
RAG không phải là Machine Learning: Tại sao bộ công cụ ML đang giải quyết sai vấn đề?
RAG thường bị nhầm lẫn là một bài toán Machine Learning, khiến các đội ngũ lãng phí tháng trời tinh chỉnh siêu tham số mà không giải quyết được gốc rễ vấn đề. Bài viết này phân tích lý do tại sao RAG thực chất là bài toán kỹ thuật về tìm kiếm và xử lý tài liệu, đòi hỏi tư duy và công cụ khác biệt hoàn toàn so với việc huấn luyện mô hình.

RAG không phải là Machine Learning: Tại sao bộ công cụ ML đang giải quyết sai vấn đề?
Một đội ngũ phát triển đã dành sáu tháng để tinh chỉnh (fine-tune) pipeline RAG của họ. Họ chạy năm đợt quét tham số với Optuna, thêm một bộ xếp hạng lại (reranker) tùy chỉnh, và thậm chí tinh chỉnh mô hình nhúng (embedding model) trên dữ liệu riêng. Tuy nhiên, độ chính xác trong môi trường sản xuất không hề tăng lên. Những người dùng thử nghiệm vẫn phàn nàn về những câu trả lời sai lầm giống nhau. Sau sáu tháng, họ mới phát hiện ra lỗi thực sự nằm ở trình phân tích cú pháp (parser).
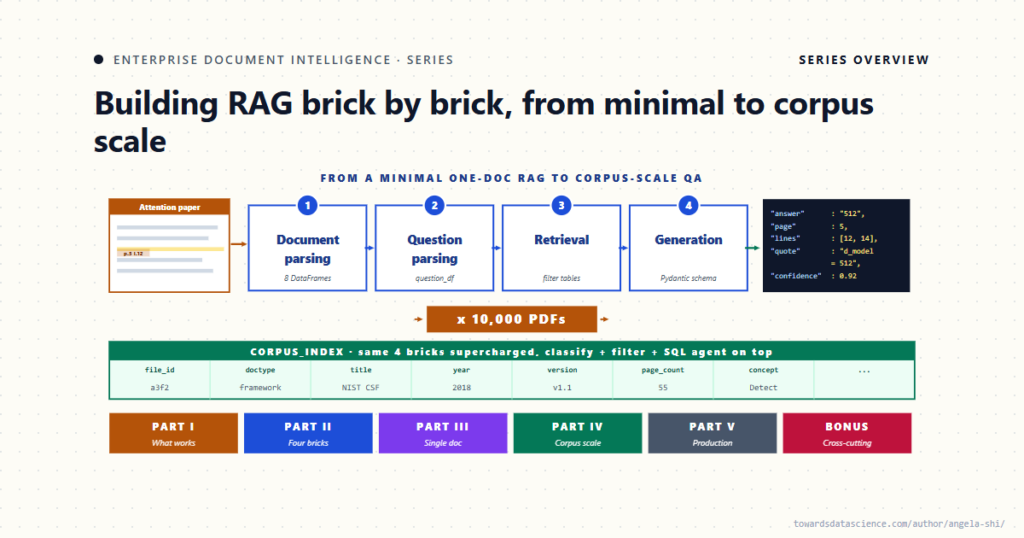 Tổng quan về Trí tuệ Tài liệu Doanh nghiệp
Tổng quan về Trí tuệ Tài liệu Doanh nghiệp
Đội ngũ này đã bị lạc lối, không phải là bị tắc nghẽn. RAG không phải là Machine Learning, và bộ công cụ ML đang giải quyết sai vấn đề. Đây là quan niệm sai lầm tốn kém nhất trong các dự án RAG doanh nghiệp hiện nay. Nó gây lãng phí hàng tháng công sức, đặt sai người vào sai nhiệm vụ và làm xói mòn niềm tin vào hệ thống một cách âm thầm.
RAG trông rất giống Machine Learning, khiến cho bộ công cụ ML dường như là bước tiếp theo tự nhiên. Những bản năng như tối ưu hóa siêu tham số, tập dữ liệu đánh giá, hay các khung giải thích (explainability frameworks) không sai khi đứng riêng lẻ, nhưng chúng được nhập khẩu từ sai lĩnh vực. Các phương pháp hoạt động tốt để huấn luyện mô hình không hiệu quả khi lắp đặt các hệ thống tìm kiếm.
Hai vấn đề hoàn toàn khác biệt
Machine Learning giải quyết các vấn đề mà câu trả lời đúng là chưa biết và cần được dự đoán. Khách hàng này có sẽ rời bỏ dịch vụ không? Giao dịch này có phải là lừa đảo không? Đây là những vấn đề bạn không biết câu trả lời trước, đó là lý do bạn cần huấn luyện một mô hình. Hiệu suất được đo lường theo tổng thể trên hàng nghìn trường hợp kiểm tra, vì các dự đoán riêng lẻ có thể sai nhưng mô hình vẫn hữu ích về tổng thể.
Ngược lại, RAG giải quyết một vấn đề khác. Câu trả lời cho câu hỏi "ngày có hiệu lực của hợp đồng này là khi nào?" đã được viết rõ ở trang đầu tiên, hoặc nó không tồn tại ở đâu cả. Không có gì để dự đoán cả. Hệ thống要么 tìm thấy câu trả lời và báo cáo trung thực,要么 thất bại và nên nói rằng không tìm thấy.
Sự khác biệt này thay đổi công cụ bạn sẽ sử dụng khi hệ thống gặp sự cố. Trong ML, "mô hình sai 8% trường hợp" là một đặc điểm của hệ thống (nhiễu thống kê). Trong RAG, "hệ thống trả lời sai 8% thời gian" là một lỗi (bug). Mỗi trường hợp sai trong số đó đều có một nguyên nhân cụ thể: truy xuất sai đoạn văn, mô hình diễn giải sai, hoặc bịa ra thông tin. Chúng không phải là nhiễu thống kê để tối ưu hóa trung bình, mà là các lỗi có thể sửa chữa riêng lẻ.
Ba lập luận ML không áp dụng được cho RAG
Ba phương pháp ML thường được mặc định đưa vào các dự án RAG là: tối ưu hóa siêu tham số, tập dữ liệu đánh giá với chia train/test, và giải thích tính năng (feature-attribution). Mỗi cái đều hợp lý trong ML, nhưng đều bắn đạn sai mục tiêu ở đây.
1. Vấn đề về siêu tham số (Hyperparameter)
Cách tiếp cận phổ biến là coi kích thước đoạn văn (chunk size), độ chồng lấn, top-k là các siêu tham số và tối ưu hóa chúng bằng Optuna. Tuy nhiên, trong RAG không có quá trình "học". Kích thước chunk không kiểm soát cách một thứ học hỏi, nó kiểm soát cách một hàm chia văn bản.
 Sự khác biệt trong tiếp cận RAG và ML
Sự khác biệt trong tiếp cận RAG và ML
Thay vì tối ưu hóa số liệu, cách tiếp cận đúng là quyết định cấu trúc cách chia đoạn văn. Chia theo mục lục? Chia theo đoạn văn? Hay theo loại câu hỏi? Không một kích thước chunk nào có thể phục vụ mọi loại câu hỏi. Câu hỏi "ngày hiệu lực là gì?" cần một đoạn nhỏ để xác định chính xác một dòng. Câu hỏi "những điều loại trừ là gì?" có thể cần một đoạn lớn để nắm bắt toàn bộ một phần. Câu trả lời không nằm ở việc tinh chỉnh số học, mà ở việc định tuyến (routing) các loại câu hỏi khác nhau đến các chiến lược truy xuất khác nhau.
2. Vấn đề về tập dữ liệu đánh giá
Trong ML, tập đánh giá cho bạn biết mô hình đã khái quát hóa (generalize) từ dữ liệu huấn luyện hay chưa. Trong RAG, không có gì để khái quát hóa. Hệ thống không thay đổi giữa các truy vấn. Việc đánh giá trong RAG thực chất đo lường ba thứ: Kho dữ liệu có chứa câu trả lời không? Trình truy xuất có tìm thấy đoạn đúng không? Và trình tạo có trung thành với đoạn đó không?
Một chỉ số "độ chính xác" tổng hợp 75% có thể che giấu thảm họa. Ví dụ, 75% đó có thể đến từ việc kho dữ liệu thiếu 25% chủ đề, hoặc trình truy xuất bỏ sót đoạn đúng 25% thời gian. Bạn cần phân tích chỉ số theo từng loại ý định câu hỏi (intent), chứ không chỉ nhìn vào con số trung bình.
3. Vấn đề về tính giải thích (Explainability)
ML có các công cụ như SHAP hay LIME để giải thích dự đoán. Nhưng RAG có tính giải thích sẵn có theo thiết kế. Hệ thống đã truy xuất các đoạn văn cụ thể từ các nguồn cụ thể. Đó chính là lời giải thích. Người dùng không cần bản đồ nhiệt (heatmap) trọng số chú ý; họ cần dẫn chứng (citation). "Tôi đã nhìn vào trang 12, 47 và 89. Đây là văn bản gốc tôi dùng." Đó là tất cả những gì cần thiết.
Điều gì thay đổi khi nhìn nhận RAG đúng cách
Khi bạn ngừng coi RAG là ML, ba thứ sẽ thay đổi: công cụ, chỉ số và con người.
Công cụ thay đổi: Bạn không cần PyTorch hay cụm huấn luyện. Bạn cần một trình phân tích cú pháp (parser) tốt, một trình truy xuất linh hoạt, kỹ thuật prompt (prompt engineering) cẩn thận và ghi nhật ký có cấu trúc.
Chỉ số thay đổi: Độ chính xác tổng thể nhường chỗ cho các chỉ số theo chế độ lỗi: tỷ lệ truy xuất (retrieval recall), tính trung thành của câu trả lời, và tỷ lệ "không tìm thấy".
Con người thay đổi: Kỹ năng quan trọng nhất là kỹ thuật phần mềm, chuyên môn lĩnh vực (domain expertise) và trực giác về truy xuất thông tin (Information Retrieval), chứ không chỉ là chuyên gia ML. Một đội ngũ gồm các nhà nghiên cứu ML mà không có chuyên gia lĩnh vực sẽ tạo ra một hệ thống được tinh chỉnh đẹp mắt nhưng sai trọng tâm.
Hai phần, hai chế độ lỗi
Một cách hữu ích để hình dung RAG là: một công cụ tìm kiếm cộng với một LLM viết câu trả lời.
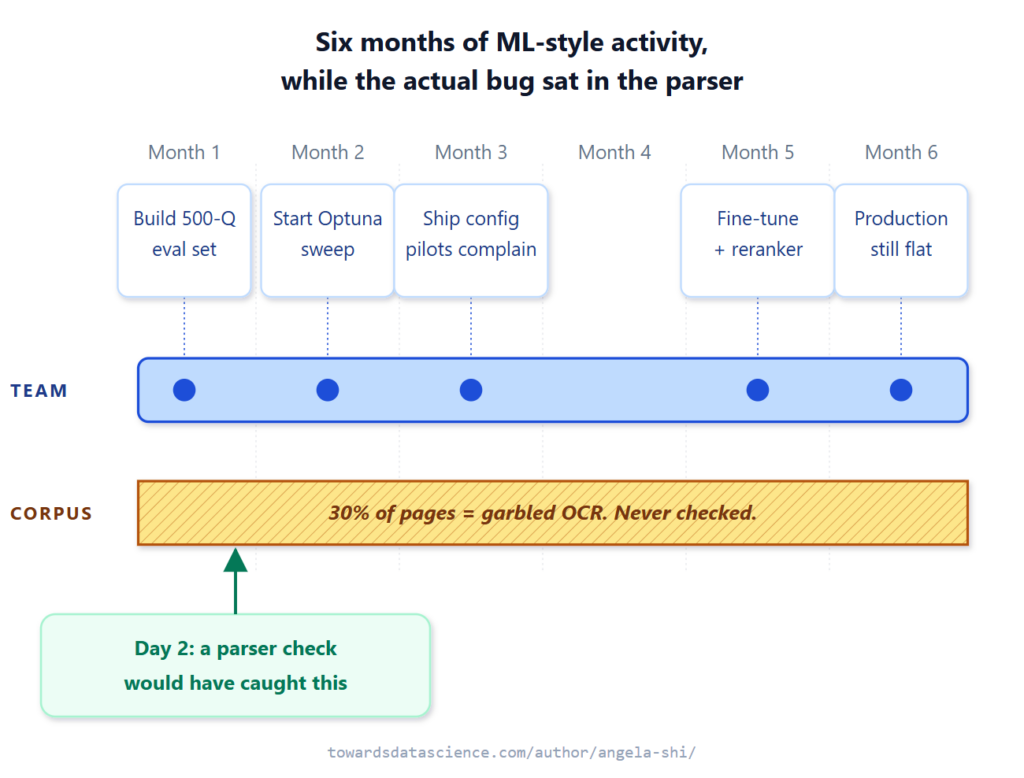 Chẩn đoán lỗi trong hệ thống RAG
Chẩn đoán lỗi trong hệ thống RAG
- Công cụ tìm kiếm (Search Engine): Truy xuất đoạn văn. Nếu câu trả lời không nằm trong các đoạn được truy xuất, lỗi nằm ở phía thượng nguồn (parser, từ khóa, hoặc tài liệu không có trong kho).
- LLM: Viết câu trả lời từ đoạn văn đó. Nếu đoạn đúng đã được truy xuất nhưng câu trả lời sai, lỗi nằm ở phía hạ nguồn (prompt, schema, hoặc lớp xác thực).
Ví dụ, một người dùng hỏi "Mô hình Transformer cơ bản sử dụng bao nhiêu đầu (heads)?". Hệ thống trả lời "16". Khi kiểm tra trace (dấu vết), ta thấy trình truy xuất đã trả về trang 8 (mô hình lớn có 16 heads) thay vì trang 5 (mô hình cơ bản có 8 heads). Lỗi ở đây là truy xuất, không phải tạo. Việc sửa lỗi chỉ cần 5 dòng Python để cải thiện cách xếp hạng từ khóa, không cần fine-tune mô hình.
Kết luận
RAG trông giống Machine Learning, nhưng sự tương đồng chỉ là hời hợt. Câu trả lời đã nằm trong tài liệu hoặc không. Không có khái quát hóa thống kê, không có đường cong học hỏi. Khung nhìn đúng là lắp ráp công cụ tìm kiếm: một công cụ tìm kiếm cộng với một LLM, hai phần bạn có thể sửa chữa độc lập.
Chi phí của việc giữ khung nhìn ML không chỉ là về trí tuệ, mà là sáu tháng công sức lãng phí vào sai vấn đề. Khi một hệ thống RAG gặp khó khăn, bản năng đầu tiên không nên là "hãy tinh chỉnh", mà là "hãy truy xem điều gì xảy ra với một truy vấn thất bại, từ đầu đến cuối, và tìm ra mắt xích bị đứt".
Bài viết liên quan

Phần mềm
Shii haa: Ứng dụng biến micro điện thoại thành cảm biến phát hiện nhịp thở
02 tháng 6, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026

Phần mềm
AI Không Thể Đọc File Của Tôi - Tôi Đã Tự Xây Một MCP Server "Zero-Dependency"
05 tháng 6, 2026