mã này sẽ cho ra cùng một dataframe như trên nhưng nhanh hơn đáng kể.
 Tối ưu hóa hiệu năng
Tối ưu hóa hiệu năng
Tôi đã minh họa một nhiệm vụ làm sạch và xử lý dữ liệu điển hình mà một nhà khoa học dữ liệu hoặc chuyên gia phân tích có thể gặp phải trong công việc. Tôi đã làm việc trong lĩnh vực này hơn 5 năm và Pandas luôn đủ để đáp ứng nhu cầu của tôi, ngoại trừ khi làm việc với các tập dữ liệu rất lớn (ví dụ: hàng tỷ dòng).
Những công cụ phù hợp hơn cho các tập dữ liệu lớn như vậy có cú pháp tương tự như Pandas. Ví dụ, PySpark là sự kết hợp giữa Pandas và SQL. Polars cũng rất giống Pandas về mặt cú pháp. Vì vậy, việc học và thực hành Pandas vẫn là một kỹ năng có giá trị cao đối với bất kỳ ai làm việc trong lĩnh vực khoa học dữ liệu và AI.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026