RAG bị ảo giác: Tôi đã xây dựng một lớp tự sửa chữa khắc phục lỗi trong thời gian thực
Hệ thống RAG thường thất bại ở khâu suy luận thay vì truy xuất dữ liệu. Bài viết này giới thiệu một lớp tự sửa chữa nhẹ nhàng bằng Python giúp phát hiện và khắc phục các ảo giác của LLM trước khi đến tay người dùng mà không cần sử dụng API bên ngoài.

RAG bị ảo giác: Tôi đã xây dựng một lớp tự sửa chữa khắc phục lỗi trong thời gian thực
Hệ thống RAG (Retrieval-Augmented Generation) của bạn không hề thất bại trong việc truy xuất tài liệu — nó thất bại ở khâu suy luận. Bài viết này sẽ chỉ ra cách tôi xây dựng một lớp tự sửa chữa (self-healing layer) nhẹ nhàng, có khả năng phát hiện và chỉnh sửa các thông tin ảo giác (hallucinations) trước khi chúng đến tay người dùng.
Khi xây dựng một trợ lý ảo dựa trên RAG cho nền tảng giáo dục công nghệ của mình, tôi nhận ra một vấn đề nghiêm trọng: quy trình truy xuất hoạt động hoàn hảo, tài liệu đúng đã được tìm thấy, nhưng mô hình ngôn ngữ lớn (LLM) vẫn tạo ra câu trả lời mâu thuẫn trực tiếp với tài liệu đó. Không có lỗi kỹ thuật, không có sự cố hệ thống, chỉ là một câu trả lời sai lệch nhưng đầy tự tin.
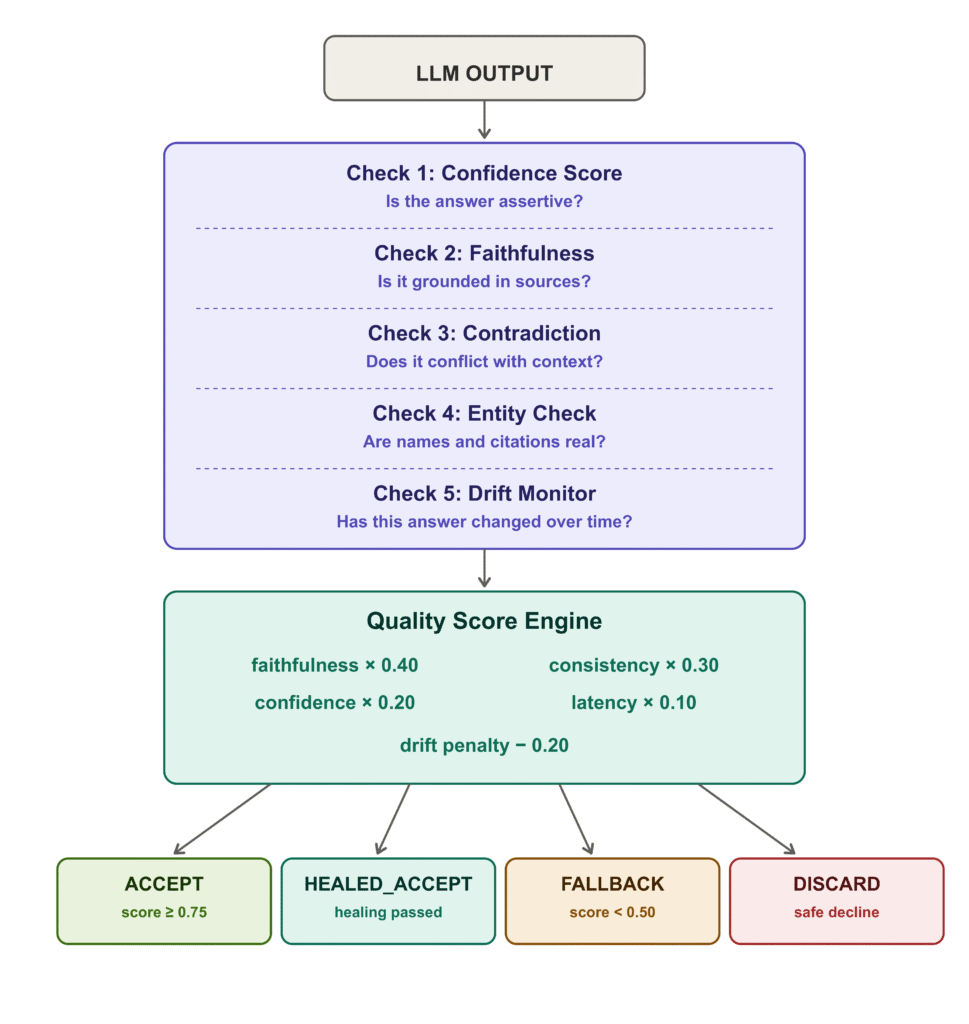 Kiến trúc hệ thống phát hiện và sửa chữa ảo giác
Kiến trúc hệ thống phát hiện và sửa chữa ảo giác
Đây không phải là một trường hợp hiếm gặp, mà là một thuộc tính cấu trúc của cách RAG hoạt động. Mô hình đọc đúng tài liệu nhưng vẫn tạo ra nội dung khác biệt do sự trôi dạt của cơ chế chú ý (attention drift), thiên kiến huấn luyện hoặc các tín hiệu xung đột trong ngữ cảnh. Điều nguy hiểm hơn so với ảo giác thông thường là người dùng có mọi lý do để tin tưởng câu trả lời này, vì hệ thống dường như đã tham chiếu đúng nguồn.
Năm mẫu hình thất bại phổ biến nhất mà tôi đã xác định được bao gồm: mâu thuẫn về số liệu, trích dẫn giả, đảo ngược phủ định, sự trôi dạt của câu trả lời (answer drift) và các phản hồi tự tin nhưng không có cơ sở (confident-but-ungrounded).
Kiến trúc: Phát hiện, chấm điểm, sửa chữa và định tuyến
Thay vì chỉ cảnh báo lỗi, hệ thống mà tôi xây dựng có khả năng tự động khắc phục. Quy trình hoạt động theo trình tự: retrieve(query) -> generate(query, chunks) -> detector.inspect(...) -> QualityScore.compute(...) -> healer.heal(...) -> ACCEPT / HEALED_ACCEPT / FALLBACK / DISCARD.
Mục tiêu thiết kế là chạy hệ thống này trong một yêu cầu FastAPI thông thường mà không làm tăng độ trễ (latency). Không có cuộc gọi API bên ngoài, không sử dụng mô hình nhúng (embeddings) hay LLM làm giám khảo. Toàn bộ quá trình inspect() chạy dưới 50ms với spaCy và dưới 10ms với phương án dự phòng regex.
Cơ chế phát hiện chi tiết
Hệ thống sử dụng năm lớp kiểm tra chính để đảm bảo tính chính xác:
- Chấm điểm độ tự tin (Confidence Scoring): Thay vì sử dụng logprobs khó tiếp cận, tôi sử dụng phương pháp đếm từ đơn giản để tìm các từ ngữ khẳng định quá mức như "chắc chắn" (definitely) so với các tín hiệu không chắc chắn. Nếu độ tự tin vượt quá 0.75 nhưng tính trung thực (faithfulness) dưới 0.50, hệ thống sẽ cảnh báo.
- Chấm điểm tính trung thực (Faithfulness Scoring): Chia câu trả lời thành các mệnh đề sự kiện và kiểm tra xem bao nhiêu phần trăm từ khóa quan trọng xuất hiện trong ngữ cảnh nguồn. Một mệnh đề được coi là có cơ sở nếu ít nhất 40% từ khóa của nó xuất hiện trong tài liệu.
- Phát hiện mâu thuẫn (Contradiction Detection): Tập trung vào ba kiểu mâu thuẫn chính: số liệu (ví dụ: ngữ cảnh nói 14 ngày, câu trả lời nói 30 ngày), phủ định (ví dụ: ngữ cảnh "không hỗ trợ", câu trả lời "hỗ trợ") và thời gian.
- Giám sát sự trôi dạt (Answer Drift Monitor): Sử dụng SQLite để lưu trữ "vân tay" của các câu trả lời trước đó (số, từ khóa chính, độ dài). Nếu một câu hỏi giống nhau nhận được câu trả lời quá khác biệt so với lịch sử, hệ thống sẽ phát hiện ra sự suy giảm chất lượng của pipeline.
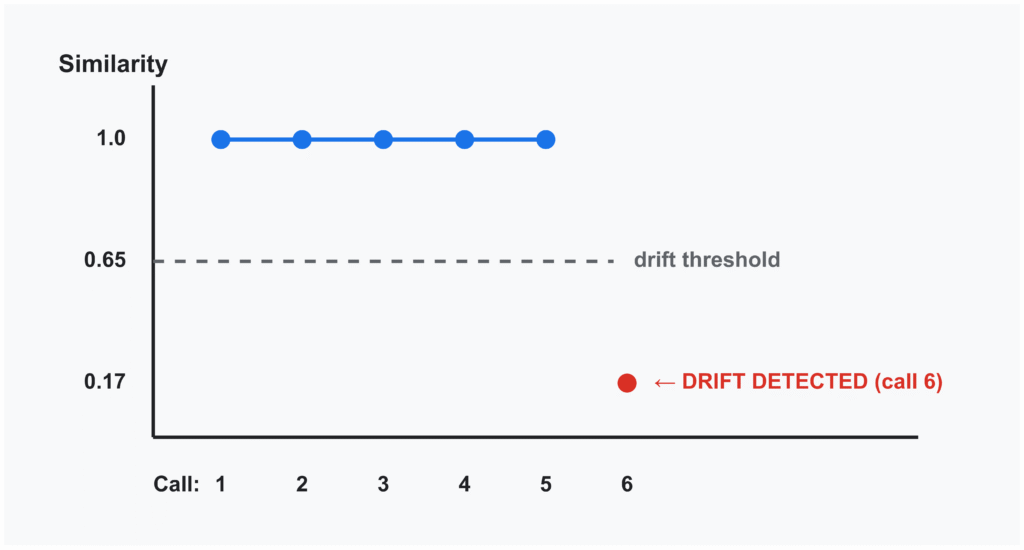 Biểu đồ giám sát sự trôi dạt câu trả lời
Biểu đồ giám sát sự trôi dạt câu trả lời
Lớp tự sửa chữa (Self-Healing Layer)
Khi phát hiện lỗi, HallucinationHealer sẽ áp dụng một trong ba chiến lược sửa chữa xác định và sau đó kiểm tra lại kết quả.
Chiến lược A: vá mâu thuẫn (Contradiction patch) Nếu câu trả lời chứa số sai, hệ thống sẽ thay thế nó bằng số đúng từ ngữ cảnh. Điều này đặc biệt phức tạp với các chu kỳ thanh toán (ví dụ: chuyển từ "tháng" sang "năm") để đảm bảo ngữ pháp vẫn đúng đắn.
Chiến lược B: làm sạch thực thể (Entity scrub) Nếu câu trả lời chứa các thực thể ảo giác như tên người hoặc trích dẫn giấy tờ giả, hệ thống sẽ xóa các câu chứa chúng. Một ghi chú minh bạch sẽ được thêm vào để người dùng biết nội dung đã được cắt bỏ.
Chiến lược C: viết lại dựa trên ngữ cảnh (Grounding rewrite) Khi tính trung thực quá thấp (dưới 0.30), hệ thống sẽ xây dựng lại câu trả lời từ đầu bằng cách sử dụng các câu ngữ cảnh có xếp hạng cao nhất. Tiền tố của câu trả lời sẽ được chọn linh hoạt dựa trên nội dung thực tế (ví dụ: "Theo dữ liệu được cung cấp:", "Theo tài liệu nguồn:").
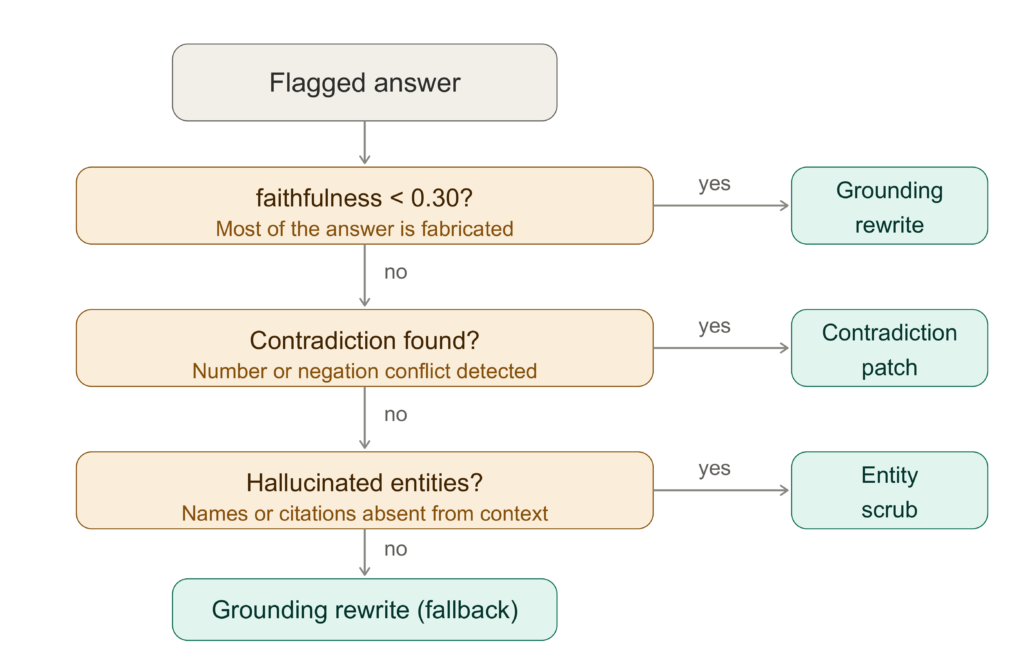 Sơ đồ chiến lược sửa chữa lỗi
Sơ đồ chiến lược sửa chữa lỗi
Hiệu suất và kiểm thử
Hệ thống đã được kiểm chứng nghiêm ngặt với 70 bài kiểm thử (test cases), bao phủ mọi chế độ thất bại đã được đặt tên. Về hiệu suất, trên Python 3.12 và chỉ sử dụng CPU:
- Chấm điểm độ tự tin: < 1ms
- Chấm điểm tính trung thực: ~2ms
- Phát hiện mâu thuẫn: ~1ms
- Phát hiện thực thể (spaCy): ~45ms
- Quá trình
inspect()đầy đủ (spaCy): < 50ms
Nếu cần độ trễ cuối cùng dưới 10ms, bạn có thể chuyển sang chế độ dự phòng regex NER bằng cách thay đổi cấu hình một dòng.
Kết luận
Mô hình sẽ ảo giác, và quy trình truy xuất sẽ thất bại. Vấn đề không phải là liệu điều đó có xảy ra hay không, mà là bạn có bắt kịp nó trước khi người dùng của mình phát hiện ra hay không. Với 70 bài kiểm thử và kiến trúc nhẹ nhàng không cần phụ thuộc bên ngoài, lớp tự sửa chữa này cung cấp một giải pháp thực tế để nâng cao độ tin cậy của các hệ thống RAG trong môi trường sản xuất.
Toàn bộ mã nguồn đã được công khai trên GitHub để cộng đồng phát triển và tùy chỉnh theo nhu cầu cụ thể của từng lĩnh vực, từ pháp lý đến y tế hay tài chính.