
RAG bị "mù" thời gian: Cách tôi xây dựng Temporal Layer để khắc phục trong môi trường sản xuất
Các hệ thống RAG truyền thống thường ưu tiên độ tương đồng ngữ nghĩa mà bỏ qua yếu tố thời gian, dẫn đến việc cung cấp thông tin lỗi thời. Bài viết này chia sẻ về việc xây dựng một "Temporal Layer" (Lớp thời gian) để lọc dữ liệu hết hạn và ưu tiên thông tin mới nhất, đảm bảo AI đưa ra câu trả lời chính xác và phù hợp với bối cảnh hiện tại.

RAG bị "mù" thời gian: Cách tôi xây dựng Temporal Layer để khắc phục trong môi trường sản xuất
Ba tuần sau khi bắt đầu thử nghiệm, một người học đã nhắn tin cho tôi về một câu trả lời sai lệch. Cô ấy hỏi về một khái niệm trong hướng dẫn Generative AI của tôi. Câu trả lời trông có vẻ ổn, nhưng thực tế thì không. Tôi đã viết lại nội dung đó hai tháng trước, nhưng hệ thống RAG của tôi lại kéo về phiên bản từ sáu tháng trước — không sai hẳn, nhưng sai đủ để gây hiểu lầm.
Cô ấy nghĩ mình đã hiểu sai. Nhưng không, chính hệ thống của tôi đang dạy cô ấy từ những bài học mà tôi đã thay thế.
Tôi đang xây dựng một trợ lý hỗ trợ chạy bằng RAG cho nền tảng giáo dục công nghệ của mình — biến thư viện nội dung thành một hệ thống tạo câu trả lời trực tiếp từ các bài viết. Kiến trúc ban đầu khá đơn giản, nhưng thách thức thực sự bắt đầu khi người dùng thực tế truy cập vào hệ thống trực tiếp.
Khi xem xét nhật ký truy xuất (retrieval logs), tôi nhận ra chính xác vấn đề. Cả hai phiên bản tài liệu đều nằm trong kho vector (vector store). Phiên bản cũ xếp hạng đầu tiên vì có nhiều khớp từ (token) hơn và điểm tương đồng cosine cao hơn. Phiên bản cập nhật xếp thứ hai, thậm chí thứ ba.
Tôi kỳ vọng tài liệu mới hơn sẽ tự động thắng thế. Nhưng đó không phải là cách hoạt động của độ tương đồng cosine. Hệ thống đang làm đúng những gì được thiết kế, và điều đó lại trở thành vấn đề.
 Kiến trúc Temporal Layer Pipeline
Kiến trúc Temporal Layer Pipeline
Tại sao Vector Search không có khái niệm về thời gian
Pipeline RAG tiêu chuẩn nhúng tài liệu, nhúng truy vấn, tìm các kết quả khớp nhất và gửi chúng cho mô hình. Điều này hoạt động tốt nếu thông tin của bạn không bao giờ thay đổi. Nhưng nếu bạn liên tục xuất bản các hướng dẫn mới và viết lại các hướng dẫn cũ, hệ thống sẽ âm thầm thất bại.
Kho vector chỉ biết góc giữa các vector. Nó không biết tài liệu nào sáu tháng tuổi và tài liệu nào tôi xuất bản tuần trước. Các giải pháp thường thấy như xóa tài liệu cũ hoặc thêm bộ lọc metadata chỉ giúp ích trong khoảng hai tuần. Sau đó, tôi cập nhật nội dung một lần nữa và vấn đề quay trở lại. Một tài liệu bị phạt 20% vẫn có thể xếp hạng đầu tiên nếu độ trùng khớp từ đủ mạnh.
Tôi nhận ra đây không phải là một vấn đề lớn, mà là ba vấn đề riêng biệt, và mỗi cái cần một giải pháp khác nhau:
- Hết hạn (Expiration): Một sự kiện giờ đây là sai. Hiển thị chúng sau ngày hết hạn không phải là vấn đề về tính mới, mà là sự gian dối. Bạn không thể chỉ giảm hạng chúng, phải loại bỏ hoàn toàn trước khi mô hình nhìn thấy.
- Tính thời điểm (Temporality): Sự thật chỉ đúng ngay lúc này. Thông tin về sự cố ngừng dịch vụ hoặc thay đổi chính sách trong 48 giờ không chỉ là ngữ cảnh thêm, mà là tài liệu quan trọng nhất trong khi cửa sổ thời gian đó mở.
- Phiên bản (Versioning): Một sự thật đã bị thay thế. Đây là vấn đề lớn nhất của tôi. Khi tôi cập nhật tài liệu, cả hai phiên bản đều nằm trong kho vector. Phiên bản cũ thắng vì có nhiều từ khớp hơn. Giải pháp ở đây không phải xóa hay tăng cường, mà là để thời gian xử lý.
Giải pháp: Xây dựng Temporal Layer
Tôi đã xây dựng một "Temporal Layer" (Lớp thời gian) nằm giữa bộ truy xuất (retriever) và LLM. Bộ truy xuất vẫn giữ nguyên, kéo 20 ứng viên hàng đầu theo độ tương đồng cosine. Temporal Layer sẽ nhận các ứng viên đó, phân loại lại và xếp hạng lại (rerank) trước khi bất kỳ tài liệu nào đến được mô hình.
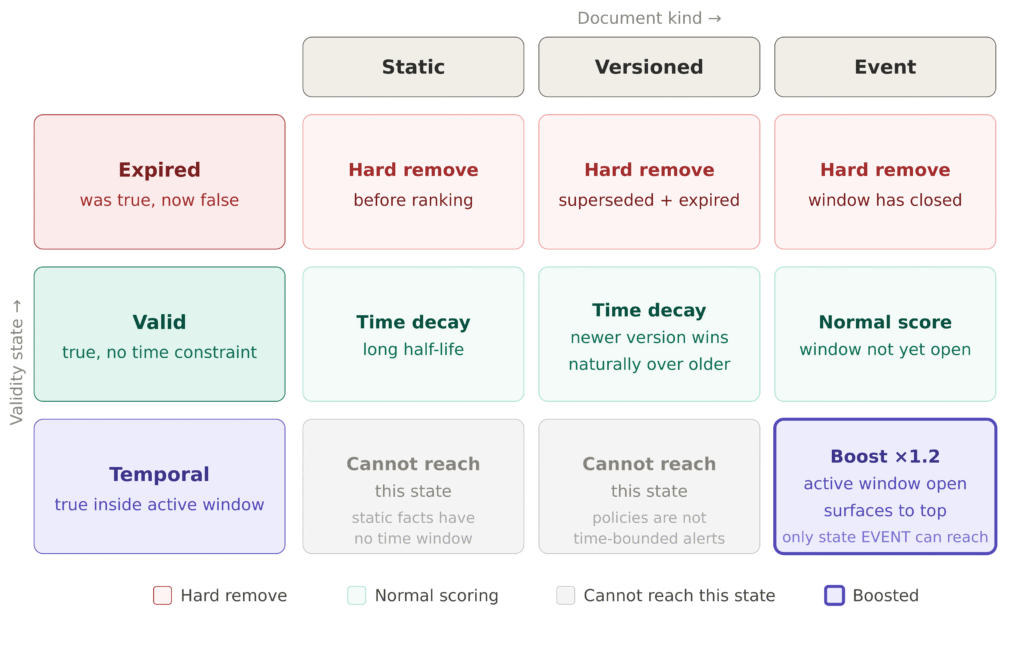
Thiết kế cốt lõi dựa trên hai trục phân loại độc lập:
Trục 1: Trạng thái hợp lệ (Validity State)
- EXPIRED (Hết hạn): Đã từng đúng, giờ không còn. Loại bỏ cứng trước khi xếp hạng.
- VALID (Hợp lệ): Đúng mà không có ràng buộc thời gian. Chấm điểm bình thường.
- TEMPORAL (Thời điểm): Đúng trong một cửa sổ thời gian đang hoạt động. Tăng cường (boost).
Hầu hết các hệ thống chỉ chạy trên hai trạng thái: hợp lệ và hết hạn. Điều tôi thiếu là trạng thái TEMPORAL riêng biệt cho các tín hiệu bị ràng buộc thời gian. Thông báo bảo trì không giống như một quy tắc vĩnh viễn. Nó khẩn cấp và cần nổi lên trên cùng. Khi bảo trì kết thúc, thông báo chuyển sang EXPIRED và bị loại bỏ.
Trục 2: Loại tài liệu (Document Kind)
- STATIC (Tĩnh): Sự thật không phụ thuộc thời gian (định nghĩa, toán học, tài liệu tham khảo).
- VERSIONED (Có phiên bản): Thay thế bởi thông tin mới hơn (chính sách, hướng dẫn, thông số kỹ thuật).
- EVENT (Sự kiện): Chỉ đúng trong một cửa sổ thời gian (thông báo, sự cố).
 Hệ thống phân loại hai trục
Hệ thống phân loại hai trục
Sự phân biệt này rất quan trọng. Nếu không có nó, phiên bản đầu tiên của tôi đã phân loại chính sách công ty mới là một sự kiện tạm thời và đẩy nó lên đầu mọi tìm kiếm. Cập nhật chính sách hoạt động khác với thông báo sự cố trực tiếp, ngay cả khi cả hai đều mới. Nó nên được xếp hạng bình thường và mất điểm chậm theo thời gian.
Công thức chấm điểm
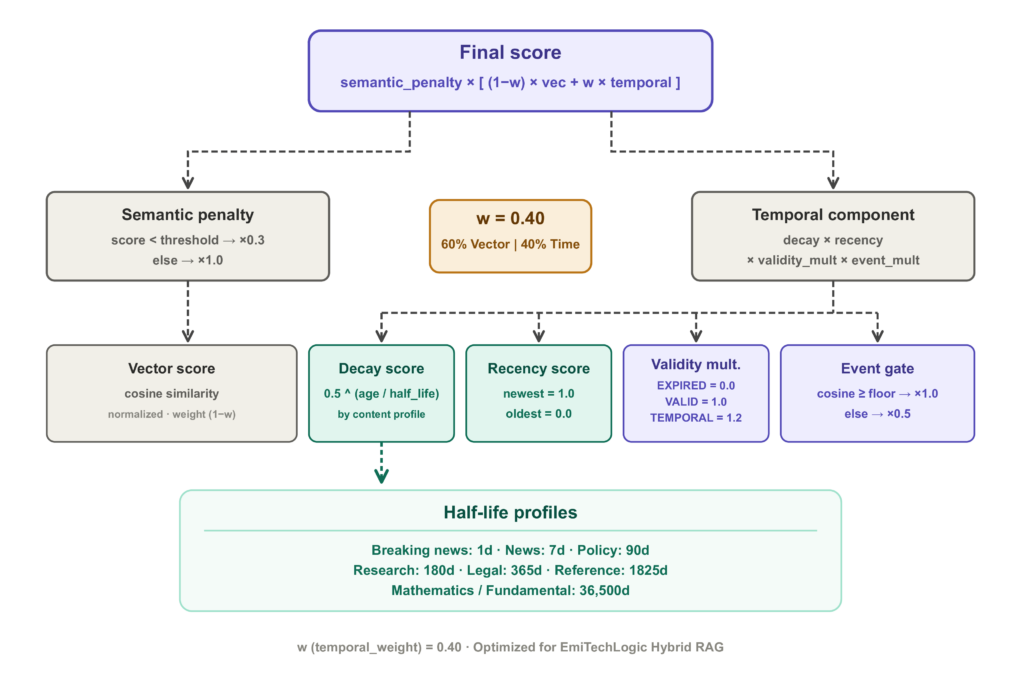
Điểm số cuối cùng kết hợp độ tương đồng vector với các tín hiệu thời gian:
final_score = semantic_penalty × [(1 − w) × vector_score + w × (decay_score × recency_score × validity_multiplier × event_relevance_multiplier)]
Trong đó:
- vector_score: Độ tương đồng cosine.
- decay_score: Sự suy giảm hàm mũ dựa trên tuổi tài liệu. Ví dụ: tin tức mất giá sau 7 ngày, nhưng tài liệu pháp lý giữ nguyên trong 365 ngày.
- recency_score: So sánh tương đối trong nhóm ứng viên hiện tại. Tài liệu mới nhất có điểm cao nhất.
- validity_multiplier: EXPIRED -> 0.0, VALID -> 1.0, TEMPORAL -> 1.2.
- event_relevance_multiplier: Chỉ áp dụng cho EVENT. Nếu độ tương đồng thô thấp, tăng cường sẽ bị giảm một nửa để tránh tin tức mới nhưng không liên quan lấn át.
 Công thức chấm điểm chi tiết
Công thức chấm điểm chi tiết
Các tình huống thực tế
Hãy xem xét ví dụ về giới hạn tốc độ API:
Truy vấn: "Giới hạn tốc độ API là bao nhiêu? Tôi có bị lỗi 429 không?"
RAG ngây thơ (Naive RAG):
- [policy_v1] age=540d | EXPIRED | sim=0.447 ("Giới hạn là 100 yêu cầu mỗi phút...")
- [announcement_today] age=0d | valid | sim=0.329
Temporal RAG:
- [announcement_today] (EVENT, temporal) -> Điểm cao nhất vì đang hoạt động.
- [policy_v2] (VERSIONED, valid) -> Phiên bản mới nhất thay thế v1.
Naive RAG nói với người dùng họ sẽ gặp lỗi 429 ở mức 100 yêu cầu/phút. Giới hạn thực tế là 1.000. Temporal RAG dẫn đầu với thông báo bảo trì trực tiếp (giới hạn tốc độ hiện đang bị tạm dừng) và theo sau là chính sách hiện tại.
Không phải nội dung nào cũng suy giảm cùng tốc độ
Một điều trở nên rõ ràng nhanh chóng: một giá trị bán hủy (half-life) duy nhất không hoạt động cho tất cả các loại nội dung. Một bản cập nhật đột phá và một định nghĩa toán học già đi rất khác nhau.
- breaking_news: half_life=1 ngày
- news: half_life=7 ngày
- policy: half_life=90 ngày
- mathematics: half_life=36500 ngày (gần như vĩnh cửu)
Đối với tin tức nóng, tính mới là yếu tố chính. Đối với một chứng minh toán học, tuổi tác không quan trọng — một định lý từ 70 năm trước vẫn hợp lệ như định lý tuần trước.
Kết luận
Vấn đề không phải là hệ thống RAG truy xuất tài liệu sai — mà là chúng không có khái niệm về việc tài liệu đó đúng khi nào, chỉ biết nó tương đồng với truy vấn như thế nào.
Hai trục đã thúc đẩy toàn bộ thiết kế này — trạng thái hợp lệ và loại tài liệu. Nếu thiếu trục loại (kind), một chính sách có phiên bản với ngày hiệu lực trông giống hệt một sự kiện bị ràng buộc thời gian và bị gán nhãn sai. Hệ thống tạo ra kết quả sai vì một lý do nghe có vẻ đúng. Đó là lớp lỗi khó bắt nhất trong môi trường sản xuất.
Tương đồng đơn thuần không còn đủ nữa. Tôi cần bộ truy xuất quan tâm đến việc thông tin đó có còn hợp lệ hay không.
Bài viết liên quan
Công nghệ
Open Terminal: Ứng dụng phong cách Bloomberg giúp dân đầu tư cá nhân tiếp cận dữ liệu tài chính chuyên sâu
04 tháng 6, 2026

Phần mềm
Triển khai mảng động trong C: Không cần Struct, không lưu trữ dung lượng
13 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026