
Proxy-Pointer RAG: Kiến trúc so sánh tài liệu doanh nghiệp có nhận biết cấu trúc
Proxy-Pointer RAG là giải pháp AI mới giúp so sánh chính xác các tài liệu phức tạp như hợp đồng và bài báo nghiên cứu dựa trên cấu trúc ngữ nghĩa thay vì văn bản thô. Hệ thống này sử dụng kiến trúc 3 tầng và khả năng truy xuất nhận biết phân cấp để phát hiện rủi ro và sự khác biệt sâu sắc mà các công cụ truyền thống bỏ sót.

Trong kỷ nguyên số hóa, việc so sánh tài liệu là một trong những trường hợp sử dụng AI quan trọng nhất tại các doanh nghiệp, sánh ngang với các chatbot hội thoại. Các tổ chức dành hàng giờ đồng hồ để đối chiếu hợp đồng, chính sách, thông số kỹ thuật và bài báo nghiên cứu nhằm tìm ra sự khác biệt, rủi ro và các mâu thuẫn ngữ nghĩa.
Tuy nhiên, so sánh tài liệu phức tạp hơn nhiều so với việc tìm kiếm sự khác biệt văn bản truyền thống. Các công cụ hiện nay thường thất bại trong việc hiểu ý nghĩa thực sự, bởi trong các tài liệu doanh nghiệp, nội dung thường không nằm trong các đoạn văn tách biệt mà được nhúng trong các phần, cấu trúc phân cấp và mối quan hệ phức tạp trải dài hàng trăm trang.
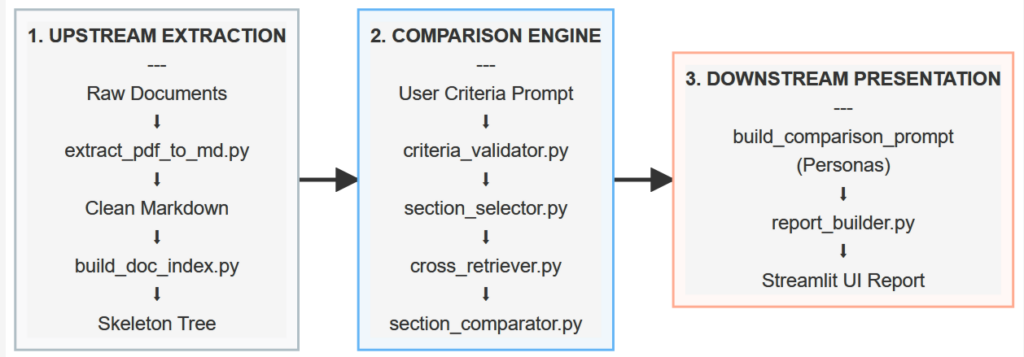 Kiến trúc tổng quan của Proxy-Pointer
Kiến trúc tổng quan của Proxy-Pointer
Thách thức trong việc so sánh tài liệu doanh nghiệp
Một vấn đề khó khăn hơn nữa là ý nghĩa trong các tài liệu doanh nghiệp thường không nằm trong các đoạn văn cô lập. Nó được nhúng trong các phần, hệ thống phân cấp, nhóm điều khoản và các mối quan hệ. Ví dụ, một hợp đồng tín dụng có thể định nghĩa giới hạn tài sản thế chấp ở một mục, các ngoại lệ cho chúng ở vài trang sau, và mô tả quyền thực thi trong một điều khoản hoàn toàn khác.
Nếu so sánh hợp đồng này với một hợp đồng khác dựa trên tiêu chí như "cấu trúc tài sản thế chấp, lợi ích bảo đảm và yêu cầu quyền cầm cố", hệ thống phải xác định, truy xuất và tổng hợp tất cả các phần phân tán này lại với nhau trước khi có thể thực hiện bất kỳ sự so sánh ý nghĩa nào.
Giải pháp Proxy-Pointer RAG
Kiến trúc Proxy-Pointer ra đời để giải quyết vấn đề này. Với khả năng nhận biết cấu trúc và quy trình truy xuất chi phí thấp nhưng vẫn bảo toàn thứ bậc của tài liệu, Proxy-Pointer lý tưởng cho việc so sánh sâu sắc. Nó sử dụng kết hợp giữa các vector nhúng phân cấp (hierarchical breadcrumb embeddings) và bộ xếp hạng lại (re-ranker) LLM nhẹ nhàng để trích xuất chính xác các vùng có ý nghĩa tương đồng giữa các tài liệu trước khi bắt đầu suy luận so sánh.
Hệ thống sử dụng mô hình LLM gemini-3-flash cùng với gemini-embedding-001 (kích thước vector: 1536) cho các vector nhúng.
Kiến trúc 3 tầng của Bộ so sánh Tài liệu
Hệ thống được chia thành ba tầng chính để đảm bảo tính linh hoạt và dễ dàng thích nghi với nhiều lĩnh vực khác nhau:
1. Lớp Trích xuất Ngược (Upstream Extraction Layer) Chuyển đổi cấu trúc tài liệu thô đầu vào thành hệ thống phân cấp chuẩn, có thể đọc được bởi máy.
extract_pdf_to_md.py: Xử lý việc nhập dữ liệu, chuyển đổi PDF thành Markdown có định dạng phân cấp.build_doc_index.py: Phân tích tiêu đề Markdown, lọc nhiễu hành chính và xây dựng bản đồ cấu trúc JSON phân cấp.
2. Động cơ So sánh Cốt lõi (Core Comparison Engine) Điều phối tìm kiếm ngữ nghĩa trên các nút tài liệu phân cấp.
criteria_validator.py: Phát hiện động loại tài liệu (ví dụ: Học thuật vs. Pháp lý) và kiểm tra tính khả thi của tiêu chí so sánh.section_selector.py: Triển khai truy xuất Proxy-Pointer Giai đoạn 1. Nó xác định và trích xuất các phần liên quan nhất của Tài liệu 1 dựa trên tiêu chí người dùng.cross_retriever.py: Triển khai truy xuất Proxy-Pointer Giai đoạn 2. Nó thực hiện tìm kiếm ngữ nghĩa có mục tiêu trong không gian vector của Tài liệu 2 bằng cách sử dụng ngữ cảnh của các phần Tài liệu 1 đã chọn.section_comparator.py: Điều phối các đánh giá từng cặp các phần khớp, chuyển chúng cho LLM để phân tích sự đồng nhất và khác biệt.
3. Lớp Trình bày Xuôi (Downstream Presentation Layer) Tùy chỉnh đầu ra phân tích cho đối tượng mục tiêu và định dạng hình ảnh trực quan cuối cùng.
report_builder.py: Hiển thị báo cáo so sánh cuối cùng song song bằng màu sắc CSS chuyên nghiệp và định dạng bố cục dễ đọc.
 Giao diện so sánh tài liệu trên Streamlit
Giao diện so sánh tài liệu trên Streamlit
Kết quả thực tế: Hợp đồng tín dụng và Bài báo nghiên cứu
Tác giả đã kiểm nghiệm hệ thống trên các hợp đồng tín dụng phức tạp (Emerson và Texas Roadhouse) và các bài báo nghiên cứu học thuật (VectorFusion và VectorPainter).
Đối với hợp đồng tín dụng: Proxy-Pointer không chỉ khớp các điều khoản theo từ khóa hay các đoạn văn không hoàn chỉnh, mà nhìn nhận chúng dưới góc độ của một chuyên gia phân tích pháp lý. Nó xác định được các hậu quả kinh tế và pháp lý ẩn giấu dưới ngôn ngữ bề mặt — chẳng hạn như rủi ro cấp dưới cấu trúc bên trong một cam kết không thế chấp thứ cấp, hay việc bảo toàn giá trị doanh nghiệp bên trong các điều khoản xử lý.
Kết quả phân tích vẫn nhất quán về hướng đi khi các tài liệu bị hoán đổi vị trí. Nó không neo mình vào tài liệu đầu tiên mà đánh giá lại thỏa thuận từ góc nhìn của tài liệu còn lại, xác định đúng thỏa thuận nào đặt nhiều hạn chế hơn cho người vay, và thỏa thuận nào yêu cầu công ty tiết lộ nhiều thông tin hơn.
Đối với bài báo nghiên cứu: Khi so sánh các bài báo về đồ họa vector, hệ thống đã thực hiện một so sánh chuyên sâu theo lĩnh vực, vượt ra ngoài sự khớp kiến trúc bề mặt để xác định triết lý thiết kế sâu sắc đằng sau cả hai bài báo. Nó nhận diện chính xác rằng VectorFusion coi việc tạo SVG là một bài toán tối ưu hóa động, trong khi VectorPainter tiếp cận nó như một bài toán tổng hợp được hướng dẫn bởi phong cách.
 Kết quả phân tích chi tiết giữa các tài liệu
Kết quả phân tích chi tiết giữa các tài liệu
Kết luận
Việc so sánh tài liệu bằng phương pháp "Chunk-Embed-Match" (chia nhỏ - nhúng - khớp) truyền thống khó có thể mang lại kết quả tốt cho các tài liệu doanh nghiệp phức tạp. Để so sánh và phân tích hiệu quả, các phần, định nghĩa, ngoại lệ và mối quan hệ cấu trúc cần được trích xuất cùng nhau để có thể hiểu được khi đọc chung.
Proxy-Pointer với quy trình truy xuất hai bước chính xác là lý tưởng cho nhiệm vụ này. Như kết quả đã chỉ ra, ngay cả với một mô hình LLM ngân sách thấp như gemini-flash, người dùng có thể so sánh các thỏa thuận hoặc bài báo nghiên cứu sao cho có thể bảo toàn ý định và sự đánh đổi tiềm ẩn ẩn giấu qua các phần cấu trúc khác biệt.
Kiến trúc 3 tầng của Bộ so sánh Tài liệu có thể mở rộng sang các lĩnh vực khác mà không cần thay đổi động cơ so sánh cốt lõi. Điều này cho phép truy xuất nhận biết cấu trúc tổng quát hóa tốt hơn so với một công cụ tùy chỉnh chỉ hoạt động cho một loại tài liệu cụ thể.
Toàn bộ mã nguồn của Proxy-Pointer đã được mở theo giấy phép MIT và có thể được truy cập tại kho lưu trữ GitHub của dự án.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026