
Prefill là bài toán tính toán, Decode là bài toán bộ nhớ: Tại sao GPU không nên làm cả hai?
Bài viết phân tích sự lãng phí tài nguyên khi chạy cả hai giai đoạn Prefill và Decode của LLM trên cùng một GPU. Giải pháp "Disaggregated Inference" giúp tách biệt hai giai đoạn này, tối ưu hóa phần cứng và giảm chi phí vận hành đáng kể cho các hệ thống AI quy mô lớn.
Gần đây, tôi đã hỗ trợ một doanh nghiệp lớn quy hoạch cụm Kubernetes cho việc suy luận (inference) thời gian thực trên sản phẩm LLM hướng tới khách hàng của họ. Chúng tôi bắt đầu với 64 GPU H100 SXM trải rộng trên 8 node, tất cả đều chạy vLLM ở chế độ đơn khối (monolithic). Tuy nhiên, kết quả không như mong đợi.
Trong các đợt xử lý prefill, các tensor cores đạt mức sử dụng 92%. Nhưng chỉ mười mili-giây sau, trong giai đoạn decode, cùng một GPU đó tụt xuống mức 28%. Chúng tôi đang trả tiền cho 64 chiếc H100 nhưng thực tế chỉ có khoảng 20 chiếc làm việc có ý nghĩa trong 90% thời gian của mỗi yêu cầu. Bộ phận tài chính muốn biết tại sao hóa đơn GPU lại cao ngất ngưởng như thể chúng tôi đang huấn luyện một mô hình nền tảng, trong khi thực tế chỉ đang phục vụ một mô hình đã có sẵn.
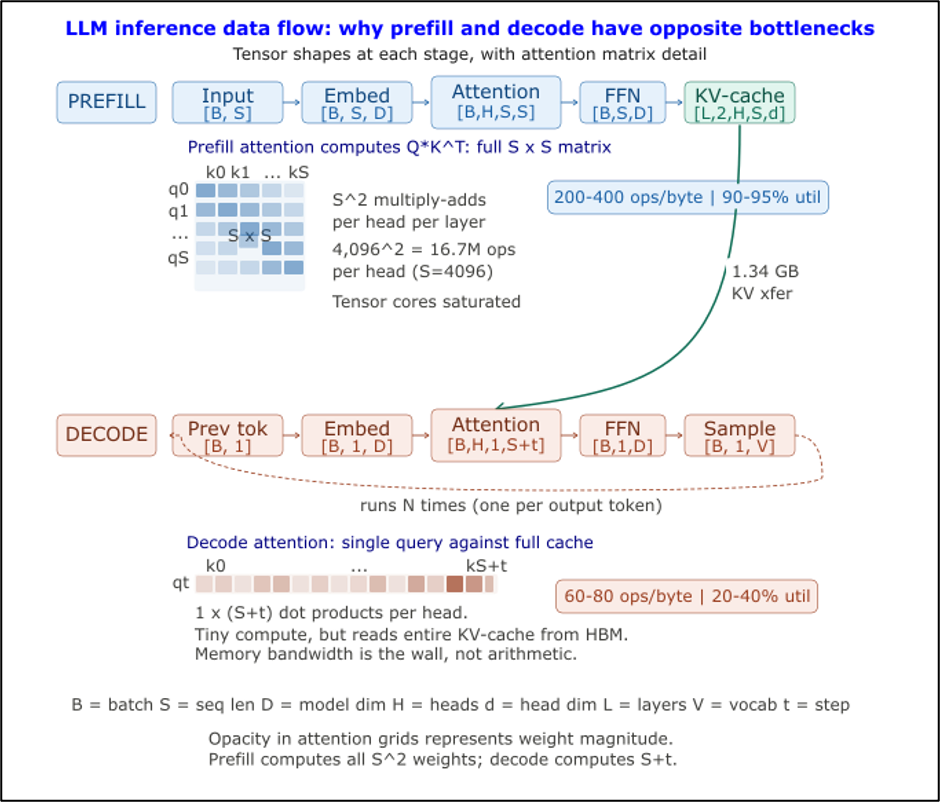 Sự khác biệt về sử dụng tài nguyên giữa Prefill và Decode
Sự khác biệt về sử dụng tài nguyên giữa Prefill và Decode
Mô hình Llama 70B chạy suy luận trên GPU H100 đạt 92% mức sử dụng tính toán trong giai đoạn prefill. Ba mươi mili-giây sau, trong giai đoạn decode, cùng một GPU đó giảm xuống còn 30%. Phần cứng không thay đổi. Trọng số mô hình thì giống hệt nhau. Nhưng cường độ tính toán của khối lượng công việc đã giảm đi 5 lần giữa hai giai đoạn này.
Sự không khớp này nằm ở gốc rễ của mọi vấn đề về chi phí suy luận, nhưng hầu hết các kiến trúc phục vụ hiện nay đều giả định rằng nó không tồn tại.
Hai giai đoạn của suy luận LLM
Mỗi khi một mô hình ngôn ngữ lớn xử lý một yêu cầu, nó thực hiện hai việc hoàn toàn khác nhau.
Đầu tiên, nó đọc toàn bộ câu lệnh (prompt) của bạn một cách song song, điền vào bộ nhớ đệm key-value (KV-cache) với trạng thái attention của từng token đầu vào. Đó là giai đoạn prefill.
Sau đó, nó tạo ra các token đầu ra từng cái một, đọc từ bộ nhớ đệm đó ở mỗi bước. Đó là giai đoạn decode.
Prefill là một bài toán nhân ma trận. Decode là một bài toán về băng thông bộ nhớ. Chúng có các yêu cầu phần cứng trái ngược nhau, nhưng thực tế phổ biến hiện nay là chạy cả hai trên cùng một nhóm GPU.
Thực tế này rất tốn kém. GPU được định kích thước hoàn hảo cho đợt prefill lại bị cung cấp quá mức dư thừa cho decode. Ngược lại, GPU tiết kiệm chi phí cho decode lại không thể theo kịp prefill. Bạn phải trả tiền cho trường hợp xấu nhất ở cả hai hướng.
Giải pháp: Disaggregated Inference
Disaggregated inference (Suy luận tách rời) chia hai giai đoạn này thành hai nhóm phần cứng riêng biệt, mỗi nhóm được định kích thước cho công việc thực tế của nó. Ý tưởng này xuất hiện trong một bài báo OSDI năm 2024 gọi là DistServe, đến từ phòng thí nghiệm Hao AI của UC San Diego. Mười tám tháng sau, Perplexity đã triển khai nó trong môi trường sản xuất. Meta, LinkedIn và Mistral đều phục vụ lưu lượng truy cập thông qua kiến trúc này. NVIDIA thậm chí đã xây dựng một toàn bộ khuôn khổ (Dynamo) xoay quanh nó. vLLM, SGLang và TensorRT-LLM đều hỗ trợ tính năng này một cách nguyên bản.
Dưới đây là cách nó hoạt động, sự đánh đổi cần lưu ý, và khi nào bạn không nên bận tâm đến nó.
Tại sao phục vụ đơn khối (Monolithic) tốn kém bạn bao nhiêu
Trong một triển khai vLLM hoặc TensorRT-LLM tiêu chuẩn, một nhóm GPU duy nhất xử lý cả hai giai đoạn. Trình lập lịch xen kẽ các yêu cầu prefill và decode trong cùng một lô (batch).
Vấn đề ngay lập tức là sự nhiễu. Khi một yêu cầu prefill mới đi vào lô, các yêu cầu decode đang hoạt động phải chờ đợi. Prefill yêu cầu nhiều tính toán và mất nhiều thời gian hơn mỗi bước. Những yêu cầu decode đó, vốn nên trả về token với nhịp độ ổn định, sẽ trải qua sự tăng độ trễ. Đây là hiện tượng giật độ trễ giữa các token (ITL) mà các hệ thống sản xuất luôn cố gắng tránh. Một người dùng đang xem phản hồi dạng luồng sẽ thấy văn bản dừng lại giữa câu trong khi GPU đang xử lý câu lệnh của người khác.
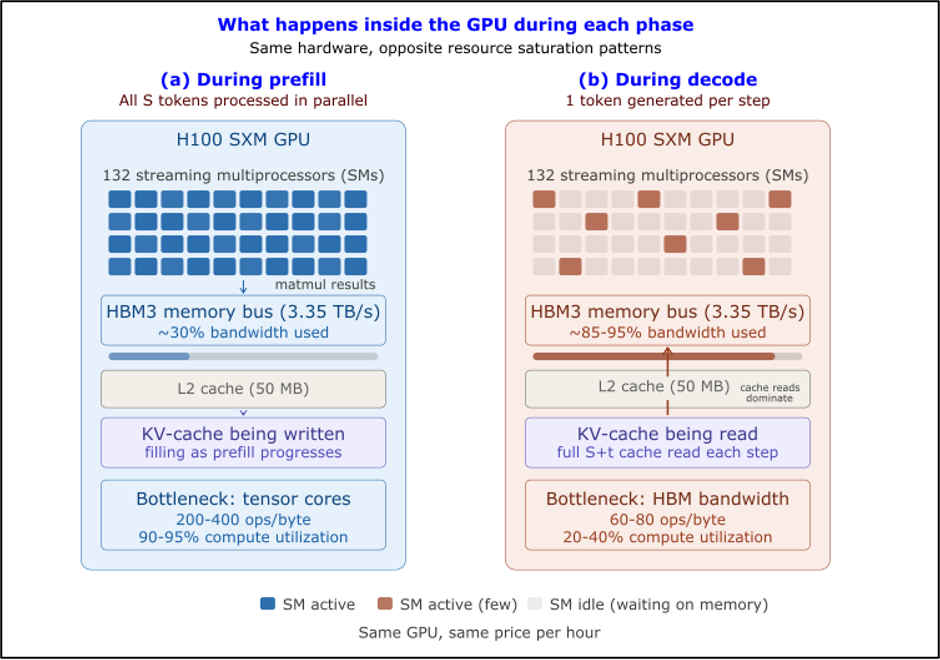 Trạng thái GPU trong Monolithic Serving
Trạng thái GPU trong Monolithic Serving
Vấn đề chậm chạp hơn là sự lãng phí mức sử dụng. GPU được cung cấp để xử lý các đỉnh prefill, do đó nó bị cung cấp quá mức cho giai đoạn decode chiếm phần lớn vòng đời yêu cầu. Một lần tạo điển hình tạo ra 200-500 token đầu ra. Mỗi bước decode mất 10-30ms. Một phản hồi 300 token dành khoảng 3-9 giây cho decode và có thể chỉ 200ms cho prefill. GPU chạy decode trong hơn 90% thời gian thực, và trong 90% thời gian đó, nó chỉ sử dụng 30% khả năng tính toán. Bạn đang trả tiền cho một chiếc H100 nhưng chỉ nhận được mức sử dụng của H100 trong một phần mười thời lượng yêu cầu.
Chia tách đường dẫn suy luận
Disaggregated inference chạy prefill và decode trên các nhóm GPU riêng biệt được kết nối bằng mạng tốc độ cao. Một yêu cầu đến, được định tuyến đến một worker prefill, nơi xử lý toàn bộ câu lệnh và tạo ra KV-cache. Bộ nhớ đệm đó sau đó được chuyển qua mạng đến một worker decode, nơi xử lý việc tạo token tự hồi quy.
Ba thành phần chính làm cho kiến trúc này hoạt động:
- Router nhận thức KV: Nằm ở phía trước cả hai nhóm, nó gán các yêu cầu đến cho các worker prefill có sẵn và sau khi prefill hoàn tất, định tuyến KV-cache đến worker decode có dung lượng trống.
- Nhóm Prefill: Chứa các GPU được tối ưu hóa cho thông lượng tính toán cao (nhân ma trận). Các worker này xử lý câu lệnh, xây dựng KV-cache và chuyển giao chúng.
- Nhóm Decode: Chứa các GPU được tối ưu hóa cho băng thông bộ nhớ. Các worker này nhận KV-cache và tạo token tự hồi quy.
Hai nhóm này mở rộng quy mô độc lập. Nếu khối lượng công việc của bạn thiên về câu lệnh (prompt dài), bạn thêm worker prefill. Nếu bạn phục vụ nhiều người dùng đồng thời tạo ra các phản hồi dài, bạn thêm worker decode. Sự tách rời này là lợi ích kinh tế chính: bạn ngừng trả tiền cho khả năng tính toán trong giai đoạn decode và ngừng trả tiền cho băng thông bộ nhớ trong giai đoạn prefill.
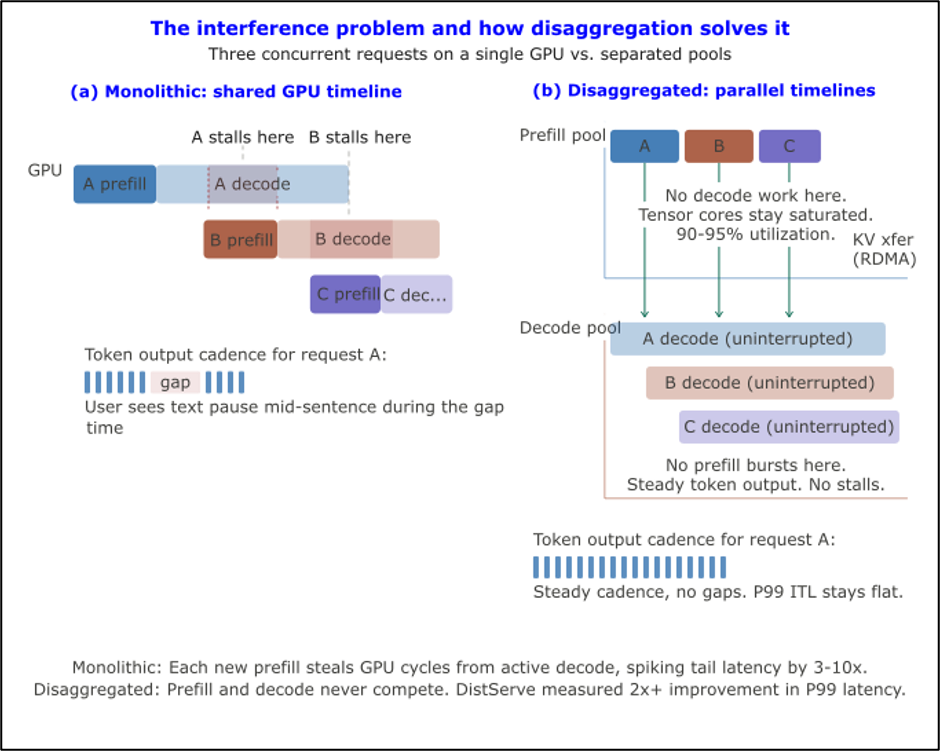 Kiến trúc Disaggregated Inference
Kiến trúc Disaggregated Inference
Chi phí bạn phải trả: Chuyển KV-cache
Tách rời không phải là miễn phí. KV-cache được tạo ra trong prefill phải di chuyển từ GPU prefill sang GPU decode qua mạng, và các bộ nhớ đệm này không hề nhỏ.
Đối với mô hình 70B tham số sử dụng grouped-query attention với 80 lớp, mỗi token có trạng thái KV là 327.680 byte. Một câu lệnh 4.096 token tạo ra 1,34 GB KV-cache. Toàn bộ khối dữ liệu này phải được chuyển trước khi worker decode có thể bắt đầu tạo.
Tốc độ 100 Gbps (liên kết RDMA tiêu chuẩn) mất khoảng 107 mili-giây để chuyển 1,34 GB. Ở 400 Gbps, mất 27ms. Những con số này rất quan trọng vì chúng đặt ra mức sàn cho thời gian đến token đầu tiên (TTFT).
Tuy nhiên, các phép đo từ bài báo DistServe cho thấy cải thiện độ trễ P99 lên gấp 2 hoặc nhiều hơn với disaggregation, vì việc loại bỏ sự nhiễu giữa prefill và decode loại bỏ các đỉnh độ trễ đuôi mà việc xếp hàng gây ra. Chi phí chuyển 27ms thay thế cho độ trễ xếp hàng từ 200-500ms.
Khi nào disaggregation làm cho mọi thứ tồi tệ hơn
Không phải mọi khối lượng công việc đều được hưởng lợi. Sổ tay suy luận của BentoML báo cáo sự suy giảm hiệu suất 20-30% khi disaggregation được áp dụng cho các khối lượng công việc không thực sự cần nó.
Các câu lệnh ngắn bị ảnh hưởng nhiều nhất. Nếu câu lệnh trung bình của bạn dưới 512 token và độ dài tạo ra dưới 100 token, chi phí chuyển KV-cache sẽ ăn mòn bất kỳ lợi ích độ trễ nào. Đối với các chatbot xử lý câu hỏi nhanh, phục vụ đơn khối đơn giản và nhanh hơn.
Quy mô cũng quan trọng. Một node duy nhất với 2-4 GPU không tạo ra đủ yêu cầu đồng thời để giữ cho hai nhóm riêng biệt bận rộn. Disaggregation bắt đầu có lãi khi bạn có hàng chục GPU và đủ lưu lượng truy cập để giữ cho cả hai nhóm bão hòa.
Bạn có nên disaggregate không?
Trước khi cấu trúc lại stack phục vụ của mình, hãy chạy qua 5 kiểm tra sau:
- Đo tỷ lệ thời gian prefill trên decode. Nếu decode chiếm dưới 70% thời lượng yêu cầu, disaggregation có ít lợi ích hơn.
- Tính toán kích thước chuyển KV-cache. Nếu nó vượt quá 500 MB mỗi yêu cầu và mạng của bạn dưới 100 Gbps, độ trễ chuyển sẽ ảnh hưởng đến ngân sách TTFT của bạn.
- Kiểm tra tỷ lệ hit prefix cache. Nếu 80%+ KV-cache đã có sẵn trên worker decode từ lượt trước, giá trị của nhóm prefill riêng biệt sẽ giảm.
- Đếm GPU của bạn. Dưới khoảng 16 GPU, chi phí lập lịch thường vượt quá lợi ích sử dụng.
- Kiểm tra mạng của bạn. Nếu bạn bị giới hạn ở TCP thay vì RDMA, disaggregation vẫn có thể hoạt động nhưng độ trễ sẽ cao hơn.
Nếu các kiểm tra 1, 4 và 5 đều thuận lợi, disaggregation gần như chắc chắn sẽ giảm chi phí phục vụ mỗi token của bạn. Hãy bắt đầu với chế độ prefill tách rời có sẵn của vLLM, đo tác động lên TTFT và ITL, sau đó mở rộng từ đó.
Bài viết liên quan

Phần cứng
Gemma 4 áp dụng Multi-Token Prediction, tăng tốc độ suy luận lên tới 3 lần
25 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026

Công nghệ
Alienware 15 mới: Dell đang làm loãng thương hiệu cao cấp vì khủng hoảng RAM?
14 tháng 5, 2026